A Fast Adaptive Time-delay-estimation Sliding Mode Controller for Robot Manipulators

Adv. Sci. Technol. Eng. Syst. J. 5(6), 904–911 (2020);
 DOI: 10.25046/aj0506107
DOI: 10.25046/aj0506107
A nonlinear adaptive robust controller is proposed in this paper for trajectory-tracking control problems of robot manipulators. On one hand, to effectively approximate the systematic dynamics, a simple time-delay estimator is first adopted. On the other hand, to minimize the control error, the controller is designed based on a sliding mode structure using the obtained estimation results. A fast learning mechanism is then proposed for automatically tuning control gains. Another proper adaptation law is furthermore developed to support the nominal inertia-matrix selection of the time-delay estimation. Effectiveness of the closed-loop system is intensively discussed using Lyapunov-based constraints and extended simulation results.
1. Introduction
Nowadays, robots play a crucial role in modern industry thanks to excellent performances in conducting complicated, repetitive, and dangerous tasks [1–4]. Day by day, high-precision intelligent robots are required to fulfill the given demands [2], [5]. To design such controllers, two important steps of the controller design are taken into account: nonlinearities and uncertainties in system models as well as unexpected effects of complex working environments have to be tackled to push the closed-loop system in a stationary state; in the second step, a driving robust control signal is generated to force the control objective stabilizing around origin [6–8].
Robot dynamics could be derived using Newton-Euler analyses, Lagrange formulations or virtual decomposition methods [6,9]. Although general systematic models could be obtained, but they contain lots of uncertainties due to particular structures of robots and disturbances [10,11]. To cope with the mathematical problems, soft-computing approaches are reasonable solutions [7,8]. Nonlinear uncertain dynamics could be well estimated by fuzzy-logic approximators and neural networks but heavy-computation burdens along with lots of tuning parameters are new obstacles in real-time applications. The time-delay estimation (TDE) is increasingly adopted as one of the most effective tools to reckon unknown dynamics in modern control, owing to the simplicity in design and easiness in real-time implementation [12,13]. This technique uses measured information of the acceleration and control signals to result in offset terms of the dynamics based on predefined nominal values of inertia matrices [5,14]. Effectiveness of the TDE methods has been gradually confirmed in both theoretical proofs and experimental validations [15,16].
To effectively complete control objectives in industrial applications, a proper control strategy with impressive adaptation and robustness ability is next required [17–19]. The sliding mode control (SMC) technique has a special attraction to designers thanks to the simplicity, widespread applications, and robustness to unknown system dynamics [20–23]. However, excellent control performances of the SMC controllers may be hard to maintain in different working cases. As a solution, gain-adaptive SMC schemes have been recently noted for servo systems [18,24–26]. Driving gains or robust gains were actuated by various learning mechanisms to effectively force the control objective to zero as fast as possible [25,26]. In these learning schemes, only one degree-of-freedom learning law is proposed, and the control error is stabilized to a bound around zero [17,24]. In another direction, intelligent approaches based on Type-2 fuzzy logic theory could be found as possible solutions of the gain adaptation [27,28]. Solving optimal problems of the closed-loop system under robustness constraints in a horizontal time yields the expected gains along with excellent control performances [29]. However, intensive behaviors of the gain variation that could judge the real-time control quality were ignored.
This paper is an extension of work originally presented in 2019 International Conference on System Science and Engineering (ICSSE) [1]. In the previous work, both driving and robust gains of a conventional TDE sliding mode controller were actively self-tuned subjecting to a minimal control error. Its effectiveness was confirmed by intensive simulation results. The controller was operated with a fixed nominal value of the inertia matrix of the system dynamics. Improperly selecting this term could lead to instability of the closed-loop system [15]. An excellent control performance is obviously associated with a perfect value of the matrix [16]. Nevertheless, the best nominal matrix is not same for different running states. As a sequence, a dynamical learning mechanism for such the term is the main motivation of this research for maintaining high control precision in various working conditions.
