Simulating Get-Understand-Share-Connect Model using Process Mining

Adv. Sci. Technol. Eng. Syst. J. 6(1), 1040–1048 (2021);
 DOI: 10.25046/aj0601115
DOI: 10.25046/aj0601115
This paper presents the method of simulating the personal knowledge management (PKM) processes, based on Get-Understand-Share-Connect (GUSC) Model, using real event logs data from an online learning platform. The method used in here is process discovery and conformance, which are the process mining techniques. Having the model proven at granular level of multi-agent system, this research is found significant in proving that PKM indeed exists in students’ online learning behavior and needs to be monitored to ensure that they are managing knowledge in a complete cycle, to support their credibility as future graduates and knowledge workers in organizations. The ideal process starts from Get, then Understand, and followed by Share and Connect, but this study proves that the sequence may vary although the original theory is construed. This depends on the way the online activities being mapped to the Get, Understand, Share and Connect processes during the data processing stage. The results from this paper include the simulation of the GUSC model as discovered from real event logs data.
1.Introduction
Due to the habit and intuitive that they possess, the digital natives, i.e. the generation that grows up with the Internet technologies, are used to independent learning and do not rely much on physical classroom learning. It is a competition of being the most knowledgeable to them, to be able to gain more knowledge and manage their personal knowledge in as many means as they can through the Internet, hence the shift from traditional classrooms to online learning environment in many universities today.
Looking at the need to ensure that learners gained the right knowledge at the right time, and being competitive and marketable graduates, it is necessary to also ensure that they could well manage their personal knowledge. With the current experience in managing classes and teaching materials online, the data is available for analysis on online learning behavior of learners using the university online learning platform. Instead of relying on questionnaire and interview surveys that highly depend on respondents’ feedback that could be bias and distorted from truth, it is a better way to approach the case of online learning behavior directly from the data source on the server.
Recent research has proven the existence of personal knowledge management (PKM) in online learning platforms, including social media and learning management system provided by universities. However, these studies were mostly done using surveys. One significant research developed an agent-based simulation to visualize the PKM processes based on those surveys. There is a gap between these two types of previous research, in which this study intends to close this gap with its findings visualized directly from the original source, which is the event logs data from the online learning server. In doing so, this research aims to achieve the following objectives:
- to discover PKM model by visualizing the process flow in online learning environment; and
- to simulate the PKM processes using real case data for further verification on conforming the model.
This paper is an extension of work originally presented in the 6th International Conference On Research & Innovation In Information Systems (ICRIIS2019), Malaysia [1].
2. Related Works
2.1. GUSC Model Simulation
As mentioned in the introduction, a recent research has developed an agent-based simulation on GUSC Model, a model that is proven in quite a number research before this. The abbreviation “GUSC” comes from the words Get, Understand, Share and Connect, which are the processes deem necessary for personal knowledge management (PKM). The GUSC Model was simplified from a handful of previous models on PKM by renowned authors since 2009 [2]-[4]. The only difference between GUSC Model and other models before this is the proven suitability of this model for intelligent agents modelling, in which the PKM processes can be developed at granular level for software agents to perform.
In lieu to the previous models, this PKM model is based on the following processes [4], [5]:
- Get or Retrieve knowledge (G): This process simulates how learners retrieve knowledge in explicit form, in which that knowledge has been converted from tacit form by the person who shared it;
- Understand or Analyze Knowledge (U): This process simulates how learners analyze the explicit knowledge that they have retrieved, and convert it to a tacit form in a way that they understand;
- Share or Publish Knowledge (S): This process demonstrates how learners share or post the knowledge that they have understood in an explicit form, so that others can gain knowledge from it;
- Connect to Knowledge Source (C): This process is about connecting learners to sources of knowledge, including materials and people, which may involve communication between the two, resulting in a transformation from tacit form of knowledge to another tacit form.
The decision of adopting GUSC Model for this research is due to its credibility in proving the existence of PKM in learning environment [6], smart classroom [7], [8] , social network [9] , and social messaging applications [10], [11]. In addition to that, prototypes have been developed to prove that GUSC Model can be used to design PKM platforms for individuals [12], and a simulation of GUSC Model in learning environment is developed to show and prove PKM processes among learners [13].
