
Fuzzy Recognition by Logic-Predicate Network
Volume 5, Issue 4, Page No 686-699, 2020
Author’s Name: Tatiana Kosovskayaa)
View Affiliations
Department of Mathematics and Mechanics, St. Petersburg State University, St. Petersburg, 199034, Russia
a)Author to whom correspondence should be addressed. E-mail: kosovtm@gmail.com
Adv. Sci. Technol. Eng. Syst. J. 5(4), 686-699 (2020); ![]() DOI: 10.25046/aj050482
DOI: 10.25046/aj050482
Keywords: Predicate calculus, logic-predicate approach to AI, predicate network, fuzzy predicate network

Export Citations
The paper presents a description and justification of the correctness of fuzzy recognition by a logic-predicate network. Such a network is designed to recognize complex structured objects that can be described by predicate formulas. The NP-hardness of such an object recognition requires to separate the learning process, leaving it exponentially hard, and the recognition process itself. The learning process consists in extraction of groups of features (properties of elements of an object and the relations between these elements) that are common for objects of the same class. The main result of a paper is a reconstruction of a logic-predicate recognition cell. Such a reconstruction allows to recognize objects with descriptions not isomorphic to that from a training set and to calculate a degree of coincidence between the recognized object features and the features inherent to objects from the extracted group.
Received: 28 May 2020, Accepted: 04 August 2020, Published Online: 28 August 2020
1. Introduction
This paper is an extension of work originally presented in conference CSIT-2019 [1].
The term “logical approach to solving Artificial Intelligence (AI) problems” is usually understood as data notation in the form of a binary string that defines the values of some object properties under study. In this case, if the object is represented as a set of its elements that have some properties and are connected by given relations, then when describing it as a binary string, firstly, the structure of the object itself is lost, and secondly, you have to store a large number of “unnecessary” information that the element aj does not have the properties pi1,…, pik , that the elements aj1,aj2 are not in the relations qi1,…,qil , etc.
Consider objects composed of smaller elements with preassigned properties, and some smaller object having preassigned relations. In such a case predicate formulas are an adequate description language.
The use of predicate calculus and automatic proof of a theorem for AI problems solving was offered by many authors [2]-[4] in the 70-th years of the XX century. At the same time the notion of NP-completeness was introduced and began to be actively used by the scientific community [5].
In 2003 the use of predicate calculus and automatic proof of a theorem for AI problems solving (without complexity bounds) was described in [6].
In particular, in that book it is shown that if a binary string simulates a description of an economic problem in which interaction agents have given properties and are in given relations then the notation length of such a string is exponential of the length of the description of the same problem input data by setting properties of these agents and relations between them, i.e. in fact, using the language of predicate calculus.
In 2007 the author of this paper has proved NP-completeness of recognition problems described in the terms of predicate formulas and upper bounds of number of steps for two solving algorithms [7]. When such problems are solved by an exhaustive search algorithm, their computational complexity coincides with the length of their input data encoding using a binary string [6].
A hierarchical level description of classes was suggested in [8] to decrease the computational complexity of these problems. Formulas which are isomorphic to “frequently appeared” sub-formulas of “small complexity” are extracted from class descriptions in order to construct such a level description. This allows to decompose the main problem into a series of similar problems with input data with the smaller length. An instrument for this extraction is partial deduction of a predicate formula [9],[10].
Later, the author noticed that the level description is actually a recognition network, which, after training (having exponential computational complexity), can quickly solve the recognition problem.
The concept of “network” is increasingly used both in theoretical and in practical research, particularly, when solving pattern recognition problems. Research and practical applications of neural networks [11],[12], Bayesian networks [13]-[15], technical networks [16] are widespread. The inputs of such networks are usually signals characterizing the properties of the studied objects or processes, and expressed, as a rule, by numerical characteristics, which can be encoded by binary strings. The processing of binary strings in the most cases is carried out in linear or polynomial (usually quadratic) number of steps under the length of these strings. A convenient model for processing such strings is propositional logic (Boolean functions).
As noted above, the use of binary strings in the recognition of complex structured objects has disadvantages. To recognize such objects, the author offered the notion of a logic-predicate network using level description of classes [17]. Such a network contains two blocks: a training block and a recognition block. The training block run is based on the extraction from a class of objects description such fragments, which are inherent in many objects of the class. Recognition block run is reduced to the sequential solution of problems of the same type with a smaller length of the input data.
The disadvantage of such a recognition network is that it is able to recognize only objects that differ from those included in the training set (TS) by renaming the elements of the object (objects with isomorphic descriptions). But such a network can be retrained by adding unrecognized objects to the TS. This was the reason for modification of the logic-predicate network permitting to recognize objects, that not coincide but only similar to the objects from a training set. Such a modification was offered in [1, 18]. The degree of coincidence for description of an object part and the formula, satisfiability of which is checking in the cell, is calculated. Such a fuzzy network allows not only quickly enough to recognize objects isomorphic to those represented in the TS, but also to calculate the degree of coincidence that a “new” object belongs to one or another class. If necessary, it can be retrained using such a “new” object.
The structure of the paper is as follows. Section 2 “Logic-predicate approach to AI problems” contains 2 subsections: “Problem Setting” and “Important Definitions”. This section describes the results previously obtained by the author and defines the terminology previously introduced by the author, which are necessary for understanding the further presentation.
Section 3 “Level description” presents the basic idea of constructing a level description of classes. It contains two sub-sections “Construction of a level description of classes” and “The use of level description of a class”. They give algorithms for constructing a level description of classes and the use of such a description for object recognition. These algorithms are further used in constructing the logic-predicate network. It is shown that the computational complexity of an object recognition decreases while using a level description of a class.
Section 4 “Logic-predicate network” describes the structure of such a network.
Section 5 “Example of logic-predicate network” describes an example illustrating the formation of a network, recognizing of an object with the use of a network, and its retraining. It consists of 4 sub-sections “Training Block Run: Extraction of Sub-Formulas”,
“Training Block Run: Forming a Level Description”, “Recognition Block Run” and “Retraining the Network”.
Section 6 “Fuzzy recognition by a logic-predicate network” describes the changes that need to be made to the logic-predicate network in order to recognize objects that are not isomorphic to those presented in the TS. A description of the contents of a fuzzy network cell is given. A cell of this type replaces each cell in the logic-predicate network in which the logical sequence of the target formula from the description of an object is checked. In this case, the degree of coincidence is calculated that the fragment being tested partially (and to what extent) satisfies the target formula.
Section 7 “Model example of fuzzy recognition” presents an example of fuzzy recognition of a “new” object.
In comparison with [1], the setting of problems that can be solved in the framework of logic-predicate approach are described in the presented paper in more details. A justification for the introduction of a level description is given. Algorithms for a level description construction and a level description use are described. Scheme 1 of a common up to the names of arguments sub-formulas extraction is added. A section 5 has been added with an example of constructing and modifying a logic-predicate network. It describes in details how a network is formed by the training set, a new object is recognized, and the network is rebuilt. The scheme of a fuzzy logic-predicate network cell is presented. An example of fuzzy recognition is described in more details.
2. Logic-Predicate Approach to AI Problems
A detailed presentation of the logic-predicate approach to solving AI problems is available in [19]. In this paper only a general setting of problems and main methods for their solving are formulated.