In this study, an adaptive TDE sliding mode controller is developed for trajectory-tracking control of serial robot manipulators with the following contributions:
- The system behaviors are first approximated by a basic time-delay estimator (TDE). To support selection of a proper inertia matrix in the estimation process, an adaptation rule is designed to search the optimal nominal one.
- The control objective is then realized by a robust sliding mode control method. To provide the flexibility in tuning the control gains in divergent operation cases, a fast gain-learning law is proposed. The adaptation mechanism is worked as a damping low-pass filter that could yield smooth responses of the closed-loop system. Different from the previous work [1], nonlinear leakage functions are employed to speed up the learning process.
- Control performances of the overall system are analyzed by a Lyapunov-based approach and comparative simulation results.
The rest of this paper is structured as follows. Section 2 presents system modeling and problem statement. Section 3 describes design of the proposed controller incorporated with the adaptation laws. Section 4 discusses validation results, and the paper is then concluded in Section 5
2. System Dynamics and Problem Statement
Dynamics of a n-joint robotic manipulator are generally expressed as follows [6,9,17,24]:
![]()
where are the joint angles, velocities, and accelerations, respectively, is the joint torques or control inputs, is the inertia matrix, is the Centripetal/Coriolis vector, is the gravitational term, is the frictional torque, and denotes disturbances.
The dynamics (1) could be simply rewritten in a following form:
![]()
where is an proper nominal diagonal inertia matrix, is a lumped term that is defined as a combination of other dynamic terms such as the Centripetal/Coriolis, gravity, inertia variation, frictions, disturbances, modeling errors and unmodeled terms.
Remark 1: Assume that the system outputs are measurable and a desired trajectory is bounded and differentiable up to the second order. The main objective of this paper is to find out an appropriate control signal to drive a tracking error of the system output and the given profile to zero or as small as possible. However, maintaining high control quality of the closed-loop system is a not-easy yet interesting work due to existence of the uncertain nonlinear dynamics and complicated working environments. Additional characteristics of the controller are required to be model-free, adaptive, and robust with high control performances.
3. An Adaptive Time-delay Nonlinear Controller
To accomplish the aforementioned features, the motion controller is built up based on a simple sliding mode framework incorporated with an adaptive time-delay estimator. Fast learning laws are then integrated to search proper control parameters. The proposed controller is sketched in Figure 1.
3.1. Simple Sliding Mode Control
The main control error is mathematically defined as
![]()
A sliding manifold is employed as an indirect control objective of the closed-loop system:
![]()
where is a selected positive-definite diagonal gain matrix.
For obtaining high-precision control results, the controller is designed with a model-free compensator – that could cope with the systematic uncertain nonlinearities and disturbances – and a robust control signal, as follows:
![]()
Here, is a model-dynamical eliminator that is used to compensate for unexpected effect of the offset vector ( ) on the control behaviors and other terms of the surface dynamics (4). The signal is thus selected as follows:
![]()
Note that the estimate of the offset dynamics ( ) is computed using the basic time-delay estimator [15,22]:

where the subscript is a time-delay value, is the sampling time, and is estimate of the nominal matrix .
The remaining term is designed to drive the sliding manifold from the stationary state back to around zero and stabilize thereafter by dealing with a model perturbance :
![]()
where is positive-definite diagonal gain matrices.
Remark 2: With the robust sliding mode design, excellent control outcome can be resulted in by a proper selection of the control gains and nominal inertia matrix regardless of the existence of the disturbances. It is however sometimes a challenge to perfectly tune the gains to achieve good transient performance and especially ensure high control accuracies for unpredictable execution conditions in the real-time control.
3.2. Gain-adaptation Laws
To treat difficulty of the gain selection, the strategy for gain tuning is proposed in that the control gains are separated into two terms: nominal gains and variation gains . The nominal ones are chosen for stability of the closed-loop system. The variation ones are automatically tuned for the desired transient performance.