It was suggested in the recent research on GUSC simulation [14] to relook into the simulation itself by improving the way the measurement of each PKM process is done. There is a trend discovered from the simulation, in which there are some “learning sessions” that are not used, or termed as “non-usage”. This is a significant finding that is found interesting for this research to investigate using real event logs data.
2.2. Process Model Discovery
Derived from business process management domain, process mining helps the analysis of business process based on actual data of event logs. It is often thought as the same as data mining, but it is not. Data mining algorithm is significant to process mining but the latter provides more comprehensive benefits in terms of the organizational system as a whole.
Event logs are analysed in the context of process-aware system [15], in which the full view of the case situation is being understood, hence the importance of the event logs to researchers. Process mining techniques are expected to be non-trivial because it is based on extraction of only useful information from the logs [16], which in turn could provide truthful, real data without biasness. Nevertheless, process mining can show that a real process in a system is more complex than the way it is planned to be in documents. The event logs from e-learning environments might contain huge amounts of fine granular events and process-related data, which consist of different categories that make the whole process messy and prone to producing waste of resources and useless data [17].
There are three different techniques suggested for process mining [18], as follows:
- Process Model Discovery: By using the event logs retrieved from the database, fuzzy miner algorithms are applied by the process mining software to produce a process model. This requires data to be readily available, in a situation where process model is not yet planned or developed in documentation.
- Conformance Checking: When a process model is available (either from the plans and documentation or from the discovery), the retrieved event logs are analysed to conform whether the real activities happening in the system is as how the process is modelled for, or not.
- Process Improvement: The purpose of this technique is to improve the existing process model using the information retrieved from the event logs. It is different than conformance checking because it measures the alignment between the model and the real online activities, hence producing an improved model that fits the condition deemed necessary.
There are several algorithms that can be used to perform process discovery including Fuzzy miner and Heuristic miner [19]. Fluxicon Disco is a recommended tool for automated process model discovery based on fuzzy miner algorithms. The strength of the fuzzy miner is the seamless process simplification and highlighting of frequent activities that are very useful for the research purpose [20]. The process model could be messy and fuzzy mining will come in handy in terms of filtering out the data and adjusting the level of details available in the model, in order to better perceive the process model.
3. Methodology
For this research, process model discovery will be used to initiate the process of discovering the GUSC Model in online learning environment and achieving the first objective. This is followed by conformance checking, to prove that GUSC processes really happen in the online environment, by simulating the processes through animated visualization, to achieve the second objective.
3.1. Case Settings
This research has chosen a case university that implements a Moodle-based online learning environment called “VLE”, i.e. virtual learning environment. The event logs data from year 2016 to 2017 was extracted from the VLE database for the purpose of this study. The event log consists online activities data that the students went through every day in the VLE. The extracted fields from the event logs data are date and time, case ID, and activity.
The students who performed the online learning activities in the selected case are those from semester three to six. They were chosen because they have experience using the VLE for more than one semester.
The selected courses for this study are from software engineering and business technology. These courses are selected to ensure that both technical and less technical contents are covered in the process model discovery, since the lecturers or instructors of both courses have their own way of delivering teaching materials online and assigning activities. For example, business technology may have a more theoretical contents compared to software engineering, hence the instructor may use discussion forum and wiki more than the latter.
Other important matters to be identified during case settings are the activities in the event log and the relevance of data to this research. Irrelevant data of less or non-relevant activities need to be omitted out, for example “register”, “delete comment” and “update profile”. Since the purpose of this research is to analyze PKM processes in VLE, the activities selected for analysis are those related to PKM activities only, such as “course module viewed”, “quiz attempt started” and “quiz attempt summary viewed”.
3.2. Process Discovery
In process discovery, the event log was extracted and imported into the chosen process mining tool (i.e. Fluxicon Disco), in which the log is automatically transformed to create a newly discovered process model using fuzzy miner algorithm. There are two ways of process discovery: play-in, i.e. from event log to process model; and play-out, i.e. from process model to event log [21].
The first step in classification of requirement is the extraction of the event log from VLE database and importing the event log into the Fluxicon Disco. Figure 1 shows the interface after the event log is imported into the tool.
