
Optical Braille Recognition Software Prototype for the Sinhala Language
Volume 4, Issue 4, Page No 221-229, 2019
Author’s Name: Shanmuganathan Vasanthapriyana), Malith De Silva
View Affiliations
Department of Computing & Information Systems, Sabaragamuwa University of Sri Lanka, Belihuloya, 70140, Sri Lanka
a)Author to whom correspondence should be addressed. E-mail: priyan@appsc.sab.ac.lk
Adv. Sci. Technol. Eng. Syst. J. 4(4), 221-229 (2019); ![]() DOI: 10.25046/aj040427
DOI: 10.25046/aj040427
Keywords: Braille, Visually impaired, Sinhala braille, Optical braille recognition

Export Citations
Braille system is purposely made for visually impaired people, to support their literal communication in order to share their knowledge. Louis Braille introduced the braille system consists of series dots which are embossed to read by touching. Early days Braille papers are made manually, but at current days braille documents are made using machines. Due to lack of perceiving on braille symbols and characters, it was highly needed fact to develop Braille system to different languages. In the Sri Lankan context, we found that the mostly inconvenience are happening inside of Sri Lankan education system. Such as in Special Education centers, Colleges, and universities. Written Braille scripts are evolution by a limited number of people who are specialized in the Sinhala braille system. Also, the process of marking braille documents are not effective and efficient. The focus of this research is to address the issue of literal communication gaps between society and the blind people in Sri Lanka. Average quality single-sided composed Braille dot characters are identified with maximum accuracy by using several novel methodologies. Obtained results denote the proposed methodologies are with the highest accuracy and system performance are more efficient as promised. The research presents executable software prototype, includes proposed methods which align with optical braille recognition in order to transpose the recognize braille characters. Introduce of new binaries cell transcription method of Braille character from a Braille document and decoding them into Sinhala characters. The proposed cost-effective system can display decoded braille characters by normalizing to Sinhala text which is in a human-understandable form.
Received: 31 May 2019, Accepted: 24 July 2019, Published Online: 30 July 2019
1. Introduction
1.1. Background
Society consists of different people who have various capabilities. Among them, there are some people who are less capable of doing some daily activities due to various reasons. Visual illness is one of the causes. Blindness is a visual illness, occur due to various physical or neurological factors. It can be occurred at birth, due to an accident or due to other disabilities or diseases. Most of the time these conditions make a serious effect on their lives and change the whole lifestyle. According to WHO (World Health Organization), around 314 million people worldwide are living with serious vision impairments. Among them, 37 million people are suffering from blind and 124 million people are having low vision. Moreover, 90% of those blind people are living in low economic countries.
When we consider Sri Lanka, we are having a population of 21 million. Among the population, around 150,000 people are having eye blindness and around four hundred thousand (400,000) people are having a low vision. According to the report of “National Survey of Blindness, Visual Impairment, Ocular Morbidity and Disability in Sri Lanka” [1], the prevalence of blindness among those aged 40+ years is 1.7% and 15.4% for moderate visual impairment.
As we all know, we all are gifted with inborn talents. It’s the same for visually impaired or low sighted people. Most of the time they are searching for their capabilities. In addition rest of the people are expecting them to play an integral role in the society by using their inherited talents [2]. But in most of the cases, the blindness inhibits those talents and search other’s help. Blind people need to put an extra effort than the rest in order to live normal life [3]. As they all are part of humans, we have a responsibility to make their lives easier. We have to facilitate them to socialize with the world. The key for it is communication. In addition, we have to help them to reach universal knowledge. We should share their wiseness within the world and help them to come after in their lives.
To keep flow their lives with an ordinal pattern of the society, they need to have a clear knowledge of with other ordinal lifestyles. When they come to get to know these facts, they face the major problem in communication, knowledge sharing, and knowledge gathering. Instead of achieving everyday needs, there ought to be a few techniques to make emerged their abilities and keep up them on with their gifts by giving them information and let them impart their insight into society.
It’s critical to keep data in the written format since it assumes obviously job with regards to knowledge storing and sharing. For that composed learning from easygoing note to training, recorded data to encoded figure content we need images to trade that learning and data. As ordinary individuals, we have our very own written mechanism as indicated by our languages, just as outwardly visually impaired individuals likewise need some sort of images and method for the game plan of images so as to express their emotions, contemplations, information and so forth [4]. To come up with these challenges the world has come up with several mechanisms like braille system to make it happen [5].
This issue is especially clear in the schooling framework and University frameworks, where these days’ blind students are educated in standard classes. A significant number of these blind students perform the evaluation, tests, and schoolwork composing utilizing the Braille medium. Notwithstanding, most educators of these understudies are not Braille proficient [6]. One strategy by and by used to beat this trouble is that the blind students work is first sent to trained Braille transcribes, where the Braille is translated to literary text and afterward sent back to the educator before it is marked. This makes pointless postponements and cost for the blind students, educator, and government. Issues additionally exist in the working environment where any data composed by a Braille client that will be deciphered by other Braille uneducated people, should be first interpreted by the Braille client themselves [7].