A fast adaptation rule for the automatic control-gain tuning is designed as follows:
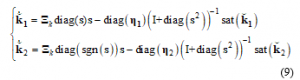
where are positive-definite diagonal constant matrices.
On the other hand, properly choosing the nominal inertia matrix could reduce bound of the system perturbance ( ). To efficiently support this task, a new learning law is proposed as follows:
![]()
where are positive-definite diagonal constant matrices.
3.3. Stability Analysis
The theoretical effectiveness of the closed-loop system is investigated using the following theorem:
Theorem 1: Employing the model-free sliding mode control signals (3)-(8) to the robot dynamics (2), in which the driving-robust gains and nominal inertia matrix are automatically updated using the laws (9)-(10), asymptotic convergence of the closed-loop system is resulted in if the following condition holds:

Proof:
The time derivative of the sliding manifold (4) along the system (2) is expressed

where is the system perturbance mentioned above, and is the estimation error of the nominal matrix
Now, we consider a Lyapunov function:
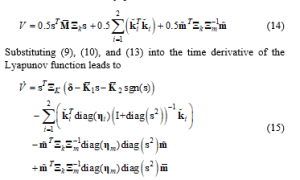
From the condition (11), there always exist two positive constants such that
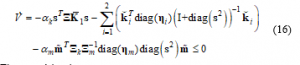
Theorem 1 has been proven:
Remark 3: As seen in Figure 1 as well as stated in Theorem 1, the controller is just designed under a simple TDE sliding mode control framework to ensure the stability of the overall system. However, control performance of the system is significantly improved by injecting excellent adaptation laws for the control gains and nominal inertia matrix. The proposed controller hence possesses strong robustness, model-free, and self-learnable ability.
4. Simulation Validation
4.1. Setup
To assess tracking performance of the proposed controller, extended simulations were carried out on a 2DOF robot. Configuration of the robot is depicted in Figure 2. The robot was selected to work in the vertical plane in which the gravity force was critically affected on the system performance. Dynamics of the robot are presented as follows [6,24]:
where are the robot joint angles. The detailed parameters of the robot model are given in Table 1.
Another robust-gain-learning TDE controller (RLTDE) was also applied to the same system as a benchmark for evaluating the effectiveness of the proposed controller.
The design of the RLTDE controller was referred as in the previous work [24], as follows:
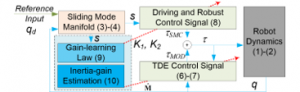
Figure 1: An overview of the designed controller.

Figure 2: Configuration of a 2DOF manipulator.
Table 1: Selected Parameters for the simulation model
|
The basic control gains of the two controllers were inherently selected as [24]:
For a pair comparison, the RLTDE controller was operated with four distinct parameter sets as given in Table 2, denoted as RLTDE1, RLTDE2, RLTDE3 and RLTDE4, respectively.
Table 2: Different Control Parameters Selected for the RLTDE Controller Implementation
| Name | Nominal Inertia Matrix | Control Gain |
| RLTDE1 | ||
| RLTDE2 | ||
| RLTDE3 | ||
| RLTDE4 |
Besides, the additional parameters of the proposed controller were manually tuned as follows:
4.2. Simulation Results
In the first scenario, reference inputs of the robot joints were selected to be sinusoidal signals plotted in Figure 3. By applying the controllers to the system, the simulation results obtained are presented in Figures 4 and 5.
As seen in Figure 4, the RLTDE1 provided very good control performances, 0.53 (RMS deg) and 0.44 (RMS deg) of the control errors at joints 1 and 2, thanks to employment of the strong robust gain (K2) generated by a nonlinear learning algorithm [24]. Behaviors of the robust gain adaptation are demonstrated in Figure 5. The key purpose of using such the gain in the RLTDE control method was to attenuate effect of the incomplete TDE estimation. Figure 4 also reveals that the control performances were further improved if the more proper control gains were found out. When increasing only the nominal inertia matrix , or only the driving gain , or both of them , higher control accuracies were exhibited such as: the RLTDE2 controller obtained 0.17 (RMS deg) and 0.12 (RMS deg) of the control errors at joints 1 and 2, respectively; the RLTDE3 controller got 0.2 (RMS deg) and 0.11 (RMS deg) ones; and the RLTDE4 controller provided 0.09 (RMS deg) and 0.06 (RMS deg) ones. It seems larger the control gains would create better the control performance. In fact, structures of the RLTDE and proposed controllers are almost same.
