An enhanced Biometric-based Face Recognition System using Genetic and CRO Algorithms

Adv. Sci. Technol. Eng. Syst. J. 3(3), 116–124 (2018);
 DOI: 10.25046/aj030316
DOI: 10.25046/aj030316
Face recognition is one of the most well-known biometric methods. It is a technique used for identifying individual from his face. The recognition process takes the face and compares it with the one stored in the database for recognizing it. Many methods were proposed to achieve that. In this paper, a new technique is proposed by using meta-heuristic algorithm. The algorithm is used to search for the best point in the image to be selected as a pivot, generate a vector of extracted features that are not necessary for the recognition and may reduce accuracy of it and evaluate the weight value for each area in the face image areas. A dataset with 371 images was used for evaluation. The results were conducted and compared with the original face recognition technique. That results show that proposed idea could enhance recognition by increasing accuracy up to 20% over original face recognition technique.
1. Introduction
Recently, Face recognition has received a great attention in many fields from security, psychology, and image processing, to computer vision [1-5] because of its accuracy and low intrusiveness. It is one of the biometric techniques used for identification individuals by comparing face image with the ones stored in the database [6]. The process of face recognition can be divided into three stages: face detection, feature extraction and face recognition as shown in Figure 1
 Figure 1: Face recognition process [7]
Figure 1: Face recognition process [7]
Face detection detects the existence of the face in an image by locating the position of it. Then, the features are extracted which is the most important step to recognize face. The face features are extracted to a vector, which is considered as a signature to the image. The features for each face are unique and used to discriminate between two individuals. Last, face recognition involves verification and identification. Verification compares the face image to approve the request of individual, identification compares face image with the set of images stored in the database to identify it.
Many methods had been proposed before for face recognition such that Principal Component Analysis (PCA), Multi-linear Principal Component Analysis (MPCA) and Linear Discriminate Analysis (LDA) [8,9]. In [10], the authors proposed a new face recognition using genetic algorithm. The work compared with the Principal Component Analysis (PCA) and Linear Discriminate Analysis (LDA) algorithms for face recognition and analyzed the face recognition results using various databases such as ORL, UMIST and Indbase. The results clearly show that the recognition rate of Genetic algorithm is better than the PCA and LDA in case of ORL, UMIST and Indbase databases. In [11], the authors proposed a novel algorithm for recognizing human faces using Genetic Algorithms. The proposed method produces better result as compared to other techniques like PCA and LDA for one sample per person.
1.1. Face recognition system
For each image, there are more than 80 feature points on human face and one of these feature points must be elected as pivot point. The pivot point is the most important feature point, where the distance between it and all other feature points must be calculated and saved into database to be compared lately with new results of user who needs to enter to the system. Based on this calculation and features, the idea of original face recognition goes through two steps, enrollment and matching phase as shown in Figures 2 and 3.
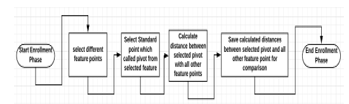 Figure 2: Face recognition enrollment phase
Figure 2: Face recognition enrollment phase
After enrollment phase, all the user’s data are stored now in the database. Next step is the matching phase. Through this phase, the distance between pivot point and all other feature points will be calculated for the user who needs to access. The output result from this calculation will be compared with the data stored in the database. If the number of matched feature distance is greater than a threshold value then the result for this user is matched, else this user is not matched.
The human face can be divided into different areas such as eyes area, nose area, mouth area, etc. Each of these areas has a specific weight value; this weight value plays an important role in matching result. The flowchart for the matching phase is shown in Figure 3.
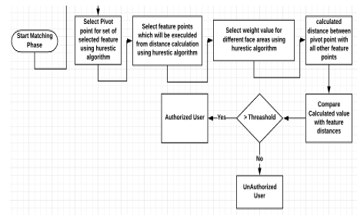 Figure 3: Face recognition matching phase
Figure 3: Face recognition matching phase
Face recognition technique show that there are different factors that can play an important role in matching accuracy. Based on these factors, we propose a new scheme for face recognition to achieve high level of accuracy that depends on using a meta heuristic algorithm to select best values for different variables; two meta heuristic algorithm used in our approach: Genetic meta heuristic algorithm (GA) and chemical reaction optimization meta heuristic algorithm (CRO). The goals of using them can be summarized as follows:
- Select the best point in the image to be a pivot. The pivot represents a point in the image where the distance between it and every point in the features can be used for enhancing recognition rate.