2.1 Problem Setting
As it was mentioned in the Introduction, if an object to be recognized is a complex structured one, then predicate formulas are a convenient language for its description and recognition. Let an investigated object ω be represented as a set of its elements ω = {ω1,…,ωt} and be characterized by predicates p1,…, pn which define some properties of its elements or relations between them. The description S(ω1,…,ωt) of the object ω is a set of all constant literals (atomic formulas or their negations) with predicates p1,…, pn which are valid on ω.
Let the set of all investigated objects Ω be is divided into classes Ω1,…,ΩK such that k. Logical description of the class Ωk is such a formula Ak(x)[1] that if the formula Ak(ω) is true then ω ∈ Ωk. The class description may be represented as a disjunction of elementary conjunctions of atomic formulas.
Many AI problems may be formulated as follows with the use of such descriptions.
Identification problem. To pick out all parts of the object ω which belong to the class Ωk
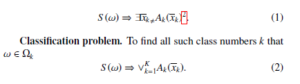
Analysis problem. To find and classify all parts τ of the object ω which may be classified
![]()
In fact, instead of the quantifier ∃ (whether exists) a symbol ?
(for what) must be written. But if one uses a constructive method of its proof (an exhaustive search algorithm or logical methods such as derivation in a sequential predicate calculus or resolution method for predicate calculus) then not only existence of such arguments would be proved but the values of them would be found.
It was proved that the problems (1) and (3) are NP-complete [7] and the problem (2) is GI-complete [20], i.e. it is polynomially equivalent to the “open” problem of Graph Isomorphism, for which it is not proved its NP-completeness and a polynomial in time algorithm is not found.
As the formulas Ak(xk) may be represented as a disjunction of elementary conjunctions of atomic formulas, the checking of each of the problems (1), (2) and (3) may be reduced to sequential checking of the formula
![]()
where A(x) is an elementary conjunction. Note that in the case of the problem (2) the number of variables in x equals to the number of constants in ω.
The formula (4) may be checked, for example, by an exhaustive algorithm and an algorithm based on the derivation in sequential calculus or on the use of resolution method.
The upper bound of number of steps for an exhaustive algorithm is O(tm)[3], where t is the number of elements in ω, m is the number of variables in A(x) [7]. This upper bound coincides with the upper bound of a binary string simulating input data in the form of S(ω) and A(x).
The upper bound of the number of steps for a logical algorithm is O(sa) where s is the maximal number of atomic formulas in S(ω) with the same predicate symbol having occurrences in A(x), a is the number of atomic formulas in the elementary conjunction A(x) [21].
Obviously, these estimates depend exponentially on the parameters of the formula A(x). That’s why it will be useful to break the solution of the problem into a series of sub-problems of the type (4) with a shorter right-hand side.
2.2 Important Definitions
The objects and notions satisfying the following definitions will be used later in the text.
Definition 1: Elementary conjunctions P(a1,…,am) and Q(b1,…,bm) are called isomorphic P(a1,…,am) ∼ Q(b1,…,bm),
if there are an elementary conjunction R(x1,…, xm) and substitutions of arguments ai1,…,aim and bj1,…,bjm instead of the variables x1,…, xm such that the results of these substitutions R(ai1,…,aim ) and R(bj1,…,bjm ) coincide with formulas P(a1,…,am) and Q(b1,…,bm), respectively, up to the order of literals.
The substitutions (ai1 → x1,…,aim → xm) and (bj1 → x1,…,bjm → xm) are called unifies of R(x1,…, xm) with P(a1,…,am) and Q(b1,…,bm) and are denoted as λR,P and λR,Q, respectively. [1], [20]
Note that concept of isomorphism of elementary conjunctions of atomic predicate formulas differs from the concept of equivalence of these formulas, because they can have significantly different arguments. In fact, for isomorphic formulas there are permutations of their arguments such that they define the same relationship between their arguments.
Definition 2: Elementary conjunction C(x1,…, xn) is called a common up to the names of arguments sub-formula of two elementary conjunctions A(a1,…,am) and B(b1,…,bk) if it is isomorphic to some sub-formulas A0(a01,…,a0n) and B0(b01,…,b0n) of A(a1,…,am) and B(b1,…,bk), respectively. The unifiers of C(x1,…, xn) with A0(a01,…,a0n) and B0(b01,…,b0n) will be denoted as λC,A and λC,B, respectively [19].
For example, let A(x,y,z) = p1(x) & p1(y) & p1(z) & p2(x,y) & p3(x,z),
B(x,y,z) = p1(x) & p1(y) & p1(z) & p2(x,z) & p3(x,z).
The formula P(u,v) = p1(u) & p1(v) & p2(u,v) is their common up to the names of variables sub-formula with the unifiers λP,A = (x → u,y → v) and λP,B = (x → u,z → v) because P(x,y) = p1(x)&p1(y)&p2(x,y) is a sub-formula of A(x,y,z) and P(x,z) = p1(x)&p1(z)&p2(x,z) is a sub-formula of B(x,y,z).
Definition 3: Elementary conjunction C(x1,…, xn) is called a maximal common up to the names of arguments sub-formula of two elementary conjunctions A(a1,…,am) and B(b1,…,bk) if it is their common up to the names of arguments sub-formula and after adding any literal to it, it ceases to be one [19].
For further presentation, the concept of partial sequence [9] is important.
The problem of checking if the formula A(x) or some its subformula A0(y) is a consequence of the set of formulas S(ω) is under consideration in [9]. Here the list of arguments y0 is a sub-list of the list of arguments y.
Definition 4: Let A(x) and B(y) be elementary conjunctions.
A(x) ⇒ ∃y, B(y) is not valid but for some sub-formula B0(y0) of B(y) the sequence A ) is true, we will say that B(y) is a partial sequence from A(x) and denote this by A(x) ⇒P ∃y, B(y) [1].
A constructive algorithm for a proof of partial sequence is in [22]. While using a constructive algorithm to prove A(x) ⇒P ∃y, B(y) we can find the maximal sub-formula B0(y0) such that A(x) ⇒ ∃y0, B0(y0) and such values x0 (x0 is a permutation of a sub-string of x) for y0 that B0(x0) is a sub-formula of A(x). It means that we find a maximal common up to the names of arguments sub-formula B0(y0) of two elementary conjunctions A(x) and B(y) and its unifier with B0(x0) (a sub-formula of A(x)).
Further, for fuzzy recognition of an object we need an extension of the partial sequence concept.
Every sub-formula A0(x0) of the formula A(x) is called its fragment [1].
Let a and a0 be the numbers of atomic formulas in A(x) and A0(x0), respectively, m and m0 be the numbers of objective variables in x and x0, respectively.
Numbers q and r are calculated by the formulas q = aa0 , r = mm0 and characterize the degree of coincidence between A(x) and A0(x0). For every elementary conjunction A(x) and its fragment A0(x0) it is true that 0 < q ≤ 1, 0 < r ≤ 1. Besides, q = r = 1 if and only if A0(x0) coincides with A(x).
Under these notations, the formula A0(x0) will be called a (q,r)fragment of the formula A(x) [1].
If S(ω) ⇒ ∃x, A(x) is not valid but for some (q,r)-fragment A0(x0) (q , 1) of A(x) the sequence S ) is true, we will say that S(ω) ⇒P ∃x, A(x) is a partial (q,r)-sequence for description S(ω) [1].