Also, blind people feel helpless when it comes to situations like filling application forms. Even we don’t realize, application forms play a major role in human’s life from birth to death. Instances such as have a birth certificate, Death certificate, enroll to a school, to enter an university, to get an occupation, to go abroad, to have visa likewise most of the important events are linked with application forms and filling an application means we are providing our personal and confidential details to another party in order to get an opportunity or a service [8].
Even they know Sinhala, English, Tamil or other languages, they don’t know how to read or write in normal characters. Also, normal people don’t how to read or write in Braille characters. So there is a huge gap between normal and blind people and society make feel those people as really disable and less confident.
When it’s come to knowledge gathering and knowledge sharing, literally communication is a major medium in knowledge dissemination. In order to do communication, visually impaired people have many systems to accomplish this intention. The Braille system is the reliable and most famous system for this purpose. Braille system is a communication system which is literal. It enables blind and partially sighted people to read and write through using touch stimuli. They use this braille system for calculations, menus, signs, elevator, and books [3].
Louis Braille, a French teacher invented Braille in 1825. He formulated this concept by using the military secret codes. These secret military codes are known to be night writing. This technique is used by military soldiers at dark times to communicate with each other. These secret codes have twelve dot cell six dot height and two dots wide [9]. The only problem is Louis Braille was faced on when making the Braille system that visually impaired people cannot feel all the dots at one touch. Also, the finger doesn’t have that much sensitivity for recognizing dots at on time. He made it to practical by making this cell 2 dots wide and 3 dots in height. In order to make it use as character set, made up of different combinations of raised dots (tiny palpable bumps) as above mentioned. In order to represent different characters or sequences of characters, the 3-by-2 (3 rows and 2 columns) arrangement was used [10, 11].
Sinhala is known as the official native language of Sinhalese. According to the Sri Lankan context, there have been new to the braille system by comparing to other languages. The Sinhala language is often considered as two alphabets or an alphabet within an alphabet. It is because of the presence of two sets of letters. The core set, known as the “Suddha Sinhala” (pure Sinhalese) or “Eḷu Hoḍiya” (Eḷu alphabet) can represent all native phonemes [12]. In order to deliver Sanskrit and Pali words, the Misra Sinhala (mixed Sinhala), an extended set was introduced by ancient scholars. Current Sinhala alphabet uses 60 letters in the alphabet. There are 18 vowels and 42 constants contain in today’s standard Sinhala alphabet. However, there are 57 characters are used in present [12].
1.2. Sinhala language braille writing style
Sinhala braille and English braille are two different alphabets. They can’t be combined. We can write only single alphabets letters only at once. Numbers are recognized from a pre identification character. The numbers are identified by the braille character “⠼”. If “⠼” appears before any of the braille character the following character series until space appears is considered as numeric characters
Sinhala braille system has a different way of writing comparing to the normal Sinhala writing system. As previously mentioned with the combination of 2 by 3 arrangement of the braille dots we have 64 of different combinations use when braille writing. Braille diacritics are use made up with combining constant letters along with the vowels.
In Sri Lanka, most of the blind people are not going through any kind of education mechanism. There are fewer education centers which having knowledge of Braille system in Sri Lanka. People who have knowledge of the braille system only can read the braille documents and understand what visually impaired people have written, what they try to express. Most of the normal people don’t have any knowledge on how to read braille documents and as a society, we fail to understand what they express in the literal way of their feelings and knowledge. There are some people write their own braille books and exposed to the world. In Sri Lanka, most of the visually impaired people stay at home, and the parents don’t have knowledge of how to read or write Braille. Even if visually impaired people have to write braille, people who are at home cannot understand the braille documents. There is a clear gap between literal communication between sighted people and visually impaired people when it’s come to share their knowledge. This identified gap is addressed through this research using the software prototype.
There is a research conducted by Perera et. al, [13] that identify Sinhala Braille characters in single-sided Braille document and translates to the Sinhala language. This system was also capable of identifying Grade1 English Braille characters, numbers, capital letters and some words in Grade 2 English Braille system.
The main objective is to make a platform to understand braille fonts and convert it to Sinhala fonts in order to formalize communication between visually impaired people and the rest of other normal people. If there is a system which can translate written braille to Sinhala, It will be an excellent communication tool for sighted people (who do not know Braille) with blind writing. And it will reduce the time and money which needed to translate such documents; also, it will secure blind people’s privacy in situations like filling application forms. In order to overcome above-mentioned problems research have to follow various researches and have found there are fewer studies have done come over to address these problems. By using latest Sinhala braille alphabet [14], documents are converted with high accurate and efficiency.
2. Methodology
The overall methodological framework is shown in the following figure 1.
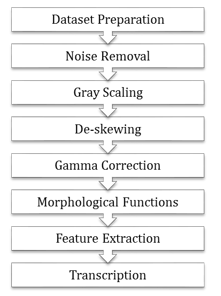 Figure 1: Methodological framework
Figure 1: Methodological framework
- Dataset preparation
As the first step in the research, the braille documents were collected. Both handwritten documents and typed documents were collected. The braille slate was used to write the handwritten document and braille typewriter was used for the typed documents. The size of the handwritten document was 9×12 inches and type documents were 8.5×11.8 inches and 9.5×12.5 inches.