- Select a set of features to be excluded from the processing. Some of the extracted features in the image can make noise and decrease accuracy of detection; for that the proposed algorithm used a vector to store such features to be excluded from the recognition process.
- Update weight values for each face area to enhance its accuracy.
1.2. Applications of Face recognition system
Nowadays, many applications in many areas that need personal identification use face recognition techniques; some of these are listed below:
- Access control system: It uses face as a verification method to match with the one enrolled.
- Banking
- Internet and e-commerce
- Human computer interface HCI
- Smart cards
- Security camera system presents common in airports, companies, universities, ATM machines, among others.
- Replacement of PIN
- Others
1.3. Advantages of using Face recognition system
Using biometric techniques in general has a lot of advantages. Face recognition method is most widely used because of the following advantages:
- The existence of camera in most wireless devices
- Uniqueness
- Inexpensive technique
- The system does not require any direct communication between user and device in order to authenticate him/her.
1.4. Disadvantages of Face recognition system
There are a number of disadvantages of using face recognition techniques, which can be summarized as follows:
- Aging: The picture of the individual may be change by age and need to be updated in the database every two years or so in average.
- Using of special characters such as glasses may affect on the accuracy of the recognition.
- Emotion of the individual such as sadness, happiness, and anger will have an influence on the picture.
- Image pose: The camera pose will affect the image as well as the rotation of the face.
2. Proposed work
2.1. Dataset
The dataset used in this paper is taken from XM2VTSDB multi-modal face database project [12], which consists of 371 persons picture features with different sessions for each person. The overall number of images collected on the database is about 2360 different images for 371 persons. From each image we extracted 67 features. These collected images refer to different genders, males and females, with different ages and for different positions for each person. These images are taken over a period of four months.
2.2. Genetic algorithms
A Genetic algorithm, GA [13,14,15], is defined as the most powerful algorithm used to solve large problems where there are a large number of solutions and an optimization is needed to generate better solutions from them. The main components of the algorithm are:
- An initial population for the solution
- A fitness function to generate better solution
Each individual in the population is a numeric value with n bits that represents a solution to the problem. The individual in the GA is called chromosome, which is a sequence of 1’s and 0’s. In order to generate better solution from the population, GA runs a set of operations to optimize solution and gets better results for the problem as follows:
- Evaluate fitness function for each individual.
- Selection: The selection operator selects individuals from the population with highest fitness value as a parent.
- Crossover: This is the recombination operator, which allows individuals to exchange information and generate the offspring for the next population. The aim is to generate better offspring who is not identical to his parents but contains their traits. Three types of crossover can be used: one point, two point and uniform.
- Mutation: Is making a change in some bits value of the chromosome in order to generate new better individual.
- Update value of the fitness function for each individual.
All the above three steps are repeated to a maximum number of iterations.
2.3. Chemical Reaction Optimization (CRO) Algorithm
Chemical Reaction Optimization (CRO) is a meta-heuristic algorithm inspired by the nature of chemical reactions [16]. It starts with initial molecules, and by doing a sequence of collisions where final product becomes in the stable state. The major difference between CRO algorithm and any other evolutionary techniques is that population size in the CRO may change after each iteration of the algorithm running, while in all other techniques, the population size is fixed and unchanged during execution. The basic unit in the CRO population is called molecule, which has a potential energy that is considered fitness function of the individual. Each molecule has a set of parameters like kinetic energy, molecule structure and more, some of them are important and some are less important depending on the problem.