A (q,r)-fragment A0(x0) of the formula A(x) with maximal value of q satisfying S(ω) ⇒ ∃x0, A0(x0) will be called a maximal fragment of the formula A(x) for description S(ω) [1].
As for a maximal fragment of the formula A(x) the checking whether S(ω) ⇒ ∃x0, A0(x0) may be done by some constructive method then such values τ (τ ⊆ ω) for the list of variables x0 that S(ω) ⇒ A0(τ) will be found.
Definition 5: Conjunction of literals from A(x) which are not in A0(x0) is called a complement of A0(x0) up to A(x) [1]. A complement of A0(x0) up to A(x) will be denoted by CA(x)A0(x0).
Definition 6: A (q,r)-fragment A0(x0) of the formula A(x) is called contradictory to the description S(ω) on the list of constants τ if S(ω) and C[A(x)]τx0 A0(τ) lead to the contradiction, i.e., S(ω) ⇒ ¬C[A(x)]τx0 A0(τ) [1].
Here the denotation [A(x)]τx0 is used for the result of substitution of the constants from the list τ instead of the corresponding variables from the list x0.
3. Level Description
As noted above, estimates of the number of steps of the proof of (4) exponentially depends on the number of variables or on the number of literals of the formula A(x). Moreover, the proof of formulas (1),
(2) and (3) in which Ak(xk) = Ak,1(xk,1) ∨ ··· ∨ Ak,mk (xk,mk ), with the available algorithms for solving (4), can be reduced to a sequential proof of (4) with Ak,1(xk,1),…, Ak,mk (xk,mk ) on the right side.
Due to the unprovable, but repeatedly confirmed in practice, statement of Einstein “God is subtle, but he is not malicious” elementary conjunctions included in the description of one class must have common up to the names of arguments sub-formulas. Therefore, it is natural to break the proof of this formula into a series of formulas of the same kind, but with lower values of the essential parameters. This may be done by means of the following procedure.
- Extract “frequently occurred” common up to the names ofarguments sub-formulas P1i (y1i ) (i = 1,…,n1) of goal formulas Ak,1(xk,1),…, Ak,mk (xk,mk ) with “small complexity”. Simultaneously we find unifiers of P1i (y1i ) and sub-formulas of Ak(x1,…, xm).
- For every sub-formula P1i (y1i ) a new 1st level predicate p1i with one 1st level variable y1i , defined by the equivalence p1i (y1i ) ⇔
P1i (y1i ), is introduced. This 1st-level variable y1i is a variable for a string of initial variables.
- Replace each occurrence of a formula, isomorphic to P1i (y1i ) (i = 1,…,n1), into Ak,j(xk,j) (j = 1,…,mk) with a literal pi1(yi1 ). The earlier found unifier gives us the particular string of initial variables which are in this occurrence of y1i . Denote the received from Ak,j(xk,j) formula by means of A1k,j(x1k,j).
For l = 1,…, L − 1 repeat this procedure for Alk,1(xlk,1),…, Alk,mk (xlk,mk ) and receive formulas Alk+,11(xkl+,11),…, Alk+,m1k (xlk+,m1k ). The process will end because the number of literals in Alk,j(xlk,j) decreases with increasing l.
Level description of formulas Ak,1(xk,1),…, Ak,mk (xk,mk ) has the
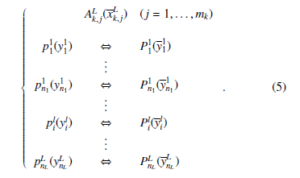
The described procedure deals with such intuitive notions as “frequently occurred” and having “small complexity” sub-formula. In the following algorithms it is supposed that “frequently occurred” means that a sub-formula appears at least twice and “small complexity” means that the number of a sub-formula literals is less then such a number of at least one of the initial formulas.
3.1 Construction of a Level Description of Classes
An algorithm for construction of a level description of classes is presented in [19], [23]. This algorithm contains two parts: 1) extraction of common up to the names of arguments sub-formula from the class description, 2) forming a level description. Here it is presented with more accuracy.
1) Extraction of common up to the names of arguments subformulas from the class description Let the description of a class be A(x) = A1(x1) ∨ ··· ∨ AK(xK), where A1(x1),…, AK(xK) are elementary conjunctions of literals.
- For every i and j (i < j) check whether Ai(xi) ⇒P ∃xj, Aj(xj).
Using the notion of partial sequence we can obtain a maximal common up to the names of arguments sub-formula Q1i,j(z1i,j) of two elementary conjunctions Ai(xi) and Aj(xj) and unifiers λQ1i,j,Ai and λQ1i,j,Aj . Let si be the lists of indices of Qlsi (zlsi ).
- For l = 1,…, L − 1 do.
- For every si and sj (si , sj) do.
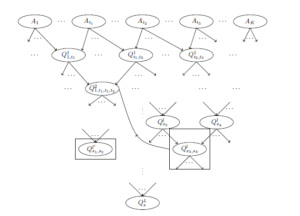
Figure 1: Scheme of common up to the names of arguments sub-formulas extraction.
- In the similar way find a maximal common up to the names
of arguments sub-formula Qls+i,1sj (zls+i,1sj ) of the formulas Qlsi (zlsi ) and Qlsj (zlsj ) and unifiers λQls+i,1sj ,Qlsi and λQls+i,1sj ,Qlsj .
- If a formula Qls+i,1sj (zls+i,1sj ) is isomorphic to some previously obtained Qls0(zls0) for some s and l0 ≤ l+1 then it is deleted from the set of the (l + 1)th level formulas and we wright down unifiers λQls0,Qlsi and λQls0,Qlsj .
Note that the length of Qls+i,1sj (zls+i,1sj ) decreases with increasing l. That is why the process would stop.
A scheme of the extraction is presented in Figure 1. In order not to overload the scheme, the arguments of the formulas are not written on it and instead of Qlsi (zlsi ) it is written Qlsi In this scheme it is supposed that highlighted together with its connections formula Qls3,s4 is isomorphic to some previously obtained formula, for example, to Q21,i1,i1,i2 and that’s why it is deleted from the set of the lth level formulas and all its connections are rewrited to Q21,i1,i1,i2.
A formula Qls01,s2 that does not have a common sub-formula with any other formulas, is highlighted on it.
2) Forming a level description.
Further, we assume that Q0i (z0i ) is Ai(xk,i).
- Every formula of the type Qls(zls) which has no sub-formula of the type Qls+,s1j (zls+,s1j ) for any sj is declared as Pi1 (y1i ) (i = 1,…,n1).[4]
A new 1st level predicate defined as p1i (y1i ) ⇔ P1i (y1i ) is introduced and p1i (y1i ) is substituted (using the correspondent unifies) instead of P1i (y1i ) into all formulas of the type Qls(zls) (l ≥ 0) such that there is an oriented path from Qls(zls) to P1i (y1i ).
- For l = 1,…, L − 1 do.
For every i = 1,…,nl if Pli(yli) is a maximal common up to the names of arguments sub-formula of formulas Ql0 (zl0 ) and Ql0 (zl0 ) then these formulas are declared as Pli00+1(yli00+1) and Pli00++11(yli00++11) (i00 = 1,…,nl+1 − 1).