After Braille documents have been collected, scanning was performed. In Optical Braille Recognition (OBR) scanning braille documents enable us to perform digitization which produces a digital image of the scanned Braille document. A flatbed scanner has been used for the digitization process. This is because it has been found as a cheap alternative to scan Braille images [8]. Figure 2 and Figure 3 shows the difference in light source distribution when grayscale.
Horizontal resolution and vertical resolution of 300 dpi and of 200dpi have been used for the scanning process. Most of the researches have been conducted in this area used 100 to 200 dpi resolution when scanning their documents so it is recommended to get quality images and the images are stored in JPEG format. Using this configuration Braille documents that are collected from different sources are scanned and prepared for subsequent processes.
 Figure 2: Braille Accusation Using Camera and After Grayscale
Figure 2: Braille Accusation Using Camera and After Grayscale
 Figure 3: Braille Accusation Using Scanner and After Grayscale
Figure 3: Braille Accusation Using Scanner and After Grayscale
Braille document property description
- Braille sheets: 12
- Resolution: 200 dpi, 300 dpi
- Digital format: Colour
- Image sizes: 9 X 12 inches, 8.5×11.8 inches, 9.5×12.5 inches
- Braille type: Single-sided
- Image format: JPEG
2.2. Pre-processing
Noise removal
Before starts to do any compilation on the scanned digital image, it’s recommended to do pre-process part on the image. Before that, it’s necessary to compare some technical aspects before coming to a conclusion which needs to select. There are several techniques on noise removal such as mean filtering, Median filtering, and Gaussian blur are some of it. In here research got selected the Gaussian blur for noise removal and later here it discussed why select Gaussian algorithm [15].
If the window size is small the effect of filters will reduce because it is not capable remove noise much effectively. If the window size is got increased it will remove the noise, but as well it will blur the braille bots and also the edges of the documents. Which lead to reduce the detail of the image where do not contain noise also.
There can be several ways of getting the braille document noisy. When considering the handwritten documents, according to the way of writer use the paper may lead to noise. Sometimes the environment may lead to noises. Another way of getting noise is paper may itself having some patches or print issues. However here below Figure 4 give a clear idea on how handwritten braille document have exposed for noise. Type documents are can be exposed to noise when they read by the visually impaired people because of the dust and other unnecessary things having on the fingers at the time of reading braille image [16]. Finally, in the end, there may be noise when getting through the scanner.
 Figure 4: Noise on Handwritten Image after Pre-Processing
Figure 4: Noise on Handwritten Image after Pre-Processing
But in here its need to focus on both side at this stage. When using powerful noise removal algorithm to removing the noise it may affect to respective needed details on the documents which are not affected by the noise at high scale. With the above facts no need to use powerful noise removing algorithms because they may get the effect to somewhat on context [4].
Mean filter
Mean filtering is done using read pixel by pixel of the image and assign the mean value of values for its pre-defined kernel’s structure center pixel. When the kernel is large, the center pixel may have a high effect through other pixel values. Even a pixel which does not contain noise also gets affected. Also, it should not affect the braille cell segmentation and features extraction. But this will lead to unnecessary complexity on future steps.
Median filter
This mechanism is a little bit ahead than the mean filter because the median filter is replacing a middle pixel with the median value of the kernel’s center pixel. Which leads to damage the edges of the characters and edges of the fields [17].
Gaussian blur
Gaussian blur was used to remove the noise. Instead of utilizing other low pass filtering algorithms, Gaussian blur channel does not lessen braille dot details. However, it makes decrease noise in an incredible way. Figure 5 denotes how the Gaussian blur work on noise removing. As indicated by the Gaussian blur work it weighs more on closest pixels of the utilized kernel canter. Figure 6 shows how weight is distributed around the center pixel. Equation 1 shows Gaussian blur for one dimension.
 Figure 5: Gaussian Blur Apply On Noised Document
Figure 5: Gaussian Blur Apply On Noised Document
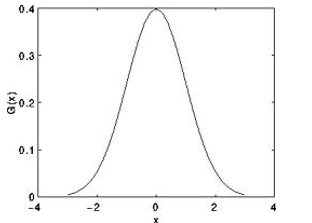 Figure 6: Pixel Weighting According To Kernel Center
Figure 6: Pixel Weighting According To Kernel Center
![]() A filter using EmguCV was applied to the input in order to perform the smoothing function [18]. Equation 2 shows how EmguCV has done for the above mathematical operation (equation 1). Equation output pixel’s value g (i, j) is determined as a weighted sum of input pixel values.
A filter using EmguCV was applied to the input in order to perform the smoothing function [18]. Equation 2 shows how EmguCV has done for the above mathematical operation (equation 1). Equation output pixel’s value g (i, j) is determined as a weighted sum of input pixel values.
