Human-Robot Multilingual Verbal Communication – The Ontological knowledge and Learning-based Models
 , Intissar Salhi 1, Hanaâ El fazazi 1, Khalifa Mansouri 1, Michail Manios 2, Vassilis Kaburlasos 2
, Intissar Salhi 1, Hanaâ El fazazi 1, Khalifa Mansouri 1, Michail Manios 2, Vassilis Kaburlasos 2
Adv. Sci. Technol. Eng. Syst. J. 5(4), 540–547 (2020);
 DOI: 10.25046/aj050464
DOI: 10.25046/aj050464
In their verbal interactions, humans are often afforded with language barriers and communication problems and disabilities. This problem is even more serious in the fields of education and health care for children with special needs. The use of robotic agents, notably humanoids integrated within human groups, is a very important option to face these limitations. Many scientific research projects attempt to provide solutions to these communication problems by integrating intelligent robotic agents with natural language communication abilities. These agents will thus be able to help children suffering from verbal communication disorders, more particularly in the fields of education and medicine. In addition, the introduction of robotic agents into the child’s environment creates stimulating effects for more verbal interaction. Such stimulation may improve their ability to interact with pairs. In this paper, we propose a new approach for the human-robot multilingual verbal interaction based on hybridization of recent and performant approach on translation machine system consisting of neural network model reinforced by a large distributed domain-ontology knowledge database. We have constructed this ontology by crawling a large number of educational web sites providing multi-lingual parallel texts and speeches. Furthermore, we present the design of augmented LSTM neural Network models and their implementation to permit, in learning context, communication between robots and children using multiple natural languages. The model of a general ontology for multilingual verbal communication is produced to describe a set of linguistic and semantic entities, their properties and relationships. This model is used as an ontological knowledge base representing the verbal communication of robots with children.
1. Introduction
The great evolution of the theories and tools of artificial intelligence in addition to the technological achievements in the field of industrial robotics have contributed to the advent of intelligent robots endowed with physical as well as intellectual capacities. The efficient and rational integration of this kind of intelligent robots in real working environments in the presence of human beings is always a challenge and an important objective for the engineer as well as for the scientist. Several fields and sectors of application are directly concerned by this integration and consider it very promising for greater productivity and efficiency. Among these areas are mainly the industrial sectors and to a lesser but growing extent the education and health sectors. Especially for the education and health sectors, the most important aspect that determines the success or failure of this integration is the capacity for verbal interaction between humans and these intelligent robots. Indeed, verbal exchanges for these two sectors are essential for students’ learning activities and for exchanges with patients during medical procedures. Verbal exchanges are even more important in the case of students or patients with special needs and especially in the case of autistic children.
This research work is part of this context and aims to produce generic models representing a solution to the problem of verbal interaction of intelligent robots with several groups of children who use different natural languages. We also provide an implementation and experimentation of these models by considering the case of three natural languages most formally used in the geographical area of North Africa in this case Arabic, French and English. Our models will allow a smart robot to be able, in real time, to detect and communicate in the natural language of the children in front. This will be of great use for teachers or tutors to carry out collaborative learning activities in which the robot will have the role of teacher, tutor or even of student.
The paper is outlined in a way that Section 2 gives a survey on human-robot interaction systems. The section 3 explains our architecture model that illustrate the main three transformation modules the robot must have to interact with humans in multiple natural languages. The three modules that compose the whole system have also been discussed. Section 4 give the details on the first module especially the description of the data structure used, a scraping approach we developed to extract the expected data of parallel text and audio corpus mainly as JSON file format. The end of this section provides the Extract-Transform-Load model describing the mapping operations of data and metadata from the corpus to the ontology database. In section 5, we show how we can improve the performance of the translation machine algorithm based on our ontological knowledge base. Section 6 provides a conclusion on the different aspects of our models and ends with a critical discussion in order to identify new avenues for future research.
2. Survey on Human-Robot interaction
2.1. Classes of Human-Robot interaction
In a common work environment, an intelligent robot can have two types of interaction with humans [1]: verbal or non-verbal. The first interaction form covers the production of emotions or meaning without use of words or speech but using only facial or body gestures. On the other hand, the second form necessarily involves the use of natural language expressions in the orally and/or written forms.