New (l + 1)th level predicates pli00+1(yli00+1) and pli00++11(yli00+1) defined as pli00+1(yli00+1) ⇔ Pli00+1(yli00+1) and pli00++11(yli00++11) ⇔ Pli00++11(yil00++11) are introduced and every of them is substituted (using the correspondent
unifies) instead of Pli00+1(0 yli00+1) and Pil00++11(yli00++11), respectively, into all formulas of the type Qls such that there is an oriented path from Qls to at least one of them.
If Pli(yli) corresponds to the cell marked as Q21,i1,i1,i2 in Figure 1 then pli00+1(yli00+1) is substituted instead of Pil00+1(yli00+1) into the formulas corresponding the cells marked as Q11,i1, A1 and Ai1. The literal pli00++11(yli00++11) is substituted instead of Pli00++11(yli00++11) into the formulas corresponding the cells marked as Q1i1,i2, Ai1 and Ai2.
The words “using the correspondent unifies” may be explained in such a way. If Pli(yli) corresponds to the cell marked as Q21,i1,i1,i2 in Figure 1 then pli00+1(yli00+1) is substituted instead of Pil00+1(yli00+1) into the formulas corresponding the cells marked as Q11,i1, A1 and Ai1.
The literal pli00++11(yli00++11) is substituted instead of Pil00++11(yli00++11) into the formulas corresponding the cells marked as Q1i1,i2, Ai1 and Ai2
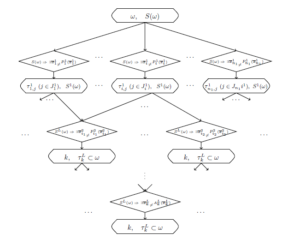
Figure 2: Scheme of level recognition.
It may be easily proved that the problem of level description construction is NP-hard. In particular, the problem of checking if there exists a level description is NP-complete and the upper bounds of number of steps for traditional algorithms exponentially depends on parameters of A1(x1),…, AK(xK). At the same time such a description must be constructed only once and then may be used as many times as you like.
3.2 The Use of Level Description of a Class
Checking for what k the sequence S(ω) ⇒ ∃xk,Ak(xk) is valid and if “yes” then finding for what value of xk it is valid with the use of level description of a class, may be done according to the following algorithm.
- For i = 1,…,n1 check S(ω) ⇒ ∃y1i ,P1i (y1i ) and find all lists of values τ1i,j for the variables y1i such that S(ω) ⇒ Pi1 (τ1i,j).[5]
Let τ1i,j be a notation for the list τ1i,j. All atomic formulas of the form p1i (τ1i,j) with τ1i,j a notation for the list τ1i,j are added to S(ω) to obtain S1(ω) – a 1st level description of ω.
- For l = 1,…, L − 1 do.
- For i = 1,…,nl check S l ) and find all lists of values τli,j for the variables yli such that S l(ω) ⇒ Pli(τli,j).
- All atomic formulas of the form pli(τli,j) with τli,j a notation for the list τli,j are added to S l(ω) to obtain S1+1(ω) – a lth level description of ω.
- – For k = 1,…, K check S L(ω) ⇒ ∃ykL,AkL(ykL) and find all lists of values τkL,j for the variables ykL such that S L(ω) ⇒ AkL(τkL,j).
The object ω satisfies such formulas Ak(xk) for which the corresponding sequence S L(ω) ⇒ ∃ykL,AkL(ykL) is valid.
The scheme of level recognition is presented in Figure 2.
It is proved in [8] that for a two-level description (L = 1) the number of steps with the use of 2-level description decreases. For an exhaustive algorithm the number of steps decreases from O(tmk ) to O(n1 · tr + tδ1k+n1), where r is a maximal number of arguments in the 1st level predicates, n1 is the number of such predicates, δ1k is the number of initial variables which are presented in Ak(xk) and are absent in A1k(x1k). Both parameters r and δ1k + n1 are less than mk.
Number of steps for an algorithm based on the derivation in predicate calculus decreases from O(skak ) to O(s1a1k + Pnj=11 sρ1j ), where ak and a1k are maximal numbers of literals in Ak(xk) and A1k(x1k), respectively, s and s1 are the numbers of literals in S(ω) and S1(ω), respectively, ρ1j is the numbers of literals in P1i (y1i ). Both parameters a1k and ρ1j are less than ak.
So, the recognition of an object with the use of a level description requires less time than that with the use of initial description.
4. Logic-Predicate Network
The inputs of a traditional neuron network are binary or many-valued characteristics of an object. The neuron network configuration is fixed that does not correspond to biological networks.
Below a logic-predicate network is described. Such a network inputs are atomic formulas setting properties of the elements composing an investigated object and relations between them [17], [19]. Further it will be shown that its configuration may be changed during its retraining.
A level description of a class of objects permits quickly enough to recognize an object which description is isomorphic to the description of an element of a training set.
A logic-predicate network consists of two blocks: a training block and a recognition block. Training block forms a level description of a class of objects according to a training set (or some formalized description of the class). Its content is presented in Figure 1.
Recognition block implements the algorithm of the use of level description of a class. It must be marked that the level description may be represented as an oriented graph presented in Figure 2.
Scheme of logic-predicate network is presented in Figure 3. Here inputs and outputs are situated in ovals and checking the conditions are situated in rhombus.
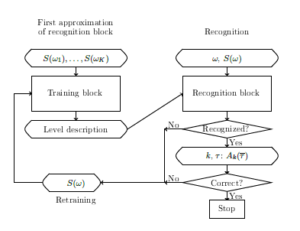
Figure 3: Scheme of logic-predicate network.
Let a training set of objects ω1,…,ωK be given. An initial variant of the class description may be formed by replacement of every constant ωkj in S(ωk) by a variable xkj (k = 1,…, K, j = 1,…,tk) and substitution of the sign & between the atomic formulas. Construct a level description for these goal formulas. The first approximation to the recognition block is formed.
If after the recognition block run an object is not recognized or has wrong classification, then it is possible to retrain the network. The description of the “wrong” object must be added to the input set of the training block. The training block extracts common up to the names sub-formulas of this description and previously received formulas forming a new recognition block. Some sub-formulas, the number of layers and the number of formulas in every layer may be changed in the level description. Then the recognition block is reconstructed.
5. Example of Logic-Predicate Network Construction, its Running and Retraining
Let a set of contour images of “boxes” be to recognize. Every image may be described in the terms of two predicates V and L defined as it is presented in Figure 4.
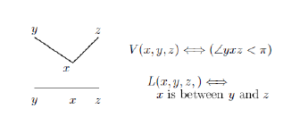
Figure 4: Initial predicates.
A training set {ω1,ω2,ω3} of such images is presented in Figure
- Here ω1 = {a1,…,a10}, ω2 = {b1,…,b8}, ω3 = {c1,…,c10}.
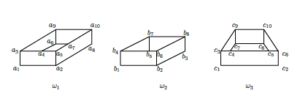
Figure 5: Training set.
In order not to overload the text, we write down only the formula A2(y1,…,y8), which is obtained from the description S(ω2) by replacing the names bi with the variables yi and placing the sign & between the literals.