![]() The coefficients of the filter are the kernel which is represented by h (k, l). It helps to visualize a channel as a window of coefficients sliding over the image. Weighing of the pixel was done through f (i+k, j+l). Even though it is not the fasted filter it is good to filter for working with images. Gaussian filtering was done by convolving each point in the input array with a Gaussian kernel and then summing them all to produce the output array [18]. Table 1 describes the above mention details as a summary.
The coefficients of the filter are the kernel which is represented by h (k, l). It helps to visualize a channel as a window of coefficients sliding over the image. Weighing of the pixel was done through f (i+k, j+l). Even though it is not the fasted filter it is good to filter for working with images. Gaussian filtering was done by convolving each point in the input array with a Gaussian kernel and then summing them all to produce the output array [18]. Table 1 describes the above mention details as a summary.
Table 1. Reasons Summary of Gray Scale, Mean Filter, and Gaussian Blur
| Median Filter | Mean Filter | Gaussian Blur |
| Low Computational Cost | High Computational Cost | High Computational Cost |
| Preserve Image Details | Very Low Capabilities to Preserve Image Details | High Capabilities to Preserve Image Details |
| Low Memory Consumption | High Memory Consumption | Low Memory Consumption |
| Simple Implementation | Simple Implementation | Simple Implementation |
| Analytical Process Becomes Simpler | Analytical Process Becomes Relatively Complex | Analytical Process Becomes Relatively simple |
2.3. Grayscale
The expectation of using gray scaling technology is not only for reducing noise but also several other results are expected. Since the resolution and quality of the image will higher according to the dpi of the input image. The time which takes for the process relatively large when quality is high, which is negatively affected for systems performance. But when do gray scaling it is an extremely small amount of time takes for the entire process.
On the other hand to conduct analyzing processes such as edge detection, segmentation, and feature extraction and classification techniques effectively it is necessary to reduce the intensity of the image since inputs to the system are color images. Since gray scaling contains only 0-255 values on pixels it is useful to use gray scaling such that it is easy to conduct analytical processes [19]. As the second step, convert the color image into a grayscale image. Figure 7 shows the result when the input image goes through gray scaling.
 Figure 7: Gray Scale of Input Image
Figure 7: Gray Scale of Input Image
2.4. De-skewing
Rotation is used to de-skew braille documents in place of horizontal and vertical projection profiles.. In some cases the document may not have skewing errors but in general when braille documents are composed there is a possibility for skewing errors to occur. Instead of squandering increasingly computational capacity to de-skew documents, the work utilizes moderately fixed positions to de-skew the documents using rotation angle. Figure 8 demonstrates De-skewed image Utilizing Rotation.
 Figure 8: De-Skewed Image Using Rotation
Figure 8: De-Skewed Image Using Rotation
2.5. Gamma correction
Gamma correction was done on the gray image to enhance subtleties of the braille spots. Gamma correction can be utilized in non-direct connections and in encoding or interpreting the luminance in images. Equation 3 and 4 demonstrate the calculation.
 As this connection is nonlinear, the impact won’t be equal for each pixel and will rely upon their original value. Whenever γ<1, the first original dark regions will be brighter and the histogram will be moved to one side and vice versa with γ>1. Here work utilizes the gamma= 4.0 and Figure 9 depicts the eventual outcomes on a grayscale image.
As this connection is nonlinear, the impact won’t be equal for each pixel and will rely upon their original value. Whenever γ<1, the first original dark regions will be brighter and the histogram will be moved to one side and vice versa with γ>1. Here work utilizes the gamma= 4.0 and Figure 9 depicts the eventual outcomes on a grayscale image.
 Figure 9: Gamma Correct on Gray Scale Image
Figure 9: Gamma Correct on Gray Scale Image
2.6. Morphological erosion
Morphologic capacity disintegration is utilized to sharpen the edges of the braille spots. Unlike other methods, their morphologic capacities disregard the flaws which happen to the surface and state of the picture. Furthermore, administrators such as segregation and joining of individual pixels and different pixels help locate the decorated braille dot. Disintegration impact as per the organizing component was utilized. In contrast to paired disintegration, grayscale disintegration improves the dot subtleties [9]. Indicating a picture by f(x) and the grayscale organizing component by b(x), where B is the space that b(x) is characterized, the grayscale disintegration of f by b is given as in the equation (5). Image after Morphological Erosion is shown in Figure 10.
 Figure 10: Image after Morphological Erosion
Figure 10: Image after Morphological Erosion
2.7. Feature extraction
Feature extraction is an illustrative system of the Braille image. The principle function of this procedure is to extract the Braille dots from the binaries image. The image capturing, pre-handling and division stages cause the image to be appropriate for various element extraction calculations. Some component extraction calculations are only concerned with the forms of the image while a few calculations ascertain each pixel of the image. Conversely, the underlying image might be noise influenced or obscured by different reasons..[7].
Simultaneously, the nature and the yield of the image pre- processing and division steps are determined by the picture feature and the extraction strategy. Feature extraction phase can be considered as the most important part of braille character translation because the accuracy of the translated character heavily depends on the extracted features of the cells.