From Figure 1, the event log (in *.CSV file format) that is inserted into the process mining tool needs to be classified according to the requirement, i.e. ID, Activity and Timestamp. Due to the difficulty of having process instances scattered over multiple rows (i.e. in *.CSV file), it is found that the Fluxicon Disco is a suitable tool for data extraction compared to a normal spreadsheet.
The basic data requirement for process mining is to look into the historical process data precisely, such as a “process lens”. The three requirements are as follows:
- i) Case ID: A case identifier, else called as process case ID, is important to recognize various executions of a similar process. The correctness of case ID relies on the domain of the process. For this research case, the case ID are Get, Understand, Share and Connect, i.e. the GUSC processes.
- ii) Activity: There ought to be names for various procedure steps or status changes as activities were performed in the process. In the event that the information only appears once or in a single passage (i.e. one row) for each procedure occasion, then it could be concluded that at that point the information is not detailed enough.
iii) Timestamp: From the timestamp, the delays between activities can be identified as it could show the duration of each activities in a process. This could be further related to the process of a series of activities and its duration across time.
 Figure 1: Event log being imported into Fluxicon Disco
Figure 1: Event log being imported into Fluxicon Disco
 Figure 2: Results after classification of requirement
Figure 2: Results after classification of requirement
3.3. Process Mapping
Figure 2 shows the result after classification of requirement has been confirmed. From the classification, a process model is developed based on the mapping that has been assigned in the event log. This process model can be manipulated by adjusting its part and activity frequency. This is to ensure that the process model is better understood, instead of merely showing the full process that involves so many paths and activities that will often be displayed as spaghetti-like process. Adjusting the activities to lower the frequency would not make the process model unreliable, but it could hide some activities that may not seem fit to the process model.
In a glance as shown in Figure 2, it is observed that there are two groups of activities being defined in the overall process. The left part of the process flow shows the learning activities over forum, file, URL, webpage and wiki, whereas the right part of the process flow shows the assessment related activities, mainly file submission, assignment and quiz.
Filtering of data can be easily done in Fluxicon Disco, as compared to using spreadsheet. Data that is identified to be useless for the process model simulation is filtered out. The Timeframe can also be filtered according to year, month and/or day, according to the time an active process happened. For this research, the whole timeframe is taken into account to see active months and years, so that none of the activities are left behind, e.g. student logging in to VLE during mid-semester break or in semester break. Figure 3 shows the interface of filtering process in Fluxicon Disco.
The statistics interface shown in Figure 4 displays an overview of the data, which can be in a huge amount. The statistics table shows which case is frequently active in the process, and the connection between each data. The Connect process is identified throughout the process in a more understandable way. This table generated in Fluxicon Disco also shows the frequency of each activity that consists the number of events data. The duration of each activity can also be viewed here.
 Figure 3: Filtering of data in Fluxicon Disco
Figure 3: Filtering of data in Fluxicon Disco
4. GUSC Model Simulation
This section presents the results of the GUSC Model simulation using the fuzzy miner algorithm in Fluxicon Disco. The simulation results are displayed in two modes: static view of GUSC process flow; and animated view of GUSC process flow.
The process model presented here basically shows the actual process that happened in VLE, which consists of the numbers of activities and their frequencies. The results shown here are presented according to three types, i.e. process model by components, by PKM process variables, and by activities that happened in the VLE.
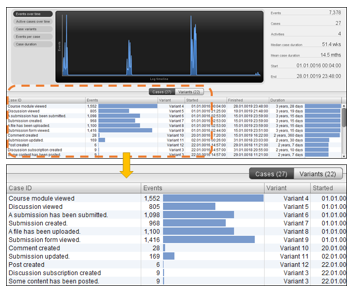 Figure 4: Statistics of activities in Fluxicon Disco
Figure 4: Statistics of activities in Fluxicon Disco
4.1. Static View of GUSC Process Flow
Figure 5 shows the process model that was developed according to components from the event log. In general, there are 10 components analyzed for process model discovery simulation: File; File submissions; Submission comments; Quiz; Assignment; Forum; Wiki; Online text submissions; URL; and Page.