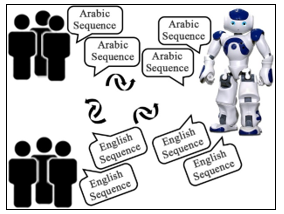 Figure 1: Human-Robot multilingual verbal communication
Figure 1: Human-Robot multilingual verbal communication
Figure 1 illustrates the key idea of our work where an intelligent robot is called to allow real-time verbal exchanges between two or more groups not speaking the same language and having to share a common experience of learning or therapy. The robot thus plays the role of mediator and communication interface between the different groups.
2.2. Overview of research findings on oral interactions between robotic agents and humans
In the last decade, several high-quality research studies have been conducted on problems related to the oral communication possibilities between robots and humans. This period was marked by a significant number of articles indexed in this area. The study of these references revealed the main guidelines relating to our work and the following three research areas namely: (1) smart robotics and cognitive [2]-[6], (2) knowledge systems and (3) ontological databases [7]-[10] and artificial intelligence and machine learning techniques [11]-[16].
These research works highlight the inability of conventional robotic systems to respond to rapid changes in technical and functional production requirements. They present as a solution to these problems, the introduction of cognitive robots in the production lines. These robots while being able to adapt quickly, they are also able to interact and collaborate with human operators.
3. General architecture for robot-human communication in multi-language context
3.1. Block diagram of our proposal system
Figure 2 describes our general-purpose showing that robot-human interactions pass essentially through four modular units: the control unit, the perception unit, the knowledge data management system and the multilingual communication interface including text and speech sequences. This last unit contains all the transformations applied to the input signals collected by the robot’s exchange unit. The knowledge base unit gives the semantic support of the different transformations for the synthesis of the robot reactions. This last unit contains all the transformations applied to the input signals collected by the exchange units of the robot. The knowledge management unit provides the semantic support for these transformations for the synthesis of the robot’s reactions.
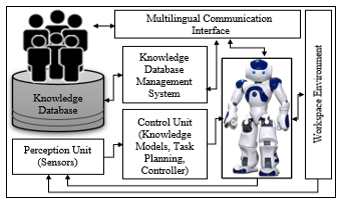 Figure 2: Block diagram of the proposed Human-Robot interaction system
Figure 2: Block diagram of the proposed Human-Robot interaction system
3.2. Systemic model of verbal communication of robots based on an ontological knowledge database
The diagram in the figure 3 provides an integrated systemic representation of our approach which is built up into three large independent parts, namely: (A) the devoted part for the construction and updating the text and audio parallel corpus links to the expandable list of languages, (B) the second part consisting in decisive phase which constitutes a driving force of construction and extension of our ontological knowledge database by the discovery of the entities and the relationships which connect them as well as their properties[10]. This engine also has the role of extracting all the occurrences associated with the entities found. (C) the third part constitutes the system of language identification, speech recognition and text translation.
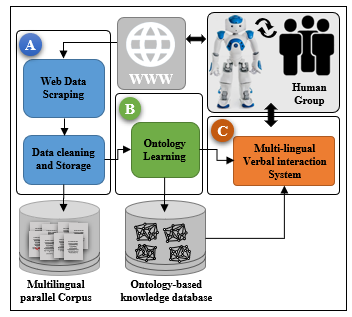 Figure 3: Architectural model of Human-Robot interaction system
Figure 3: Architectural model of Human-Robot interaction system
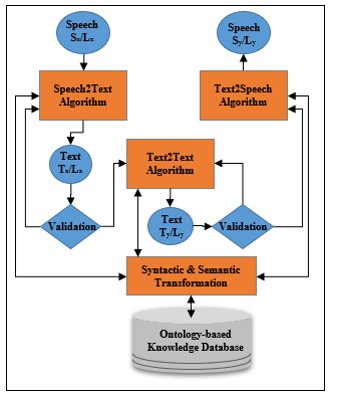 Figure 4: General model for Human-Robot multilingual verbal interactions
Figure 4: General model for Human-Robot multilingual verbal interactions
3.3. Specification diagram of Speech2speech algorithm using knowledge database
The objective of this module is the transformation of a given speech Sx, expressed in a language Lx, into an equivalent speech Sy expressed in another language Ly. This transformation is necessary to guarantee the exchange in a multi-language context. We have decomposed this transformation into three successive operations: (1) “Speech2Text”: the transformation of the speech Sx into an equivalent text Tx and expressed in the same language Lx. (2) the transformation of the text Tx into an equivalent text Ty expressed in the language Ly and, (3) the transformation of the text Ty into an equivalent speech Sy expressed in Ly.