Thresholding
Before the segment, the braille cell into six equal compartments, need perfect detection of braille dots. For this work have experimented on various thresholding techniques. First attempt was using straightforward thresholding strategies like Binary, To Zero thresholding and Binary inverse thresholding etc. The most intricate task was to recognize limit esteem in light of the fact that the reports have various hues and when checking, pixel luminance may change. To overcome the issue, in this research versatile thresholding Otsu strategy was utilized. Since the attempt was to make binomial pictures along the way of preparing part and it is the greatest contribution to Otsu thresholding, Otsu thresholding calculation located the bimodal qualities and attempted to discover the boundary that limits the weighted intra- class change. Bimodal picture is a picture whose histogram has two pinnacles. From the calculation, it takes the center of those histogram crests and computes the intra-class fluctuation.. Figure 11 shows the result of Otsu thresholding.
 Figure 11: Image after Otsu thresholding
Figure 11: Image after Otsu thresholding
It actually finds a value of t which lies in between two peaks such that variances to both classes are minimum. After making thresholding, cell segmentation done using the standard braille dimensions.
The vertical as well as horizontal (however not corner to corner) separation between two focuses of neighboring dots in a specific cell is 2.5 mm. The separation between focus to focal point of relating spots in vertically contiguous cells is 5.0 mm, in the interim it is 3.75 mm for the horizontal neighboring cells.
2.8. Transcription
As presented in Figure 12 braille cells are sectioned and checked for the normal white pixels over 60%. On the off chance that the normal of white pixels is over 60%, it’s perceived as substantial braille dot and marked as 1. If it’s not, it is considered as there is no braille spot, which means the rate ascribed is 0.
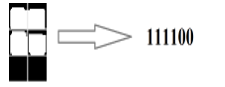 Figure 12: Cell transcription to binary values
Figure 12: Cell transcription to binary values
Here below algorithm written for the binaries cell.
Inputs: erodeimg1, erodeimg2, projection_x, projection_y; img, resolutiondpi_x
For counter = projection_x to projection and counter less than height of erodeimg1 then
For counter = projection_x to projection x + resolutiondpi_x and less than width of erodeimg1 then
For counter = 0 and less than height of img1 then
For counter =0 and less than width of img1 then
do calculation:
Check row 1, column 1;
Check row 1, column 2;
Check row 2, column 2;
Check row 3, column 1;
Check row 3, column 2;
End for
End for
End for
End for
When binaries string array is extracted from the above way, the mapping to Sinhala Unicode is done using SQL Server. All the particular related string array contain it’s Unicode in the database. The database connects to the system via Entity Framework in C#.
As a summary, for an example, Sinhala quote “අක්කා ගෙදර ගියාය” is mapped as “අ්කකආ ගඑදර ගඉයආය ”. And for the above Sinhala phase braille mapping is as follows;
3. Result and Discussion
The Final result depends on many processes. Mainly segmentation, feature extraction, and classification. These 3 processes have to perform accurately as possible so the final outcome will be more accurate.
The transformation from Braille documents into Sinhala content is a trending research area where much research has not been taken so far. The proposed framework has utilized some new strategies to perceive Braille cells utilizing a standard scanner. The framework has been tried with a wide range of sizes and diverse shading single-sided checked Braille documents written in Sinhala, and examined with various scanners.
The framework exploits the ordinary separating between Braille dabs inside a cell and the standard dividing between cells. The Braille documents can be embossed on a scope of media and with various particulars, for example, page size, dot size, bury Braille dot separation and, entomb Braille cell separation. Other than to accurately perceive Braille documents with numerous artifacts, an algorithm that effectively fragments the Braille pictures into cells is critical in Braille recognition.
Because of the idea of Braille documents, it is relied upon for most documents to have a few deformities, for example, slight varieties in background shading and few dull spots. Moreover, picture quality relies upon the degree of examining artifacts, for example, the impact of non-uniform light. These issues, for the most part, cause the softness of the feature some portion of Braille spots to be considerably less particular from the page background and could be misidentified as the feature or shadow portions of dots.
Additionally, the presence of light and dark areas that are not parts of Braille spots may prompt wrongly recognized spots on the off chance that they happen to satisfy the conditions set for true dots. Anyway, it is difficult to recognize noise regions and legitimate ones. Another factor which influences the exhibition of braille character recognition is the situation of the dots of a character in the picture. At present, if a legitimate spot lies outside the normal limits of the Braille character it won’t be accepted as a component of that character. Thus, the character won’t be accurately perceived.
The way that Braille characters don’t have distinct contrasts in shape between them does not improve recognition. On the off chance that there is at least one spot at legitimate positions, at that point, the relating character will be perceived. It is hard to pass judgment on whether there is an additional dot or whether a spot is absent. Henceforth, on a solitary character premise, it is beyond the realm of imagination to expect to survey the rightness of the recognition result. In any case, it is conceivable to recoup from certain mistakes by performing background examination.
Generally, most of the errors can be credited to the nature of the picture of the Braille document. Additionally, it ought to be called attention to that the nature of the Braille document itself is significant. Extremely old document with a portion of the projections crushed because of substance use will offer ascent to all the more mistakenly perceived characters.