 Figure 5: GUSC process model by components
Figure 5: GUSC process model by components
The ‘File’ component (shown in darkest shade in Figure 5), is the dominant one because the activities that happened on a ‘File’ is frequently active (i.e. 5,366 occurrences). Students’ activities of downloading or uploading files would fall under this ‘File’ component. Activities like ‘downloading notes’ are quiet common in the event logs and it happens quite frequently among the students.
‘URL’ (18 occurrences) is a component that is posted by the lecturers, in which the URL or hyperlink of a website is shared in the VLE for students to click on and be directed to the landing page with materials to learn. A ‘Page’ (221 occurrences) or webpage serves the same purpose as the ‘URL’, but instead of directly bringing the users to an external website, it is an internal webpage created by the lecturers, in which the students can view notes and multimedia contents like a page in a website within the VLE.
Each activity has different component and each component may share the same activity name. For example, the component ‘File’ may have two activities in it that are ‘Course module viewed’ and ‘Wiki page viewed’, and these two activities share the same component with ‘Forum’, ‘Page’, ‘URL’, and ‘Wiki’. This is due to the way the ‘File’ component is used within the other activities.
Table 1 shows the number of occurrences for each component shown in Figure 5. It also presents the number of recurrences for each component, which happened when students return to the same component during a session. Figure 5 also shows the frequencies of inflow and outflow processes, which are not presented in Table 1. However, the total number of recurrences, inflow and outflow processes for each component should be the same as the number of occurrences for each component.
Table 1: Component Occurrences in VLE
| Component | Occurrence | Recurrence |
| File | 5,366 | 4,716 |
| File submissions | 2,200 | 2,070 |
| Submission comments | 29 | 9 |
| Quiz | 88 | 74 |
| Assignment | 57 | – |
| Forum | 2,000 | 1,435 |
| Wiki | 307 | 202 |
| Online text submissions | 76 | 38 |
| URL | 18 | 1 |
| Page | 221 | 75 |
Figure 6 shows the process model that was developed according to PKM processes, based on the GUSC model. The processes are Get, Understand, Share and Connect, as stated in Section 2. These processes are mapped to the VLE activities in the imported event log data (i.e. in the *.CSV file), as the mapping was developed according to the PKM process model requirements made prior to this study.
As shown in Figure 6, the number shows the frequencies of the VLE activities that are mapped to the GUSC processes. The Get activity is the dominant one as compared to the other processes (shown in darkest shade in Figure 6). This result is as expected because the Get activities is common to happen more frequently than Share or Connect activities. The basic idea of having VLE is to provide a platform for students to Get information and knowledge shared by others, especially in the form of learning materials and notes.
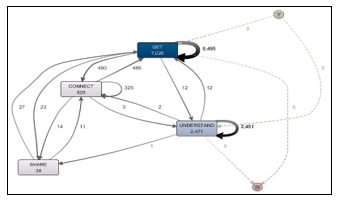 Figure 6: GUSC process model by PKM processes
Figure 6: GUSC process model by PKM processes
The looping arrow displayed on Get process shows a number of reworks that occurred in the event. An activity that keeps looping like this basically means that students kept downloading the same notes or materials, e.g. for three days in a row. The same pattern is seen on the Understand process, in which the process keeps looping on the same activity as the students attempt to understand the information and knowledge in VLE. An example of this is uploading of assignment, in which students are allowed to keep uploading an assignment, or attempt multiple submissions of an assignment, as long as the deadline has not yet past.
Table 2 shows the number of occurrences and recurrences for each GUSC process derived from Figure 6. As described for Table 1, the inflow and outflow processes are not shown here, but the number of occurrences should show the total number of inflow processes, outflow processes and recurrences as a whole.
Table 2: GUSC Process Occurrences in VLE
| Process | Occurrence | Recurrence |
| Get | 7,025 | 6,495 |
| Understand | 2,471 | 2,451 |
| Share | 38 | – |
| Connect | 828 | 325 |
Figure 7 shows the overall view of the GUSC process model according to VLE activities. The most dominant activity is “File – Course module viewed – Get” with 5,366 occurrences (shown in darkest shade in Figure 7). This is followed by “Forum – Course module viewed – Get” (1,167 occurrences) and “File submissions – A file has been uploaded – Understand” (1,100 occurrences). In other words, the Understand process does happen in an online learning environment like VLE, even if can only be proven by uploading of files to VLE.