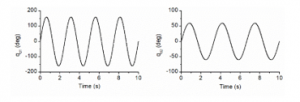
Figure 3: Reference inputs of the robot joints in the first simulation.
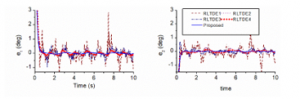
Figure 4: Control errors obtained in the first simulation
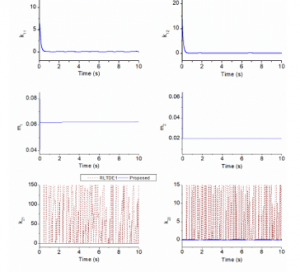
Figure 5: Comparative gains learning in the first simulation.
The core difference is that the proposed controller adopts the adaptation rules for the driving-robust gains and optimal nominal inertia matrix. Properly searching an optimal set of the driving gain and nominal inertia matrix could effectively reduce bound of the gain (K2) that could be clearly observed in Figure 5. Hence, as shown in Figure 4, the highest control precision, 0.03 (RMS deg) and 0.014 (RMS deg) of the control errors at joints 1 and 2, was resulted in by the proposed controller. Also noted in Figure 5, the optimal values did not need to be so large for the best control performance: the variation of the driving gain converged back to zero and the stationary nominal inertia matrix was found to be diag(0.062; 0.021). This implies the flexibility of the proposed controller over the previous one.
In the second scenario, the robot joints were controlled to track smooth step signals. Applying the same controllers to the system, the simulation results are presented in Figure 6, 7 and 8.

Figure 6: Reference signals of the robot joints in the second simulation.

Figure 7: Control errors obtained in the second simulation.
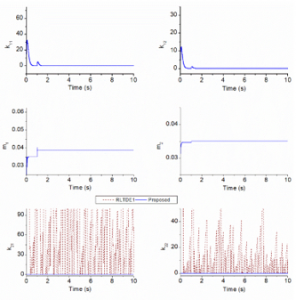
Figure 8: Comparative gains learning in the second simulation.
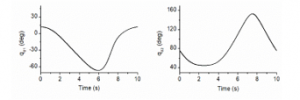
Figure 9: Desired joint angles computed from the eclipse trajectory of the end-effect in the third simulation.

Figure 10: Control errors obtained in the third simulation.

Figure 11: Comparative gains learning in the third simulation.
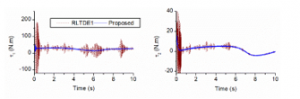
Figure 12: Control signal generated in the third simulation.
As shown in Figure 7, the control performances of the RLTDE1, 1.1 (MA deg) and 0.73 (MA deg) of the control errors at joints 1 and 2, were degraded as comparing to those of the other controllers. An improper selection of the nominal inertia matrix would make the systematic perturbance become large. Meanwhile, the driving gain was fixed with a small value, it means that the control performance was covered only by the robust gain . Another reason came from the special learning mechanism of the RLTDE: the robust gain was respectively increased and decreased as the sliding surfaces were outside and inside of specific regions. It implies that the RLTDE control outcome in this case depended on the regions predefined. New features integrated in the proposed controller could make the system avoid the aforementioned problems: as observed in Figure 8, the adaptation laws of the inertia matrix and control gains worked well to ensure the closed-loop system stabilize at origin or force the control error to be as small as possible. Hence, outperformance of the proposed controller, 0.005 (MA deg) and 0.01 (MA deg) of the control errors at joints 1 and 2, over the RLTDE1, 2, and 3 has been exhibited in this simulation scenario. Interestingly, once the perfect values of the driving gain and nominal inertia matrix were used, the RLTDE4 obtained an excellent control accuracy: 0.002 (MA deg) and 0.0004 (MA deg) of the control errors at joints 1 and 2.