A2(y1,y2,y3,y4,y5,y6,y7,y8) =
V(y1,y4,y2) & V(y2,y1,y6) & V(y2,y1,y3) & V(y2,y6,y3) & V(y3,y2,y8) & V(y4,y7,y6) & V(y4,y7,y5) & V(y4,y7,y1) & V(y4,y5,y1) & V(y4,y6,y1) & V(y5,y4,y7) & V(y5,y4,y6) &
V(y5,y7,y6) & L(y5,y4,y6) & V(y6,y4,y8) & V(y6,y5,y8) &
V(y6,y8,y2) & V(y6,y2,y5) & V(y6,y2,y4) & V(y7,y4,y5) &
V(y7,y5,y8) & V(y7,y4,y8) & V(y8,y3,y6) & V(y8,y6,y7) & V(y8,y3,y7)
Further, for clarity, we will write down not formulas, but drawings.
5.1 Training Block Run: Extraction of Sub-Formulas
For constructing a level description, find pairwise maximal common up to the names of arguments sub-formulas Q1i (y1i ) of formulas A1(x), A2(y), A3(z) and their unifiers. See Figure 6.
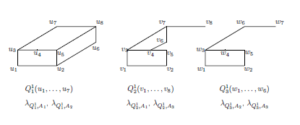
Figure 6: First extraction of pairwise maximal common up to the names of arguments sub-formulas.
Here the following unifier are formed.
Let u1 = (u1,…,u8), v1 = (v1,…,v8), w1 = (w1,…,w7). λQ11,A1 = (u1 → x1,u2 → x2,u3 → x3,u4 → x4,u5 → x5,u6 →
x8,u7 → x9,u8 → x10) = (u1 → x11), λQ11,A2 = (u1 → y1,u2 → y2,u3 → y4,u4 → y5,u5 → y6,u6 →
y3,u7 → y7,u8 → y8) = (u1 → y11), λQ12,A1 = (v1 → x1,v2 → x2,v3 → x3,v4 → x4,v5 → x5,v6 →
x6,v7 → x9,v8 → x10) = (v1 → x21), λQ12,A3 = (v1 → z1,v2 → z2,v3 → z3,v4 → z4,v5 → z6,v6 →
z7,v7 → z9,v8 → z10) = (v1 → z11),
λQ31,A2 = (w1 → y1,w2 → y2,w3 → y4,w4 → y5,w5 → y6,w6 → y7,w7 → y8) = (w1 → y12), λQ31,A3 = (w1 → z1,w2 → z2,w3 → z3,w4 → z4,w5 → z6,w6 → z9,w7 → z10) = (w1 → z12).
Pairwise extractions of maximal common up to the names of arguments sub-formulas of Q11(u1,…,u8), Q12(v1,…,v8) and Q13(w1,…,w6) give only just obtained formula Q13(w1,…,w6). That’s why we have a situation presented in Figure 7.
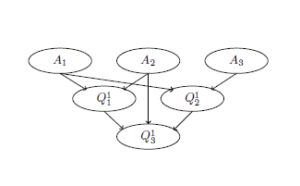
Figure 7: Connections between the extracted formulas.
5.2 Training Block Run: Forming a Level Description
The formula Q13(w1,…,w7) has no common sub-formulas with the other ones. Therefore, it is the 1st level predicate P11(w1,…,w7) of the network. A new 1st level predicate p11(w1) defining as p11(w1) ⇔ P11(w1,…,w7) is introduced. Remind that w1 is a new 1st level variable for the string of initial variables (w1,w2,w3,w4,w5,w6,w7).
Formula P11(w1,…,w7) (which corresponds to Q13(w1,…,w7)) is on the end of edges from A2(y1,…,y8), Q11(u1,…,u8) and Q12(v1,…,v8) in Figure 7. The unifier of P11(w1,…,w7) with A2(y1,…,y8) coincides with λQ13,A2 obtained above.
The unifiers of P11(w1,…,w7) with Q11(u1,…,u8) and Q12(v1,…,v8) are the following.
λP11,Q11 = (w1 → u2), where u2 = (u1,u2,u3,u4,u5,u7,u8). λP11,Q12 = (w1 → v2), where v2 = (v1,v2,v3,v4,v5,v7,v8).
The formulas Q11(u1,…,u8) and Q12(v1,…,v8) with the substitutions of p11(u1) and p11(v1), respectively, instead of sub-formulas isomorphic to P11(w1,…,w7) will form the 2nd level of the network and are denoted by P21(u1,…,u8;u1) and P22(v1,…,v8;v1).
It must be marked that if we know the value of the 1st level variable u1 then we know the values of (u1,u2,u3,u4,u5,u7,u8). That’s why the essential variables of P21(u1,…,u8;u1) are (u6;u1). Similarly the essential variables of P22(v1,…,v8;v1) are (v6;v1).
New 2nd level predicates p21(u2) and p22(v2) defining as p21(u2) ⇔ P21(u1,…,u8;u1) and p22(v2) ⇔ P22(v1,…,v8;v1) are introduced.
Taking into account only essential variables and earlier received unifiers we have the last layer formulas.
A21,1(x7; x1, x12), where x1 = (x1, x2, x3, x4, x5, x8, x9, x10), x12 = (x6; x1).
A21,2(x7; x1, x22), where x1 = (x1, x2, x3, x4, x5, x8, x9, x10), x22 = (x6; x1).
A22,1(;y1,y21), where
y1 = (y1,y2,y4,y5,y6,y7,y8), y21 = (y3,y8;y1).
A22,2(y3y7;y1), where y1 = (y1,y2,y4,y5,y6,y7,y8).
A23(z5,z8;z1,z2), where z1 = (z1,z2,z3,z4,z6,z9,z10), z2 = (z4,z7;z1).
The contents of the last layer cells are the following:
5.3 Recognition Block Run
The recognition block is formed according to the level description constructed in the previous subsection. The scheme of recognition block is presented in Figure 8. In this scheme only names of a checking formula and results of checking are written down.
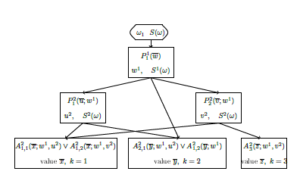
Figure 8: Predicate network.
It is obvious that if an input object ω is isomorphic to one from the training set, then it will be recognized. It means that the number k and such a permutation ω of ω that S(ω) ⇒ Ak(ω) will be found.
Let a control object with the description not isomorphic to anyone from the training set is to be recognized. Such a control object {d1,…,d8} is presented in Figure 9.
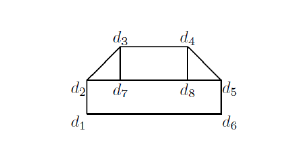
Figure 9: Control object.
Checking S ) in the first layer (see Figure 8) gives us w = (d1,d6,d2,d7,d5,d3,d4). A new 1st level variable w1 takes this list of constants as a value. Add new atomic formula to S(ω) and obtain S .
Neither P ) or P ) are a consequence of S1(ω) be-cause, in fact, 7 variables in u and v are changed by constants from w1.
This control object is not recognized.
5.4 Retraining the Network
Let’s retrain the network with the object presented in Figure 9.
Replace every constant di (i = 1,…,8) in its description by a variable xi and substitute the sign & between the atomic formulas. The formula A4(x) is obtained.
Pairwise checking of partial sequence between A4(x) and Aj(xj) (j = 1,2,3) permits to obtain maximal common up to the names of arguments formulas Q14, Q15 and Q16. The images of thees fragments are shown in Figure 10.