In a glance, the process model presented in Figure 7 looks quite structured. Unlike the previous two views, Figure 7 shows no recurrences of any activity. Recurrences only happened between two activities, e.g. between “Forum – Course module viewed – Get” and “Forum – Discussion viewed – Connect” (470 occurrences to, and 473 occurrences return). Table 3 shows the summary of occurrences according to the activities derived from Figure 7.
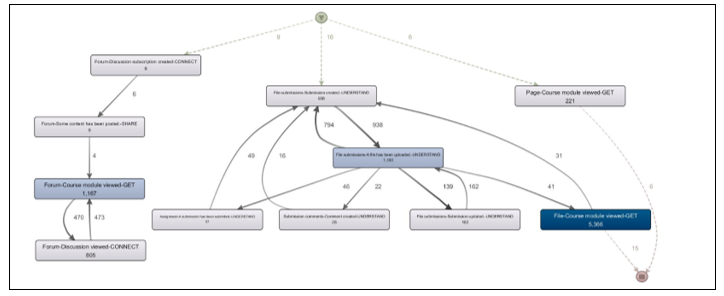 Figure 7: GUSC process model by activities
Figure 7: GUSC process model by activities
Table 3: Activity Occurrences in VLE
| Activity | Occurrence |
| Forum – Discussion subscription created – Connect | 9 |
| Forum – Some content has been posted – Share | 9 |
| Forum – Course module viewed – Get | 1,167 |
| Forum – Discussion viewed – Connect | 805 |
| File submissions – Submission created – Understand | 938 |
| File submissions – A file has been uploaded – Understand | 1,100 |
| Assignment – Submission has been submitted – Undestand | 17 |
| Submission comments – Comment content – Understand | 28 |
| File submissions – Submission updated – Understand | 102 |
| Page – Course module viewed – Get | 221 |
| File – Course module viewed – Get | 5,366 |
4.2. Animated View of GUSC Process Flow
The GUSC model simulation shows the movement of the processes in ‘blobbing’ shapes. The movement can be seen with different rhythm and speed depending on the time duration and frequency of the running processes. The thicker the line movement of the process travels, the frequent the process is. Figure 8 shows the snapshot of this animation of GUSC process model, in which the thicker line in red is where a process travels, and the yellow ‘blobbing’ shape shows the high volume per time unit.
As shown in Figure 8, the Understand process does not travel to other variables except for one way towards Share process, while Get, Connect and Share processes travel to each other. This can be explained that Get, Connect and Share processes happen before the Understand process can happen. The situation supports the findings of previous research that proved the Get, Connect and Share are connected to each other and they are the main processes of PKM [6]. This was statistical proven to justify that an Understand process can only happen when a Share process happens (the one-way line shown from Understand to Share in Figure 8), and Share process happens when Get and Connect processes happen (shown in darker lines in Figure 8).
 Figure 8: Animated view of GUSC process model
Figure 8: Animated view of GUSC process model
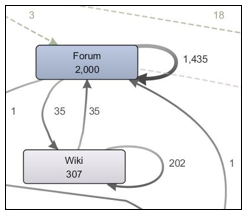 Figure 9: Frequency of occurrences and recurrences on Forum and Wiki
Figure 9: Frequency of occurrences and recurrences on Forum and Wiki
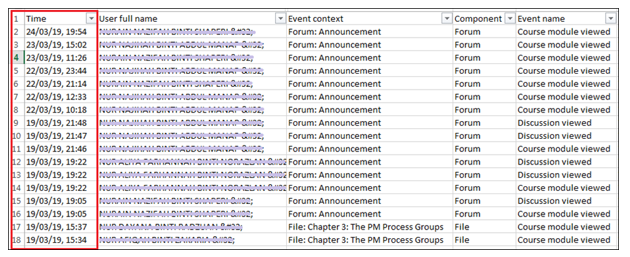 Figure 10: Timestamp in event log data
Figure 10: Timestamp in event log data
5. Discussions
Among the features available in VLE, forum is a powerful platform that can facilitate students in performing all PKM processes. It has been mapped to all four PKM processes, namely GUSC processes, and the results have shown that Forum receives high occurrences and recurrences in certain areas of PKM. Although Wiki has similar strength in providing the same PKM facilities, the exposure on its usage is still low, in which students do not find that Wiki could help in enhancing their learning capacity through collaboration and knowledge sharing. Both of these features or components require high commitment and interaction among the students, and thus the processes of Connect and Understand could be well performed on top of Get and Share.