Figure 13: Comparison of control results in Cartesian space
In the third verification case, the end-effector of the robot was controlled to track an eclipse trajectory. By applying inverse kinematic computation for the testing robot, the desired joint angles are displayed in Figure 9. Tracking control errors of the controllers for the new trajectory are plotted in Figure 10. The control results indicate that the RLTDE controllers tried to automatically adjust their gains to minimize the control error. However, using only one degree-of-freedom adaptation of the control gains was not adequate to result in the minimal sliding manifold even though they were supported with various control gains and nominal inertia matrices fine-tuned. The best control quality, 0.024 (MA deg) and 0.015 (MA deg) of the control errors at joints 1 and 2, were accomplished by the RLTDE4 which had just shown the outstanding performance in the second simulation. The control accuracy was significantly improved, 0.004 (MA deg) and 0.005 (MA deg) of the control errors at joints 1 and 2, by using three degree-of-freedom in the gain learning proposed by this paper.
Indeed, control input data generated by the controllers shown in Figure 12 reveal that sharing the robustness burden of the control mission into three learning spreads provided a faster response and a smaller control error. Its effectiveness and feasibility are demonstrated more clearly by plots of the comparative end-effector positions obtained by the proposed controller and a certain RLTDE one, as shown in Figure 13.
4.3. Discussion
The key properties of the proposed adaptation laws could be evidently expressed by data shown in Figure 5, 8 and 11: in transient time, the closed-loop system needed strong power to drive the control objective back to desired position regardless of uncertain nonlinearities and disturbances. To serve this mission, the driving and robust gains were promptly activated under the designed constraint (9), and the optimal nominal gain matrix was also searched according to the strategy (10). After that, the whole system would relax in steady-state time with the small-activated gains. By further considering these figures, much high-frequency oscillation could be observed in the learning gains of the RLTDE1 controller. In real-time operation with smooth control signals, the proposed controller could maintain the lifetime of the actuators.
Table 3: Statistical Evaluation of the Control Performances in the Simulation Scenarios
| Control Error | Joint 1 | Joint 2 | |||
| MA | RMS | MA | RMS | ||
| Test 1 | RLTDE1 | 2.87 | 0.53 | 1.98 | 0.44 |
| RLTDE2 | 0.6 | 0.17 | 0.26 | 0.12 | |
| RLTDE3 | 0.9 | 0.2 | 0.38 | 0.11 | |
| RLTDE4 | 0.22 | 0.09 | 0.11 | 0.06 | |
| Proposed | 0.05 | 0.03 | 0.04 | 0.014 | |
| Test 2 | RLTDE1 | 1.1 | 0.25 | 0.73 | 0.2 |
| RLTDE2 | 0.09 | 0.03 | 0.024 | 0.01 | |
| RLTDE3 | 0.48 | 0.13 | 0.18 | 0.06 | |
| RLTDE4 | 0.002 | 0.0004 | 0.0004 | 0.0001 | |
| Proposed | 0.005 | 0.001 | 0.01 | 0.007 | |
| Test 3 | RLTDE1 | 2.02 | 0.4 | 0.47 | 0.09 |
| RLTDE2 | 0.39 | 0.08 | 1.17 | 0.2 | |
| RLTDE3 | 2.2 | 0.27 | 0.13 | 0.03 | |
| RLTDE4 | 0.024 | 0.01 | 0.015 | 0.009 | |
| Proposed | 0.004 | 0.0018 | 0.005 | 0.002 | |
Table 3 summarizes static values of the control errors using maximum absolute (MA) and root-mean-square (RMS) computation for a specific time (5s to 12s). As seen in the table and by recalling the second simulation results, if the optimal set of the control gains and nominal inertia matrix were known, an exceptional control performance would be achieved. However, the optimal one was not same in different working conditions. Instead of searching the optimal values with time consuming, the designed controller integrated an automatic gain-tuning algorithm for suboptimal ones. The statistical data in Table 3 show that the proposed controller yielded the excellent MA and RMS results as comparing to the RLTDE ones in most of the simulation cases. Hence, the influence of such the suboptimal gains and inertia matrices on the control performance was acceptable. Here, advantages of the proposed controller are confirmed throughout both the analytical and validation results.