Figure 4 describes the sequence of the three operations and shows their relationship to the ontological knowledge management system. These operations are all based on the use of machine learning algorithms trained and validated by a high-quality dataset of parallel speeches and texts for the Arabic, French and English languages. The knowledge system also serves as a storage base [17] for all conversations collected or generated by the system.
3.4. Model of speech recognition and ontology-based tagging
Figure 5 describes the most complicated transformation in our system. It is carried out in five phases: firstly phase (1) dedicated to the pre-processing of the input speech in order to eliminate possible crudes by the application of filters and to segment it into pieces thanks to the application of techniques detection of breaks, framing and windowing. A second phase (2) consists of the application of an algorithm for identifying the language of speech. The results of these two phases are used by phase (3) which transforms each segment into a sequence of words thanks to the use of a neural network of the “multi-layer perceptron” type. semantic and contextual integration represents phase (4) and makes it possible by analysis and discovery of the semantic relationships provided by the ontological knowledge base. this completeness of the generated text also allows phase (5) to associate a set of tags with the speech that has just been processed.
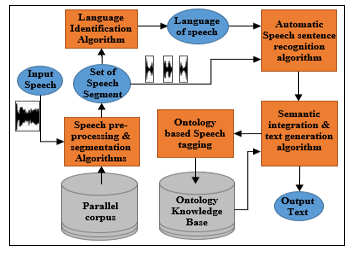 Figure 5: Speech recognition and text generation models
Figure 5: Speech recognition and text generation models
3.5. Language identification algorithm
The identification of the language of a speech is often done by selecting and analyzing a piece of this speech as reported in [8] and [18]. As reported in [11]-[13] and [19], this identification may be done by a classification algorithm based on the automatic learning of a “deep neural network” trained using a multi-language speeches dataset recorded for several speakers. For its simplicity and the precision of its results, we chose the use of a classification algorithm based on the learning of a recurrent neural network (RNN) [20]. This learning is done on a large number of features generated by an extraction function based on the knowledge base.
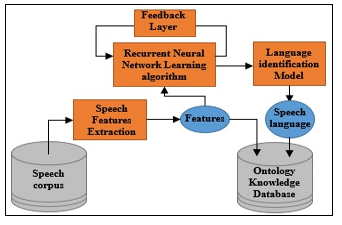 Figure 6: Ontology-based identification of the speech language
Figure 6: Ontology-based identification of the speech language
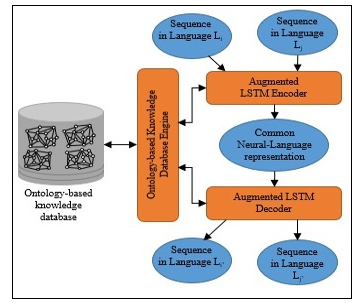 Figure 7: augmented LSTM Seq2Seq using ontology
Figure 7: augmented LSTM Seq2Seq using ontology
To implement and test the models proposed in figures 5 and 6, we chose to create components programmed in Python and this for the range of these standard libraries in the fields of numerical calculation, machine learning and the field of processing of natural languages [21]. To define the corpus of speeches and parallel texts for the three languages considered, we identified a large list of websites offering free multilingual resources such as multilingual newspapers, online and multilingual tv channels, podcasts in lines in addition to forums and tweets of thematic conversations.