The process model discovered through this simulation research has shown the real scenario of processes that occurred in VLE, but it is far from the expectation this research earlier perceived. A simple activity as downloading lecture notes is actually an important activity in VLE to achieve the process of Get knowledge, but it happens as a looping activity. In business process view, a looping activity is not good because it shows that the first time of performing the activity is not done properly. As a result, it can be concluded that the students are not managing their knowledge very well because they keep on downloading the same notes several times.
This research shows that using Forum and Wiki in VLE will not only let the students interact with each other but it can also boost the full potential of the VLE itself. Not many users know all the features in VLE that can provide the full potential benefits of managing knowledge, hence time is wasted on available precious resources. Figure 9 shows the frequency of the activities happened on Forum and Wiki, in which the process travels a lot between these two components that all the PKM processes happened in this loop simultaneously. In contrast, components like Assignment only fall under Understand process, as students only tend to submit their assignments once they have understood on how to complete them.
Figure 10 shows the event log data when it was first retrieved from the database. It does not show the start and end time of a process, but only the overall time when a process happened. The unavailability of both start and end timestamp in the VLE event log data has caused this limitation. This limitation has caused some difficulties in analyzing further on students’ activities, especially when the duration of each activity can produce significant measurement and findings for this research, in which the duration can be derived from having two timestamps.
Overall, the use of process mining has helped in proving a theoretical model like personal knowledge management processes, without biasness of respondents’ feedback. This research has proven that the same event log data can be used to analyze different theoretical models, as the same data was used in a research on self-regulated learning (SRL) model prior to this [22].
6. Conclusion
In a nutshell, this research has achieved its objectives of discovering PKM model by visualizing the process flow in online learning environment, and simulating the PKM processes using real case data for further verification on conforming the model. With the simulation views (i.e. both static and animated views), it is expected that online learning environment users can benefit in terms of knowing their status of managing knowledge. It should benefit both the lecturers (who can use the simulation to gauge students’ learning behavior as well as improving teaching initiatives) and students (who can know where they can improve in terms of responding to the learning system for own future benefits). Nevertheless, the process model discovered in this research is highly dependent on how the online learning environment is used in the case organization, in which the features used by both lecturers and students reflect whether the PKM model is fully complied or not. Missing features or activities may affect the learners’ capability of managing personal knowledge, as they depend on the features to exist for them to have more choices and fully utilize as part of their learning sessions.
It is recommended that the future work could improve the way this research is conducted, in terms of activity and component mapping to the PKM processes (i.e. GUSC), as well as identifying the start and end time for each activity in an online learning system to better analyze the overall PKM processes. Other opportunities include adopting suitable techniques to perform the process mapping to activities and extending this research on other courses and case settings.
Acknowledgment
This journal publication is funded by Centre of Research & Innovation, Universiti Kuala Lumpur, Malaysia.
- S. Ismail, F. Tumin, “Analysis on online learning environment using process mining technique for personal knowledge management mapping,” in International Conference on Research and Innovation in Information Systems, ICRIIS, 2019, doi:10.1109/ICRIIS48246.2019.9073269.
- L. Razmerita, K. Kirchner, F. Sudzina, “Personal knowledge management: The role of Web 2.0 tools for managing knowledge at individual and organisational levels,” Online Information Review, 33(6), 1021–1039, 2009, doi:10.1108/14684520911010981.
- H. Jarche, From observation to breakthrough, Adapting to Perpetual Beta Blog, 2012.
- S. Ismail, M.S. Ahmad, Z. Hassan, “Emerging personal intelligence in collective goals: Data analysis on the bottom-up approach from PKM to OKM,” Journal of Knowledge Management, 17(6), 2013, doi:10.1108/JKM-08-2013-0313.