5. Conclusion
In this paper, a new adaptive robust control method is developed for position tracking-control problems of robot manipulators. The controller design is mainly based on the sliding mode control framework. Effect of the systematic uncertain nonlinearities and disturbances are well treated by an adaptive time-delay estimator. The driving-robust control signal is then employed for realizing the control objective. Fast gain-learning laws are properly designed to increase flexibility of the controller in various working conditions. The control gains are automatically tuned to provide both the desired transient performance and the steady-state behavior. Effectiveness of the closed-loop system is intensively investigated by theoretical proofs and comparative simulations.
Conflict of Interest
The author declares no conflict of interest.
- D.X. Ba, M.-H. Le, “Gain-learning sliding mode control of robot manipulators with time-delay estimation,” in 2019 International Conference on System Science and Engineering (ICSSE), 478–483, 2019.
- Y. Park, I. Jo, J. Lee, J. Bae, “A Dual-cable Hand Exoskeleton System for Virtual Reality,” Mechatronics, 49(November 2017), 177–186, 2018, doi:10.1016/j.mechatronics.2017.12.008.
- T.L. Nguyen, S.J. Allen, S.J. Phee, “Direct torque control for cable conduit mechanisms for the robotic foot for footwear testing,” Mechatronics, 51(August 2016), 137–149, 2018, doi:10.1016/j.mechatronics.2018.03.004.
- G. Chen, B. Jin, Y. Chen, “Nonsingular fast terminal sliding mode posture control for six-legged walking robots with redundant actuation,” Mechatronics, 50(August 2016), 1–15, 2018, doi:10.1016/j.mechatronics.2018.01.011.
- M. Tavakoli, P. Lopes, L. Sgrigna, C. Viegas, “Motion control of an omnidirectional climbing robot based on dead reckoning method,” Mechatronics, 30, 94–106, 2015, doi:10.1016/j.mechatronics.2015.06.003.
- L. Wang, T. Chai, L. Zhai, “Neural-network-based terminal sliding-mode control of robotic manipulators including actuator dynamics,” IEEE Transactions on Industrial Electronics, 56(9), 3296–3304, 2009, doi:10.1109/TIE.2008.2011350.
- Z. Liu, G. Lai, Y. Zhang, C.L.P. Chen, “Adaptive Fuzzy Tracking Control of Nonlinear Time-Delay Systems with Dead-Zone Output Mechanism Based on a Novel Smooth Model,” IEEE Transactions on Fuzzy Systems, 23(6), 1998–2011, 2015, doi:10.1109/TFUZZ.2015.2396075.
- J.J. Craig, Introduction to Robotics: Mechanics and Control, 3rd ed., Pearson Prentice Hall, USA, 2005.
- W.-H. Zhu, Virtual Decomposition Control: Toward hyper degrees of freedom robots, Springer-Verlag Berlin Heidelberg, 2010.
- S. Islam, X.P. Liu, “Robust Sliding Mode Control for Robot Manipulators,” IEEE Transactions on Industrial Electronics, 58(6), 2444–2453, 2011.
- W. Kim, C.C. Chung, “Robust output feedback control for unknown non-linear systems with external disturbance,” IET Control Theory and Applications, 10(2), 173–182, 2015, doi:10.1049/iet-cta.2014.1299.
- T.C. Hia, S. Jung, “A Simple alternative to Neural Network Control Scheme for Robot Manipulators,” IEEE Transactions on Industrial Electronics, 42(4), 414–416, 1995.