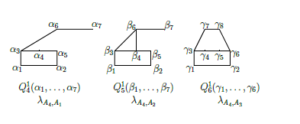
Figure 10: Pairwise extraction of maximal common up to the names of arguments sub-formulas between A4(x4) and Aj(xj) (j = 1,2,3).
One of the obtained formulas (formula Q14(α1,…,α7)) is isomorphic to the earlier obtained formula Q13(w1,…,w7). That’s why it would not be added to the 2nd layer of the retrained network. But all its connections with the cells of another layers would be saved.
Pairwise checking of partial sequence between Q15, Q16 and Q1j(x1j) (j = 1,2,3) does not give any new formulas.
So, the 1st layer would have only the formula Q13(w1,…,w7) renamed as P11(w1,…,w7).
On the 2nd layer the cell with formula P24(β;w1) and output t2 and the cell with formula P25(γ;w1) and output r2 would be added on the end of the edge from the cell with P11(w). Edges from these cells to the cells with A2j(xj; x1j, x2j) (j = 1,2,3) would be added as it is shown in Figure 11.
Figure 11: Pairwise extraction of maximal common up to the names of arguments sub-formulas between A4(x4) and Aj(xj) (j = 1,2,3).
The network is retrained.
It should be noted that the examples of images discussed in the article are taken from [3]. The original predicates W, Y and T in that book for describing the images differ from the predicates V and L used here. This is due to the fact that W, Y and T are expressed in terms of the predicates V and L and do not significantly reduce the computational complexity of recognition when constructing a level description.
Both {W, Y, T} and {V, L} are not enough to describe real images of “boxes”. So, for example, the description of the image in Figure 12 is isomorphic to the description of A2(y1,…,y8), but you need to have a rich imagination to guess the box in it. The choice of initial predicates in each specific problem should be chosen very carefully.
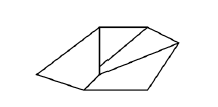
Figure 12: Is it a box?
Here we do not consider an example when, while retraining the network, not only additional cells in a layer appear, but the number of layers also changes. This could be done by retraining the network using the example of a mirror (relative to the vertical axis) image of an object from the training set. In this case, rectangle recognition will appear in the 1st layer. The contents of the remaining cells will also be changed.
6. Fuzzy Recognition by a Logic-Predicate Network
The disadvantage is that the proposed logic-predicate network does not recognize objects with descriptions that are not isomorphic to the descriptions that participate in its formation. This can be eliminated by slight modifications of the network.
Further the ith cell of the lth level will be denoted as cellil.
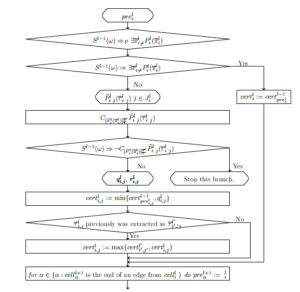
Figure 13: The fuzzy network ith cell of the lth level contents.
Let’s change the contents of the network cells presented in Figure 2 by replacing the checking of S l−1(ω) ⇒ ∃xli,Pli(xli) in the cellil with the partial sequence checking S l−1(ω) ⇒P ∃xli,Pli(xli). The degree of coincidence of a recognized object with the description of a class and the degree of recognition correctness certainty is calculated during partial sequence checking.
For a fully identified object, both of these degrees equal to 1. For an object from a given class for which these degrees are essentially small (this is determined by an expert), you can still retrain the network.
A fuzzy network has two additional parameters:
certil (l = 0,…, L, i = 1,…,nl) – a degree of certainty in the correctness of recognition by the cellil;
preli ( l = 1,…, L, i = 1,…,nl) – the cell number of a cell preceding the cellil in the current traversal of a network. The cell0 number has the form lj , where l0 is the number of a layer and j is the number of a cell in this layer Initially, cert10 := 1, pre1i := 01 (i = 1,…,n1).
The scheme of cellil contents of a fuzzy network is presented in Figure 13.
First of all, a partial sequence S l−1(ω) ⇒P ∃xli,Pli(xli) is checked in this cell. If this sequence is not partial but total, then the parameter certil is not changed and the calculation goes to the end of the cell.
Otherwise, all lists of constants τli j and maximal not contradictory on τli j with S l−1(ω) sub-formulas Peli j(xli j) of the formula Pli(xli) are found while partial sequence checking.
If the sub-formulas Peli j(xli j) is contradictory to the description S(ω) on the list of the found constants, then this recognition branch stops.
Remind that S(ω) and C[Pli(xli)]τx0 Peli j(τli j) are in the contradiction means that S(ω) ⇒ ¬C[Pli(xli)]τx0 Peli j(τli j), where C[Pli(xli)]τx0 Pei jl (τi jl ) is a complement (conjunction of literals from Pli(xli) which are not in Peli j(xli j)) of Peli j(xli j) up to Pli(xli).[6]
Parameters qli j and ri jl [7] are calculated with the use of the full form of formulas Pli(xli) and Peli(yli), i.e., with the replacement in them of each atomic formula of the levels l0 (l0 < l) by the defining elementary conjunction.
Except this, a degree of certainty certil that the recognition would be valid is calculated in every cell. While first visit to the cellil the value of certil will be certil := min{cert1pre−1li ,qli}. This corresponds to conjunction of degrees of certainty while successive passage along one branch of network traversal.
While next visit of the cellil the value of certil will be certil := max{certil,min{cert1pre−1li ,qli}}. This corresponds to disjunction of degrees of certainty while parallel passage along different branches of network traversal.
Why can we visit a cell not only once? For example, in Figure 11 the 3rd layer cell with A21 may be visited by a path including the cells with P11, P21 and A21 and by a path including the cells with P11, P22 and A21.
In the last layer of the network, objects τkL would be received and for each object the degree of certainty qkL, that it is the rkLth part of an object satisfying the description Ak(xk), would be calculated.
A flowchart of fuzzy recognition network can not be presented in the paper because it is very large. It consists of the “Scheme of logic-predicate network” shown in Figure 3, in which instead of the “Training block” the “Scheme of common up to the names of
arguments sub-formulas extraction” (Figure 1) is inserted, and the “Scheme of level recognition” (Figure 2) is inserted instead of the “Recognition block”. At the same time, in Figure 2, each element enclosed in a rhombus is replaced by “The fuzzy network ith cell of the lth level contents” (Figure 13).
7. Model Example of Fuzzy Recognition
Let’s look how a fuzzy network (corresponding to that constructed in the section 6 and presented in Figure 8) recognizes the control object presented in Figure 9.
To recognize it, a partial sequence S(d1,d2,…,d8) ⇒P ,…,w6) is checked in the 1st layer. There is a total sequence and the 1st level variable w1 = (w1,w2,w3,w4,w5,w6,w7) takes the value (d1,d6,d2,d7,d5,d3,d4). cert11 := 1, pre21 := 11, pre22 := 11, pre32 := 11.
The result of the 1st layer fuzzy cell run is presented in Figure 14.[8]
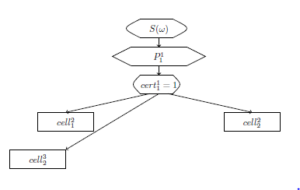
Figure 14: The result of the 1st layer fuzzy cell run.