As in Table 2, it shows character-wise accuracy of the proposed programming model. With these outcomes here it demonstrates all the character recognition is above on 80% of accuracy. Table 3 and 4 indicate punctuation identification and numerical identification respectively. For that, there ought to pre-sign need to distinguish and afterward convert those into numerical. With the outcomes, numerical are additionally constantly distinguished at above 88% precision. By utilizing neural systems administration or some other profound learning calculations the precision rate can be upgraded via preparing those characters for word expectation and discover characters.
Various methods were carried out to improve the performance of the system. Experiments include scanning at different resolutions and color and grey level ranges.
However, in this system, it does not require expensive or complicated hardware. It uses a flatbed scanner, which can be shared with other applications.
The implemented method has been tested with a variety of scanned Braille documents written using standard Sinhala Braille. Documents were scanned using commercially available different scanners with 200 dpi and 300 dpi resolutions. The processing was performed on a PC with an Intel core i5, 4GB RAM, under EmguCV and.Net implementation environment.
Table 2: Character Wise Identification with Accuracy Rate
| Cha-rac-ter | Symbol | # of sam-ples | # of samp-les corre-ctly identi-fied |
Perce-ntage (%) |
| අ | ⠁ (braille pattern dots-1) | 26 | 25 | 96.15385 |
| ආ | ⠜ (braille pattern dots-345) | 90 | 90 | 100 |
| ඇ | ⠷ (braille pattern dots-12356) | 22 | 20 | 90.90909 |
| ඈ | ⠻ (braille pattern dots-12456) | 10 | 10 | 100 |
| ඉ | ⠊ (braille pattern dots-24) | 101 | 96 | 95.0495 |
| ඊ | ⠔ (braille pattern dots-35) | 18 | 18 | 100 |
| උ | ⠥ (braille pattern dots-136) | 35 | 33 | 94.28571 |
| ඌ | ⠳ (braille pattern dots-1256) | 15 | 15 | 100 |
| එ | ⠑ (braille pattern dots-15) | 22 | 21 | 95.45455 |
| ඒ | ⠢ (braille pattern dots-26) | 23 | 22 | 95.65217 |
| ඵෙ | ⠌ (braille pattern dots-34) | 11 | 10 | 90.90909 |
| ඔ | ⠭ (braille pattern dots-1346) | 10 | 10 | 100 |
| ඕ | ⠕ (braille pattern dots-135) | 13 | 11 | 84.61538 |
| ඖ | ⠪ (braille pattern dots-246) | 11 | 10 | 90.90909 |
| ක | ⠅ (braille pattern dots-13) | 47 | 45 | 95.74468 |
| ඛ | ⠨ (braille pattern dots-46) | 11 | 10 | 90.90909 |
| ග | ⠛ (braille pattern dots-1245) | 30 | 30 | 100 |
| ඝ | ⠣ (braille pattern dots-126) | 10 | 10 | 100 |
| ඬ | ⠬ (braille pattern dots-346) | 11 | 9 | 81.81818 |
| ච | ⠉ (braille pattern dots-14) | 14 | 14 | 100 |
| ඡ | ⠡ (braille pattern dots-16) | 10 | 9 | 90 |
| ජ | ⠚ (braille pattern dots-245) | 18 | 16 | 88.88889 |
| ට | ⠾ (braille pattern dots-23456) | 20 | 20 | 100 |
| ඨ | ⠺ (braille pattern dots-2456) | 10 | 9 | 90 |
| ඩ | ⠫ (braille pattern dots-1246) | 13 | 13 | 100 |
| ඪ | ⠿ (braille pattern dots-123456) | 10 | 10 | 100 |
| ත | ⠞ (braille pattern dots-2345) | 55 | 53 | 96.36364 |
| ථ | ⠹ (braille pattern dots-1456) | 10 | 10 | 100 |
| ද | ⠙ (braille pattern dots-145) | 30 | 30 | 100 |
| ධ | ⠮ (braille pattern dots-2346) | 17 | 16 | 94.11765 |
| න | ⠝ (braille pattern dots-1345) | 72 | 70 | 97.22222 |
| ප | ⠏ (braille pattern dots-1234) | 28 | 28 | 100 |
| ඵ | ⠱ (braille pattern dots-156) | 11 | 10 | 90.90909 |
| බ | ⠃ (braille pattern dots-12) | 22 | 21 | 95.45455 |
| භ | ⠘ (braille pattern dots-45) | 12 | 11 | 91.66667 |
| ම | ⠍ (braille pattern dots-134) | 73 | 71 | 97.26027 |
| ය | ⠽ (braille pattern dots-13456) | 65 | 59 | 90.76923 |
| ර | ⠗ (braille pattern dots-1235) | 80 | 79 | 98.75 |
| ල | ⠇ (braille pattern dots-123) | 48 | 46 | 95.83333 |
| ළ | ⠸ (braille pattern dots-456) | 12 | 12 | 100 |
| ව | ⠧ (braille pattern dots-1236) | 70 | 70 | 100 |
| ශ | ⠯ (braille pattern dots-12346) | 11 | 7 | 63.63637 |
| ෂ | ⠩ (braille pattern dots-146) | 13 | 11 | 84.61538 |
| ස | ⠎ (braille pattern dots-234) | 80 | 77 | 96.25 |
| හ | ⠓ (braille pattern dots-125) | 30 | 30 | 100 |
| ෆ | ⠋ (braille pattern dots-124) | 11 | 9 | 81.81818 |