3.6. Text to Text Translation
Several works on the problem of automatic translation machine have been published. The most recent have adopted machine learning based on LSTM neural networks model with variants obtained by adding additional layers in order to improve the translation accuracy. Among recent approaches, we can notably cite “tree LSTM based methods with attention [14] and LSTM based methods with transformers [15]-[16]. As depicted in figure 8, our approach is based on the latest model whose learning is improved by the addition of a “labeling” module and reduction of the training dataset thanks to our ontological knowledge base.
The figure 7 describes the translation machine process in two steps and their interaction with the ontological knowledge database through the ontological engine. Thus, the input sequence message expressed in language Li is first encoded based on Long Short-Term Memory (LSTM) networks augmented algorithm [22] in a common representation that is independent to the source and the target languages. The second step performs the decoding in the target language according the second step of LSTM algorithm.
4. Ontology-based knowledge data representation
4.1. Ontology capabilities and usage
The formal modeling of knowledge on a field of activity and the representation of dependency relationships between its elements has always been a means expected by both engineers and scientists [23]. This modeling makes it possible to structure knowledge to serve as a knowledge base allowing to carry out new analytical studies and validate theories [10]. Among the models widely adopted by researchers stand out the ontological models. moreover, ontological models have a great capacity to represent semantic and contextual aspects relating to a domain [24]-[25]. Ontologies have an extensive use in Web applications where they are been considered as source of semantics with a rich and formal representations.
Thanks to these representations a large possibility in terms of reasoning mechanisms and, manipulation of data and metadata are possible [4]. For all these advantages, the ontological models are adopted in the fields of cognitive robotics and that of artificial intelligence. These possibilities also allow the management of knowledge relating to collaboration between robots and humans through verbal communication [7]. In this research work, we exploit all these possibilities through a domain ontology, as illustrated in figure 8, to serve as a model of a knowledge base for Human-Robot interaction system. This model should allow domain hierarchization into interest sub-domains (education, health, specific education, therapy, …) [26]. Our model also provides the linguistic entities for natural language processing operations we have defined in section 3. We adopted OWL language to create and use our ontological knowledge database.
Figure 8 corresponds to the ontological model we designed. It represents a general ontology that represents several fields of knowledge, such as education, health and rehabilitation as examples. In connection with these domains, our ontological model also models the set of conversations that may occur between human and/or robotic agents. the detailed representation of the linguistic components of the conversations is also given by this model. the model represents a conversation as a set of textual or oral sequences. The ontology expresses the relationships between all the entities and their main properties.
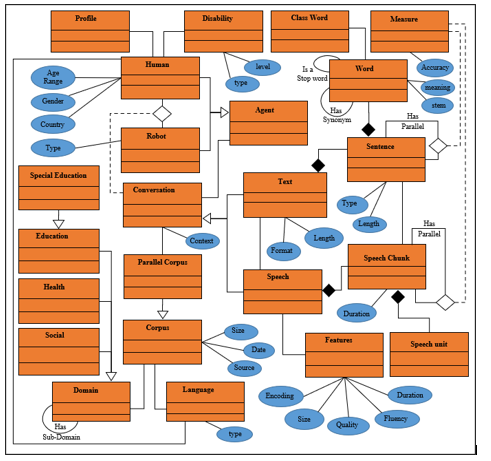 Figure 8: General ontology model for verbal communication between robot and human agents
Figure 8: General ontology model for verbal communication between robot and human agents
4.2. Ontology use for tagging sequences and reducing dataset
The ontology represented at figure 8 is used as a knowledge management system for managing information related to the human-robot verbal interactions and for help in capturing important multilingual interactions’ features for a specific domain or sub-domain [9]. Indeed, building on a hierarchy of domains and sub domains of interactions and their links to a set of linguistic and semantic concepts, our ontology knowledge base allows extraction of relevant, reduced and contextual datasets that facilitate learning significantly. It also allows a relevant labeling of these datasets producing semantic learning attributes. The figure 9 shows the principle followed to favor the reduction of training datasets taking into account the hierarchy of domains.