In the 2nd layer, partial sequence S1(d1,d2,…,d8,w1) ⇒P ) is checked. It must be noted that in fact S1(d1,d2,…,d8,w1) ⇒P ∃u ) is checked. That is, there is only one variable at the right-hand side of the formula.
Since we need to check formulas for consistency, we note that V(x,y,z) ⇒ ¬V(x,z,y).
There is only a partial sequence. A formula P˜21(d1,d6,d2,d7,d5,d3,d4;w1) is the maximal sub-formula such that S1(d1,d2,…,d8,w1) ⇒ P˜21(d1,d6,d2,d7,d5,d3,d4;w1). Its complement up to P21(d1,d6,d2,d7,d5,d3,d4,u6;w1) contains three literals with predicate V, one of them is V(u6,d4,d6). This contradicts S1(d1,d2,…,d8,w1) containing V(u6,d6,d4). This branch of the network stops.
There is another cell in the 2nd layer on the end of an edge from cell11. This is cell22. Check partial sequence S1(d1,d2,…,d8,w1) ⇒P ). In fact, S1(d1,d2,…,d8,w1) ⇒P ) is checked.
There is only partial sequence. A formula P˜22(d1,d6,d2,d7,d5, v6,d3,d4;w1) is the maximal sub-formula such that S1(d1,d2,…,d8,w1) ⇒ P˜ ). Its complement up to P ) contains 5 literals with predicate V V(v6,d7,d3), V(d3,v6,d2), V(d7,v6,d2), V(d7,d8,v6), V(d7,d5, v6) and 3 literals with predicate L
L(d7,d2,d8), L(d8,d2,d5), L(d8,d7,d5), but no one of them is in contradiction with S1(d1,d2,…,d8,w1). The value of v2 is (v6;w1).
It means that one 1st level variable v6 does not take value.
The number of literals in P22(v1 …v8;w1) (taking into account its full form in which the 1st level predicate is changed by the defining formula only with initial variables) is a22 = 16. The number of literals in P˜22(d1,d6,d2,d7,d5,v6,d3,d4;w1) is ˜a22 = 8.
That’s why q22 = = and cert22 := min{1, } = .
There are two edges from the cell with P22 to the 3rd layer cells with A21,2 and with A23. That’s why pre31 := 22, pre33 := 22.
The result of the 2nd layer fuzzy cells run is presented in Figure 15.
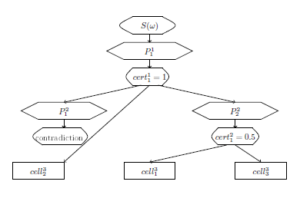
Figure 15: The result of the 2nd layer fuzzy cell run.
In the 3rd layer while going from the cell with P11 to the cell23 with A22,1 partial sequence S1(d1,…,d8;w1) ⇒P ) is checked. In fact, a partial sequence S1(d1,…,d8;w1) ⇒P ) with the only one initial variable y3 is checked.
There is only a partial sequence. The same string of values for variables in v2, as it was in the second layer, partially satisfies A ). But the description of this fragment has two additional literals V(d7,d2,d3) and V(d7,d3,d5).
The number of literals in A2(y1 …y8; v1) is a2 = 22. The number of literals in A˜21,2(y1 …y8;v1,v2) is a˜21,2 = 10. That’s why q 455 and cert
While going from the cell with P22 to the cell13 with A21,2 partial sequence S2(d1,d2,…,d8;v1,v2) ⇒P ) is checked. In fact S2(d1,d2,…,d8;v1,v2) ⇒P , v7,v8,d3,d4;v1,v2) with 3 initial variables v6, v7, v8 is checked.
There is only a partial sequence. The same string of values for variables in v2, as it was in the second layer, partially satisfies A21,2(v1 …v10;v1,v2).
The number of literals in A1(x1,…, x10) is a1 = 34. The number of literals in A˜ ) is a˜ 8. That’s why235 and cert While going from the cell with P cell23 with A23 partial sequence S2(d1,d2,…,d8;v1,v2) ⇒P is checked. In fact S2(d1,d2,…,d8;v1,v2) ⇒P ) with 2 initial variables z7, z8 is checked.
There is only a partial sequence. The variables z7, z8 have not taken values. All literals with these variables are absent in A˜23(d1,d6,d2,d7,d8,d5,z7,z8,d3,d4;v1,v2). The number of such literals is 14.
The number of literals in A is a3 = 32. The number of literals in A˜ ) is a˜ 18. That’s why q 563 and cer The full degree of certainty that it is a representative of the class of “boxes” that is given as a control image is cert =
Moreover, elements of this image coincide with elements of the image ω3 from the training set.
The result of the fuzzy network run is presented in Figure 16.
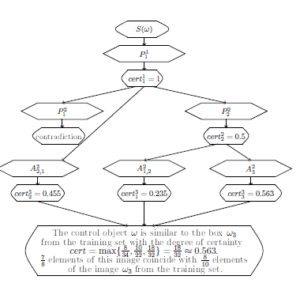
Figure 16: The result of the fuzzy network run.
8. Results and Discussion
The main result of this article is the proposal of fuzzy recognition of complex structured objects by logic-predicate network. For a detailed presentation of this result, it was necessary to describe in detail a logic-predicate approach to the recognition of complex structured objects.
A significant disadvantage of this approach is that the problems arising are NP-hard, which to a large extent “scares off” some researchers. On the other hand, the use of predicate logic does not always seem legitimate, since the propositional logic is much simpler for understanding by non-mathematicians.
The use of level descriptions is not something essentially original to decrease the computational complexity of the main problem. It is a well-known technique in which sufficiently complex problems are divided into a sequence of problems of the same type of lower dimension. The main problem was HOW to build such a description. To this end, the mathematical apparatus for extracting the general sub-formulas of two elementary conjunctions of predicate formulas was developed and briefly presented in this paper.
Based on the level description of classes, it was possible to formulate the concept of a logic-predicate network. Unlike existing networks, for example, neural or Bayesian, when retraining such a network, a logic-predicate network can (and, as a rule, this happens) change its configuration. This corresponds to the training of a person in whose brain connections between one neural cells break and connections between others arise.
This is one of the essential features of the proposed approach, which distinguishes it from the use of various other networks. Its other essential feature is to calculate the degree of coincidence of the object being recognized with those ones for which the network was trained.
A trained logic-predicate network quickly recognizes objects with descriptions that are isomorphic to the ones on which it was trained. But its training and retraining processes remain to be NPhard. This corresponds to the process of teaching a person. But in some cases, it is not necessary to accurately recognize an object or process, but to find out what it looks like and to what extent.
To answer such a question, the concept of a fuzzy logic-predicate network was proposed. The structure of its cell, shown in Figure 13, is quite complex and contains a partial sequence check. Such verification is NP-hard, but after repeated retraining of the network, the formulas Pli(xli), setting intermediate goal formulas, are quite short and have a small number of essential arguments, as it was shown by the example in section 7. This means that an exponent of the computational complexity of the partial sequence check is a fairly small value.
Special importance has the choice of “good” initial features. As already mentioned in Subsection 5.4, the predicates W, Y and T, which were used to describe contour images in [3], do not give a good decreasing of computational complexity for the logic-predicate network, constructed from them. Apparently, this is due to the fact that they reflect the perception of a person and are essentially composite.