| ණ | ⠵ (braille pattern dots-1356) | 17 | 15 | 88.23529 |
| ඟ | ⠆⠛ (braille pattern dots-23)(braille pattern dots-1245) | 11 | 9 | 81.81818 |
| ඬ | ⠆⠫(braille pattern dots-23)(braille pattern dots-1246) | 11 | 10 | 90.90909 |
| ඳ | ⠆⠙(braille pattern dots-23)(braille pattern dots-145) | 12 | 10 | 83.33333 |
| ඹ | ⠆⠃(braille pattern dots-23)(braille pattern dots-12) | 11 | 10 | 90.90909 |
| ඥ | ⠟ (braille pattern dots-12345) | 10 | 9 | 90 |
| ක් | ⠈ (braille pattern dots-4) | 118 | 113 | 95.76271 |
| කං | ⠄ (braille pattern dots-3) | 40 | 34 | 85 |
Table 3: Punctuation Wise Identification Results and Accuracy Rate
| Punc-tuati-on | Symbol | # of sam-ples | # of samples correctly identified |
Perce-ntage (%) |
| . | ⠲ (braille pattern dots-256) | 23 | 21 | 91.30435 |
| , | ⠂ (braille pattern dots-2) | 11 | 10 | 90.90909 |
| ; | ⠆ (braille pattern dots-23) | 12 | 12 | 100 |
| : | ⠒ (braille pattern dots-25) | 10 | 10 | 100 |
| ! | ⠖ (braille pattern dots-235) | 12 | 11 | 91.66667 |
| [] | ⠶ (braille pattern dots-2356) | 20 | 18 | 90 |
| “ | ⠦ (braille pattern dots-236) | 10 | 9 | 90 |
| ” | ⠴ (braille pattern dots-356) | 10 | 9 | 90 |
| / | ⠤ (braille pattern dots-36) | 21 | 21 | 100 |
| Space | (no braille dots) | 76 | 73 | 96.05263 |
Table 4: Identified Numerals Results with Accuracy Rate
| # | Symbol | # of sam-ples | # of samples correctly identified | Perce-ntage (%) |
| 1 |
⠼ (braille pattern dots-3456) ⠁ (braille pattern dots-1) |
25 | 25 | 100 |
| 2 |
⠼ (braille pattern dots-3456) ⠃ (braille pattern dots-12) |
17 | 16 | 94.11765 |
| 3 |
⠼ (braille pattern dots-3456) ⠉ (braille pattern dots-14) |
16 | 16 | 100 |
| 4 |
⠼ (braille pattern dots-3456) ⠙ (braille pattern dots-145) |
16 | 15 | 93.75 |
| 5 |
⠼ (braille pattern dots-3456) ⠑ (braille pattern dots-15) |
17 | 15 | 88.23529 |
| 6 |
⠼ (braille pattern dots-3456) ⠖ (braille pattern dots-124) |
20 | 18 | 90 |
| 7 |
⠼ (braille pattern dots-3456) ⠛ (braille pattern dots-1245) |
21 | 21 | 100 |
| 8 |
⠼ (braille pattern dots-3456) ⠓ (braille pattern dots-125) |
22 | 22 | 100 |
| 9 |
⠼ (braille pattern dots-3456) ⠊ (braille pattern dots-24) |
21 | 21 | 100 |
| 0 |
⠼(braille pattern dots-3456) ⠴ (braille pattern dots-356) |
70 | 68 | 97.14286 |
3.1. Threats to validity
With several approaches have done related to the work there is many limitations have found. Image acquisitions using different types of equipment would have an effect on results receiving. While the acquired image is not with the minimum dpi will affect results. With the lightning disturbances without equally spread on documents make the threat to results which observed. Cropping document with the desired way of the human pattern will lead to making half braille characters and direct effect on results we obtain.
4. Conclusion and Future Works
The Braille framework is a tactile technique broadly utilized by visually impaired individuals to read and write or peruse and compose. Braille documents contain lines of characters, where each character has six spots masterminded in three lines and two segments (three rows and two columns) and each dot can either be raised or be level as indicated by the corresponding character. Braille is reasonably understandable by visually impaired individuals; notwithstanding, sighted individuals need not have the option to comprehend these codes. Braille recognition system can connect the correspondence communication gap between visually impaired and sighted individuals. A ton of exertion has been made worldwide by specialists to connect this gap. In this investigation, an endeavor has been made on the element extraction and characterization modules of Sinhala Braille acknowledgment as indicated by the Sri Lankan context.
This proposed programming model is fit for extracting Braille characters from a Braille document pursued by decoding them into Sinhala characters and after that standardization of the decoded Sinhala characters into readable Sinhala content. The transformation from Braille documents into Sinhala content is another zone where much research has not been completed.