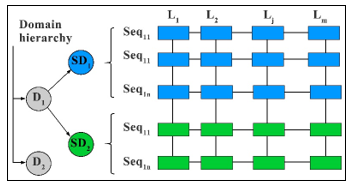 Figure 9: Dataset reduction and sequence tagging based on ontology
Figure 9: Dataset reduction and sequence tagging based on ontology
The exploitation of the domain hierarchy provided by our ontology allows to generate reduced and relevant dataset (table 1) according to the considered domain (education, therapy, …)
Furthermore, an ontology-based feature optimization method is used to reduce significantly dimensionality of feature space [10]. Thus, we are able to extract dimension-reduced datasets of multilingual parallel texts for the training and validating the LSTM-based learning model. This method is conducted in two steps:
- As a first one, concepts of general ontology are generated by a transformation of the terms of vector space model, then the frequency weights of these concepts are calculated by the frequency weights of the terms.
- and according to the structure of the general ontology, similarity weights are associated then with the concept features.
5. Experiments and Results
5.1. The used dataset
The results published in this paper are obtained on a parallel dataset constructed for Arabic, French and English (Table 2). The choice of these languages reflects our objective of deploying the results in the Moroccan context where these three languages are dominant. The table groups together the main data characterizing the distribution of sentences in the dataset used.
Figure 10 provides a graphical representation of these results. This graph shows a very strong similarity of these results for the three languages considered.
5.2. Model training
The figure 11 shows the learning result of our LSTM neural network model. It shows in particular the list of layers created and the order in which they are connected with an LSTM layer and at the end the Dense layer which comes from the LSTM layer and which is responsible for producing the prediction of the outputs. The reshape functions have been used for successive dataset transformation from 2D to 3D format.
Table1: Parallel text dataset reduction based on domain hierarchies
| Dom | SubD | N | En | Fr | Ar |
| D1 | SubD1 | 1 | Help | Aidez-moi | النجدة |
| 3 | Jump | Saute | اقفز | ||
| 4 | Run | Cours | اركض | ||
| 5 | Stop | Arrête | قف | ||
| .. | … | … | … | ||
| SubD2 | 1 | The verbal interaction | L’interaction verbale | التفاعل اللفظي | |
| 2 | Computer components | Composants de l’ordinateur | مكونات الكمبيوتر | ||
| … | … | … |
Table2: Multilingual Training dataset – Length sentences distribution
| English | Arabic | French | |||
| Count | 120.0000 | Count | 120.0000 | Count | 120.0000 |
| Mean | 123.2437 | Mean | 123.2437 | Mean | 123.2437 |
| Std | 143.1298 | Std | 152.1779 | Std | 152.1779 |
| Min | 1.0000 | Min | 7.0000 | Min | 2.0000 |
| 25% | 31.5000 | 25% | 31.0000 | 25% | 31.0000 |
| 50% | 45.0000 | 50% | 44.0000 | 50% | 46.0000 |
| 75% | 164.5000 | 75% | 172.0000 | 75% | 167.0000 |
| Max | 518.0000 | Max | 523.0000 | Max | 526.0000 |
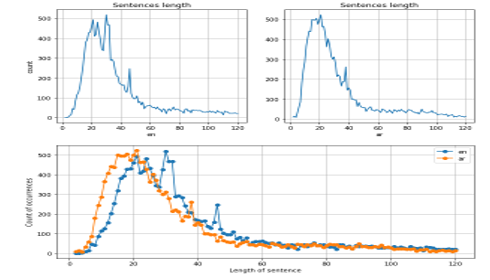 Figure 10: Distribution of the number sentence occurrences by length.
Figure 10: Distribution of the number sentence occurrences by length.
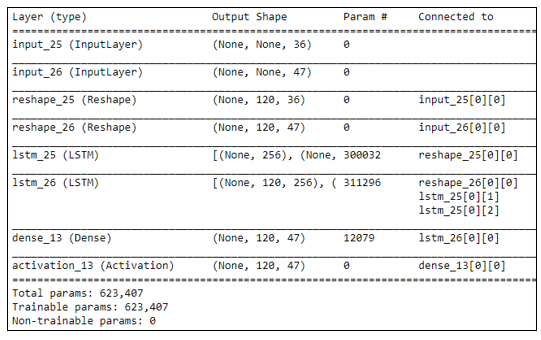 Figure 11: LSTM Model training life-cycle – model summary
Figure 11: LSTM Model training life-cycle – model summary
6. Conclusion and future works
In this paper, we presented several models and algorithms for a new approach of the human robot multilingual verbal interaction. The strength of our method lies in the combination of the strength of ontological models in terms of semantic representation and their possibilities of reasoning and inference to the capacity of machine learning models based on the LSTM model. We perform the implementation of these models using the machine learning package named Keras and NLTK python framework. These implementations have been tested in a multi-agent environment made up of several robot and human agents which interact verbally according to a number of conversations in the three languages.