9. Conclusion
In development of the proposed approach, many-valued predicates may be considered. Especially this relates to the properties of an object elements. Such multi-valued predicates p(x) = a with a ∈ D can be interpreted as binary ones with a numerical argument: q(x;a) ⇔ p(x) = a. The inclusion of such predicates in the formulation of the problem may serve as the subject of further research.
It is also planned to consider the possibility of introducing cell weights in a logic-predicate network. Such weights can be determined depending on the frequency with which parts of an object description satisfy the formula checked in the corresponding cell. Other weighting strategies are possible, similar to strategies for determining the cell weights of a classical artificial neural network.
In addition, if in the problem setting global features of the object that characterize the entire object are considered, then such an object is usually described by a binary or multi-valued string. Class descriptions can be presented as a propositional formula in disjunctive normal form. Extraction the “frequently encountered” sub-formulas of such propositional formulas [24] allows to form a level description of classes. Using this description in a manner similar to that described in this article, it is possible to build a logicalgebraic network, which changes its configuration in the process of learning. This corresponds to a change of connections in biological neural networks.
Acknowledgments
The author is grateful to Vakhtang Kvaratskhelia from Muskhelishvili Institute of Computational Mathematics of the Georgian Technical University, whose question at the conference in 2017 allowed this paper to be born. The author thanks the anonymous referees for their useful suggestions.
- T. Kosovskaya . “Implementation of Formula Partial Sequence for Rough Solution of AI Problems in the Framework of the Logic-Predicate Approach” in 2019 Computer Science and Information Technologies (CSIT),Yerevan,
Armenia, 2019. https://doi.org/10.1109/CSITechnol.2019.8895153 - N. J. Nilson, Problem-solving methods in Artificial Intelligence, McGraw-Hill Book Company, 1971.
- R. Duda, P. Hart, Pattern Classification and Scene Analysis, John Wiley & Sons, 1973.
- E.B. Hunt, Artificial Intelligence, Academic Press, 1975.
- M.R. Garey, D.S Jonson, Computers and Intractability: A Gide to the Theory of NP-Completeness, W.H. Freeman and Company, 1979.
- S. Russell, P. Norvig, Artificial Intelligence: A Modern Approach, Third edition, Prentice Hall Press Upper Saddle River, 2009.
- T.M. Kosovskaya. ”Estimating the number of steps that it takes to solve some problems of pattern recognition which admit logical description” in VESTNIK ST PETERSBURG UNIVERSITY-MATHEMATICS, 40(4), 82–90, 2007. (In Russian) https://doi.org/10.3103/S1063454107040061
- T.M. Kosovskaya, ”Multilevel descriptions of classes for decreasing of step number of solving of a pattern recognition problem described by predicate cal- culus formulas” VESTNIK SANKT-PETERBURGSKOGO UNIVERSITETA SERIYA 10 PRIKLADNAYA MATEMATIKA INFORMATIKA PROTSESSY, 1, 64–72 (2008). (In Russian)
- T.M. Kosovskaya, ”Partial deduction of predicate formula as an instru- ment for recognition of an object with incomplete description” VESTNIK SANKT-PETERBURGSKOGO UNIVERSITETA SERIYA 10 PRIKLAD- NAYA MATEMATIKA INFORMATIKA PROTSESSY, 1, 74–84, 2009. (In Russian) https://doi.org/10.24412/FgeTsEutG6w
- T.M. Kosovskaya, “Partial Deduction in Predicate Calculus as a Tool for Artificial Intelligence Problem Complexity Decreasing” in 2015 IEEE 7th International Conference on Intelligent Computing and Information Systems,
ICICIS 2015, 73–76, 2016. https://doi.org/10.1109/IntelCIS.2015.7397199 - J. Schmidhuber, “Deep learning in neural networks: An overview” Neural Networks, 61, 85–117, 2015. https://doi.org/10.1016/j.neunet.2014.09.003
- T. Chunwei, X. Yong, Z. Wangmeng, “Image denoising using deep CNN with batch renormalization” Neural Networks, 121, 461–473, 2020. https://doi.org/10.1016/j.neunet.2019.08.022
- E.H. Dawn, C. J. Lakhmi (Eds), Innovations in Bayesian Networks. Theory and Applications, Springer-Verlag, 2008. https://doi.org/10.1007/978-3-540-85066-3
- R. Agrahari, A. Foroushani, T.R. Docking et al. “Applications of Bayesian network models in predicting types of hematological malignancies”, Sci Rep 8, 6951 (2018). https://doi.org/10.1038/s41598-018-24758-5
- A. Tulupiev, C. Nikolenko, A. Sirotkin, Bayesian Networks: logic-probabilistic approach, Nauka, 2006. (in Russian)
- A. Shahzad, R. Asif, A. Zeeshan, N. Hamad, A. Tauqeer, “Underwater Resur- rection Routing Synergy using Astucious Energy Pods” Journal of Robotics and Control (JRC), 1(5), 173–184, 2020. https://doi.org/10.18196/jrc.1535
- T. Kosovskaya, “Self-modificated predicate networks” International Journal on Information Theory and Applications, 22(3), 245–257, 2015.
- T. Kosovskaya, “Fuzzy logic-predicate network” in Proceedings of the 11th Conference of the European Society for Fuzzy Logic and Technology (EUSFLAT 2019), Part of series ASUM (Atlantis Studies in Uncertainty Modeling), 1, 9–13, 2019. https://doi.org/10.2991/eusflat-19.2019.2
- T. Kosovskaya, “Predicate Calculus as a Tool for AI Problems Solution: Algorithms and Their Complexity”, 1–20. 2018. Chapter 3 in “Intelligent System”, open-access peer-reviewed Edited volume. Edited by Chatchawal Wongchoosuk Kasetsart University https://doi.org/10.5772/intechopen.72765
- T. M. Kosovskaya, N. N. Kosovskii, “Polynomial Equivalence of the Problems Predicate Formulas Isomorphism and Graph Isomorphism” VESTNIKST PETERSBURG UNIVERSITY-MATHEMATICS, 52(3), 286–292, 2019.
https://doi.org/10.1134/S1063454119030105 - T.M. Kosovskaya, “Some artificial intelligence problems permitting formalization by means of predicate calculus language and upper bounds of their solution steps” SPIIRAS Proceedings, 14, 58–75, 2010. (In Russian) https://doi.org/10.15622/sp.14.4
- T. M. Kosovskaya, D. A. Petrov, “Extraction of a maximal common sub-formula of predicate formulas for the solving of some Artifi- cial Intelligence problems” VESTNIK SANKT-PETERBURGSKOGO UNIVERSITETA SERIYA 10 PRIKLADNAYA MATEMATIKA INFORMATIKA PROTSESSY, 3, 250–263, 2017. (In Russian) https://doi.org/10.21638/11701/spbu10.2017.303
- T. Kosovskaya, “Construction of Class Level Description for Efficient Recognition of a Complex Object” International Journal “Information Content and Processing”, 1(1), 92–99, 2014.
- D.A. Koba, “Algorithm for constructing a multi-level description in pattern recognition problems and estimating the number of its run steps” in Proceedings of the XVII International School-Seminar “Synthesis and Complexity of Control Systems” named after Acad. O.B. Lupanov (Novosibirsk, October 27 – November 1, 2008), Publishing House of the Institute of Mathematics, Novosibirsk, 55–59, 2008. (In Russian)