An algorithm to distinguish dots in a picture of embossed Braille material obtained by an optical scanner was proposed. Despite the fact that the Braille dots have a similar shading as the foundation, they cast delicate shadows when checked with a standard flatbed scanner. These shadows are utilized to find the dots on the page.
In general, the methodology indicates achievability as a practical, cost-effective, quick and simple strategy to identify dots in Braille records. It doesn’t require costly or complicated equipment. It utilizes a flatbed scanner which can be shared with different applications. Robustness to adapt to low-quality scans and imperfect reports are worked in at various levels. The outcomes got were promising during trials performed on single-sided embossed records, with over 95% accuracy.
The recognition rate for character recognition has the opportunity to get better. One approach to improve it is to actualize a Sinhala spell check algorithm. Any misrecognized image can be recognized since the word and sentence that the character has a place which would never again make sense.
It is important that every one of the examples in the investigations are sensibly all well-formed. A conceivable future upgrade in this undertaking is utilizing various allegations with numerous gadgets like cell phones. This may incorporate adding a few algorithms to progressively change different edges for various pieces of the framework, to represent fluctuation, for example, the shade of the paper. On account of slanted pictures, a few components to deal with the revolution will be automated. Indeed, even there are severe principles about the size of the spots utilized just as the dispersing between them, size of the braille specks in the wake of filtering is vary from record to report as indicated by its shading. If the feature extraction algorithm automatically adopted according to its color of the document there will be a much better extraction of features for classification.
Author’s Contributions
Shanmuganathan Vasanthapriyan: Designing of experiment (75%), Laboratory and experiment (75%), Interpretation and data analysis (75%), Writing up (75%).
Malith De Silva: Designing of experiment (25%), Laboratory and experiment (25%), Interpretation and data analysis (25%), Writing up (25%).
- Ministry_of_Health. National Survey of Blindness, Visual Impairment, Ocular Morbidity and Disability in Sri Lanka. 2015; Available from: https://www.iapb.org/wp-content/uploads/National-Survey-of-Blindness-A-Report-2014-2015.pdf.
- Srinath, S. and C.R. Kumar, A novel method for recognizing Kannada Braille: Consonant-Vowels. International Journal of Emerging Technology and Advanced Engineering, 2013. 3(1): p. 596-600.
- Al-Salman, A.S., et al. An efficient braille cells recognition. in 2010 6th International Conference on Wireless Communications Networking and Mobile Computing (WiCOM). 2010. IEEE.
- Hentzschel, T. and P. Blenkhorn, An optical reading system for embossed Braille characters using a twin shadows approach. Journal of Microcomputer Applications, 1995. 18(4): p. 341-354.
- Mennens, J., et al., Optical recognition of Braille writing using standard equipment. IEEE Transactions on Rehabilitation Engineering, 1994. 2(4): p. 207-212.
- Al-Salman, A., et al., An arabic optical braille recognition system. 2007.
- Wajid, M., M.W. Abdullah, and O. Farooq. Imprinted Braille-character pattern recognition using image processing techniques. in 2011 International Conference on Image Information Processing. 2011. IEEE.
- Mousa, A., et al., Smart braille system recognizer. International Journal of Computer Science Issues (IJCSI), 2013. 10(6): p. 52.
- Zhang, H., J. Li, and J. Yin. A Research on Paper-Mediated Braille Automatic Extraction Method. in 2010 International Conference on Intelligent Computation Technology and Automation. 2010. IEEE.
- Antonacopoulos, A. and D. Bridson. A robust braille recognition system. in International Workshop on Document Analysis Systems. 2004. Springer.
- Li, J. and X. Yan. Optical braille character recognition with support-vector machine classifier. in 2010 International Conference on Computer Application and System Modeling (ICCASM 2010). 2010. IEEE.
- Educational_Publications_Department, �ංහල භාෂාව හා සා�ත්යය.
2018. 1 – 213. - Perera, T. and W. Wanniarachchi, Optical Braille Translator for Sinhala Braille System: Paper Communication Tool Between Vision Impaired and Sighted Persons. The International Journal of Multimedia & Its Applications (IJMA) Vol, 2018. 10.
- Sinhalese Braille. 2016; Available from: https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Sinhalese_Braille.html.
- Dubus, J., et al. Image Processing techniques to perform an autonomous System to translate relief Braille back into ink called LectoBraille. in IEEE 10th International Conference in Medicine and Biology Society, New Orleans. 1988.
- Falcon, N., et al. Image processing techniques for braille writing recognition. in International Conference on Computer Aided Systems Theory. 2005. Springer.
- Hu, Y. and H. Ji. Research on image median filtering algorithm and its FPGA implementation. in 2009 WRI Global Congress on Intelligent Systems. 2009. IEEE.
- Moshnyaga, V.G. and K. Hashimoto. An efficient implementation of 1-D median filter. in 2009 52nd IEEE International Midwest Symposium on Circuits and Systems. 2009. IEEE.
- Padmavathi, S., S.S. Reddy, and D. Meenakshy, Conversion of braille to text in english, hindi and tamil languages. arXiv preprint arXiv:1307.2997, 2013.