The development of new upgrades for our system will be the focus of our future research, we are also aiming to take action integrating human-robot interactions in the fields of therapy and special education with the purpose of accumulating data in these fields as well as emotional data, that would allow our robots to mimic human emotion expressed in facial expressions, choice of words and voice intonation as well as detect the emotional state of patients and act accordingly. In addition, we will consider implementing the proposed models in real situations of interaction between NAO robots and children, especially in the case of the two following areas: Therapeutic rehabilitation of children with specific needs and the educational system for this category of children.
Acknowledgment
This research has been partially supported by the project “CybSPEED: Cyber-Physical Systems for Pedagogical Rehabilitation in Special Education” H2020-MSCA-RISE-2017. This project has received funding from the European Union’s Horizon 2020 research and innovation program under the Marie Skłodowska-Curie grant agreement No 777720.
- N. Mavridis, “A review of verbal and non-verbal human–robot interactive communication” Robotics and Autonomous Systems, Volume 63(1), 22-35, 2015. https://doi.org/10.1016/j.robot.2014.09.031
- I. Kafiev, P. Romanov and I. Romanova, “Intelligent Mobile Robot Control in Linguistic Evaluation of Solution Options” in 2019 International Multi-Conference on Industrial Engineering and Modern Technologies (FarEastCon), Vladivostok, Russia, 2019. https://doi.org/10.1109/FarEastCon.2019.8934814
- R.R. Galin, R.V. Meshcheryakov, “Human-Robot Interaction Efficiency and Human-Robot Collaboration” Kravets A. (eds) Robotics: Industry 4.0 Issues & New Intelligent Control Paradigms. Studies in Systems, Decision and Control, 272, Springer, Cham, 55-63, 2020. https://doi.org/10.1007/978-3-030-37841-7_5
- A. Angleraud et al., “Human-Robot Interactive Learning Architecture using Ontologies and Symbol Manipulation” In Proceedings of the 27th IEEE International Symposium on Robot and Human Interactive Communication, RO-MAN, Nanjing, 2018. https://doi.org/10.1109/ROMAN.2018.8525580
- K. Gaur, G.S.Virdi, “Smart Manufacturing with Robotic automation and Industry 4.0-A Review” in International Journal of Innovative Research in Science, Engineering and Technology, 7(3), 2481-2486, March 2018. DOI:10.15680/IJIRSET.2018.0703082
- A. Perzylo et al., “SMErobotics: Smart Robots for Flexible Manufacturing” in IEEE Robotics & Automation Magazine, 26(1), 78-90, March 2019. https://doi.org/10.1109/MRA.2018.2879747
- L. Howard, G. Paulo, F. Sandro, J. I. Olszewska, “Ontology for autonomous robotics” in 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, 189-194, 2017. https://doi.org/10.1109/ROMAN.2017.8172300
- S. Kobayashi, S. Tamagawa, T. Morita and T. Yamaguchi, “Intelligent Humanoid Robot with Japanese Wikipedia Ontology and Robot Action Ontology” in 2011 6th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Lausanne, 417-424, 2011. https://doi.org/10.1145/1957656.1957811
- A. Zeyer, P. Bahar, K. Irie, R. Schlüter and H. Ney, “A Comparison of Transformer and LSTM Encoder Decoder Models for ASR” in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), SG, Singapore, 8-15, 2019. https://doi.org/10.1109/ASRU46091.2019.9004025
- M.M. Ali et al., “Ontology-based approach to extract product’s design features from online customers’ reviews” Computers in Industry, 116, 103175,2020. https://doi.org/10.1016/j.compind.2019.103175