- S. Kim, J. Bae, “Force-mode Control of Rotary Series Elastic Actuators in a Lower Extremity Exoskeleton using Model-inverse Time Delay Control ( MiTDC ),” IEEE/ASME Transactions on Mechatronics, 22(3), 1392–1400, 2017, doi:10.1109/TMECH.2017.2687979.
- T.C. Hia, “A New Technique for Robust Control of Servo Systems,” IEEE Transactions on Industrial Electronics, 36(1), 1–7, 1989.
- K. Youcef-toumi, O. Ito, “A Time Delay Controller for Systems With Unknown Dynamics,” Journal of Dynamic Systems, Measurement, and Control, 112(1), 133–142, 1990.
- Y. Wang, D. Yu, Y. Kim, “Robust Time-Delay Control for the DC – DC Boost Converter,” IEEE Transactions on Industrial Electronics, 61(9), 4829–4837, 2014.
- M. Jin, J. Lee, N.G. Tsagarakis, “Model-free Robust Adaptive Control of Humanoid Robots with Flexible Joints,” IEEE Transactions on Industrial Electronics, 64(2), 1706–1715, 2016, doi:10.1109/TIE.2016.2588461.
- F. Mazenc, P.-A. Bliman, “Backstepping Design for Time-Delay Nonlinear Systems,” IEEE Transactions on Automatic Control, 51(1), 149–154, 2006.
- C. Hu, B. Yao, Q. Wang, “Performance-Oriented Adaptive Robust Control of a Class of Nonlinear Systems Preceded by Unknown Dead Zone With Comparative Experimental Results,” IEEE Transactions on Industrial Electronics, 18(1), 178–189, 2013.
- V.I. Utkin, “Sliding Mode Control Design Principles and Applications to Electric Drives,” IEEE Transactions on Industrial Electronics, 40(1), 23–36, 1993.
- J. Zhang, W.X. Zheng, “Design of Adaptive Sliding Mode Controllers for Linear Systems via Output Feedback,” IEEE Transactions on Industrial Electronics, 61(7), 3553–3562, 2014.
- M. Zhihong, A.P. Paplinski, H.R. Wu, “Robust MIMO Terminal Sliding Mode Control Scheme for Rigid Robotic Manipulators,” IEEE Transactions on Automatic Control, 39(12), 2464–2469, 1994.
- A. Pisano, M. Rapaic, E. Usai, Sliding modes after the first decade of the 21st century, Springer-Verlag Berlin Heidelberg: 412, 2012.
- J. Baek, M. Jin, S. Han, “A New Adaptive Sliding Mode Control Scheme for Application to Robot Manipulators,” IEEE Transactions on Industrial Electronics, 63(6), 3628–3637, 2016, doi:10.1109/TIE.2016.2522386.
- Y. Shtessel, M. Taleb, F. Plestan, “A novel adaptive-gain supertwisting sliding mode controller: Methodology and Application,” Automatica, 48(5), 759–769, 2012, doi:10.1016/j.automatica.2012.02.024.
- C. Xia, G. Jiang, W. Chen, T. Shi, “Switching-Gain Adaptation Current Control for Brushless DC Motors,” IEEE Transactions on Industrial Electronics, 63(4), 2044–2052, 2016.
- M.H. Khooban, T. Niknam, F. Blaabjerg, M. Dehghani, “Free chattering hybrid sliding mode control for a class of non-linear systems: electric vehicles as a case study,” IET Science, Measurement and Technology, 10(7), 776–785, 2016, doi:10.1049/iet-smt.2016.0091.
- N.M. Tri, D.X. Ba, K.K. Ahn, “A gain-adaptive intelligent nonlinear control for an electrohydraulic rotary actuator,” Internation Journal of Precision Engineering and Manufacturing, 19(5), 665–673, 2018.
- M.H. Khooban, N. Vafamand, T. Niknam, T. Dragicevic, F. Blaabjerg, “Model Predictive Control based on T-S Fuzzy model For Electrical Vehicles Delayed Model,” IET Electric Power Applications, 11(5), 918–934, 2017.