- S. Ismail, T.D. Nguyen, M.S. Ahmad, “A multi-agent knowledge expert locating system: A software agent simulation on personal knowledge management (PKM) model,” in International Conference on Intelligent Systems Design and Applications, ISDA, 2014, doi:10.1109/ISDA.2013.6920705.
- S. Ismail, A. Othman, M.S. Ahmad, “Knowledge Management in Learning Environment: A Case Study of Students’ Coursework Coordination,” in Knowledge Management International Conference (KMICe), 2014.
- S. Ismail, S.F.M. Suhaimi, M.S. Ahmad, “The GUSC model in smart notification system: The quantitative analysis and conceptual model,” in 2013 8th International Conference on Information Technology in Asia – Smart Devices Trend: Technologising Future Lifestyle, Proceedings of CITA 2013, 2013, doi:10.1109/CITA.2013.6637581.
- S. Ismail, M.S. Ahmad, “Knowledge Management in Agents of Things: A case study of smart classroom management,” in International Conference on Research and Innovation in Information Systems, ICRIIS, 2013, doi:10.1109/ICRIIS.2013.6716685.
- S. Ismail, Z. Mohammed, N.W. Yusof, M.S. Ahmad, “Personal Knowledge Management among Adult Learners: Behind the Scene of Social Network,” International Journal of Humanities and Social Sciences, 2013.
- S. Ismail, M.S. Ahmad, “Personal Knowledge Management among Managers: Mobile Apps for Collective Decision Making,” Journal of Information Systems Research and Innovation, 2015.
- S. Ismail, N. Jamaludin, “Managing knowledge over social messaging application: The case of an event management project group,” in 2016 3rd International Conference on Computer and Information Sciences, ICCOINS 2016 – Proceedings, 2016, doi:10.1109/ICCOINS.2016.7783184.
- S. Ismail, M.F. Ghazali, “Mobile coursework coordination deploying the concept of agent-mediated personal knowledge management in learning environment,” in ICICTM 2016 – Proceedings of the 1st International Conference on Information and Communication Technology, 2017, doi:10.1109/ICICTM.2016.7890797.
- S. Ismail, “Simulating Get-Understand-Share-Connect model for personal knowledge management in learning environment,” in 2nd International Symposium on Agent, Multi-Agent Systems and Robotics, ISAMSR 2016, 2017, doi:10.1109/ISAMSR.2016.7809995.
- S. Ismail, “Simulating Get-Understand-Share-Connect model for personal knowledge management in learning environment,” in 2nd International Symposium on Agent, Multi-Agent Systems and Robotics, ISAMSR 2016, 2017, doi:10.1109/ISAMSR.2016.7809995.
- W. Van Der Aalst, T. Weijters, L. Maruster, “Workflow mining: Discovering process models from event logs,” IEEE Transactions on Knowledge and Data Engineering, 2004, doi:10.1109/TKDE.2004.47.
- W.M.P. Van Der Aalst, “Process-aware information systems: Lessons to be learned from process mining,” in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2009, doi:10.1007/978-3-642-00899-3_1.
- A.H. Cairns, B. Gueni, M. Fhima, A. Cairns, S. David, N. Khelfa, “Process Mining in the Education Domain,” International Journal on Advances in Intelligent Systems, 2015.
- W. Van der Aalst, Process mining: Data science in action, 2016, doi:10.1007/978-3-662-49851-4.
- K. Rattanathavorn, W. Premchaiswadi, “Analysis of customer behavior in a call center using fuzzy miner,” in International Conference on ICT and Knowledge Engineering, 2015, doi:10.1109/ICTKE.2015.7368485.
- V.A. Rubin, A.A. Mitsyuk, I.A. Lomazova, W.M.P. Van Der Aalst, “Process mining can be applied to software too!,” in International Symposium on Empirical Software Engineering and Measurement, 2014, doi:10.1145/2652524.2652583.
- W.M.P. Van Der Aalst, “Relating process models and event logs 21 conformance propositions,” in CEUR Workshop Proceedings, 2018.
- M.H.B.A. Bakar, S. Ismail, S.H.S. Ali, “A process mining approach to understand self regulated-learning in moodle environment,” International Journal of Advanced Trends in Computer Science and Engineering, 2019, doi:10.30534/ijatcse/2019/1581.32019.