- D. Cruz-Sandoval et al., “Towards a Conversational Corpus for Human-Robot Conversations” in HRI ’17 Companion March 06-09, Vienna, Austria, ACM, 99-100, 2017. http://dx.doi.org/10.1145/3029798.3038344
- K. Sugiura and K. Zettsu, “Rospeex: A cloud robotics platform for human-robot spoken dialogues” 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, 2015, 6155-6160, 2015. https://doi.org/10.1109/IROS.2015.7354254
- T. Kawahara “Spoken Dialogue System for a Human-like Conversational Robot ERICA” in D’Haro L., Banchs R., Li H. (eds) 9th International Workshop on Spoken Dialogue System Technology. Lecture Notes in Electrical Engineering, 579. Springer, Singapore, 65-75, 2019. https://doi.org/10.1007/978-981-13-9443-0_6
- Z. Huang et al., “TRANS-BLSTM: Transformer with Bidirectional LSTM for Language Understanding” in arXiv:2003.07000 [cs.CL], 2019. https://arxiv.org/abs/2003.07000v1
- H. Li, A. Y. C. Wang, Y. Liu, D. Tang, Z. Lei and W. Li, “An Augmented Transformer Architecture for Natural Language Generation Tasks” in 2019 International Conference on Data Mining Workshops (ICDMW), Beijing, China, 1-7, 2019. https://doi.org/10.1109/ICDMW48858.2019.9024754
- W. Yu, M. Yi, X. Huang, X. Yi and Q. Yuan, “Make It Directly: Event Extraction Based on Tree-LSTM and Bi-GRU” in IEEE Access, 8, 14344-14354, 2020. https://doi.org/10.1109/ACCESS.2020.2965964
- M.S.H. Ameur, Farid Meziane, Ahmed Guessoum, “ANETAC: Arabic Named Entity Transliteration and Classification Dataset” in arXiv:1907.03110v1 [cs.CL] 2019, https://arxiv.org/abs/1907.03110v1
- Y. Tanimoto et al., “Feature extraction and Classification of Learners using Multi-Context Recurrent Neural Networks” in 2019 IEEE 11th International Workshop on Computational Intelligence and Applications (IWCIA), Hiroshima, Japan, 77-82, 2019. https://doi.org/10.1109/IWCIA47330.2019.8955064
- M. Swain, A. Routray, P. Kabisatpathy, “Databases, features and classifiers for speech emotion recognition: a review,” in. International Journal of Speech Technology, 21, 93–120, 2018. https://doi.org/10.1007/s10772-018-9491-z
- M.A.A. Albadr, S. Tiun, F.T. “Spoken language identification based on the enhanced self-adjusting extreme learning machine approach” PLOS ONE, 13(4), 2018. https://doi.org/10.1371/journal.pone.0194770
- M. H. Nehrir, C. Wang, Deep Learning with Python, Manning Publications Co, 2018.
- H.L. Yang HL et al., “A Personalization Recommendation Framework of IT Certification e-Learning System” in: Knowledge-Based Intelligent Information and Engineering Systems, 4693, 50-57, 2007. https://doi.org/10.1007/978-3-540-74827-4_7
- J.J. Jung, H.G. Kim, GS. Jo, “Alignment-Based Preprocessing of Personal Ontologies on Semantic Social Network” in Knowledge-Based Intelligent Information and Engineering Systems, 4693, 255-262, 2007. https://doi.org/10.1007/978-3-540-74827-4_33
- S.U. Ya-ru et al., “Agricultural Ontology Based Feature Optimization for Agricultural Text Clustering” Journal of Integrative Agriculture, 11(5), 752-759, 2012. https://doi.org/10.1016/S2095-3119(12)60064-1
- K. Munir, M. Sheraz Anjum, “The use of ontologies for effective knowledge modelling and information retrieval” Applied Computing and Informatics, 14(2), 116-126, 2018. https://doi.org/10.1016/j.aci.2017.07.003
- H. I. Krebs and N. Hogan, “Therapeutic Robotics: A Technology Push” in Proceedings of the IEEE, 94(9), 1727-1738, 2006. https://doi.org/10.1109/JPROC.2006.880721