In order to change on the molecule, a collision is made which could be either uni-molecule (one molecule) or inter-molecule (two or more collide with each other). The aim is to transform into a stable product with minimal potential energy. The chemical reaction could be one of these types:
- On-wall ineffective collision: This occurs when the molecule collides with the wall of container and then bounces. The transformation of the molecule structure can be represented as ω → ω-
- Decomposition: This happens when the molecule hits in the wall and then decomposes into small parts. ω → ω1- + ω2
- Inter-molecular ineffective collision: y happens when multi molecule collide with each other and then bounces away.
- Synthesis: It is the opposite to the decomposition and happens when two or more molecules hit and combine together; ω1 + ω2 → ω-.
The steps of the algorithm can be summarized as shown below and the pseudo code is shown in Figure 4.
- Starts with the initial population, which consists of a set of individuals where each one has a potential energy (PE). Some of the CRO parameters such that population size, number of iterations and buffer should be defined initially.
- Apply chemical reaction to generate new reactants.
- Update the potential energy.
- Repeat steps till reaching termination condition.
 Figure 4: pseudo code of the CRO algorithm
Figure 4: pseudo code of the CRO algorithm
2.4. Proposed scheme
This paper proposes an enhancement version over available face recognition schemes using a meta-heuristic algorithm to achieve a high level of accuracy and less error-matching rate. The original face recognition system consists of two phases: enrollment and matching. The system depends mainly on choosing a point as a pivot point and then calculate the distance between it and other face features. The data is then stored as a vector in the database for each image. The second phase compares the values of the registered user with the data stored in the database for matching and authenticating individual.
Our proposed scheme is implemented using two meta heuristic algorithms: first one is the improved face recognition using Genetic algorithm and second deals with a new version of face recognition using chemical reaction optimization algorithm. The goal of both algorithms is to enhance both accuracy level and decrease error rate of the matching process. The results from each one is conducted and compared to show which algorithm enhances accuracy and gives better results.
2.4.1 An improved face recognition technique using Genetic algorithm
Face recognition techniques depend on two main things: (a) finding pivot point to calculate distance between selected pivot and all other feature points and (b) dividing human face into different areas and assigning a specific weight value for each area, the area which have highest weight value will be the most important area which influences on matching process by reducing error rate of matching, especially when the individual image has some special characters like using glasses or mustache, in such cases the area with glasses will be assigned a low weight value so it will not affect that much on the accuracy of the recognition. An example of the image features used in the training is shown in Figure 5.
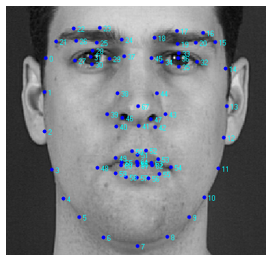 Figure 5: Example of image features
Figure 5: Example of image features
The GA is used first to select pivot point. Second, some of the feature can be excluded into an exclude array based on the nature of the image; the GA is used to change this array contents till reaching to the highest matching result and decreasing error rate. Third, GA is used to select best weight value for each of the face areas such that total weights for all must be equal to100%.
Genetic algorithm consists of different main phases as we explain previously: the fitness function here will be the matching value between entered image input and the one stored in the database.
Each of genetic main phases has a special work on our proposed idea. The following table presents different genetic algorithm phases and their mapping in our scheme.
Table 1: Mapping between different genetic phases and our proposed scheme to find heights match value
| Genetic Phase | Its meaning on our proposed idea |
| Individual | Pivot point, weight for each face area, set of excluded features points and distances from selected pivot and all feature points |
| Population | Set of individuals |
| Search Space | Different solutions founded through different iterations. |
| Fitness Function | Match values for testing data sets based on training data for all faces, best solution will have highest fitness value which mean highest match rate for different images which compared with all feature information saved on DB. |
| Crossover | Generate different values for pivot, face area weight, excluded array based on best solution with other solutions |
| Mutation | Random difference for generated solution based on specific value |
First solution will be generated randomly; different parameters will be generated from this solution such as selecting a pivot value, selecting weight for each of face area and set of excluded features to be avoided. All these values will be defined and generated through initialization step of genetic algorithm in order to build other solutions based on them. The fitness value is then evaluated and assigned for each individual in the set of solutions. Based on the fitness value the selection step starts.
Second step of genetic algorithm refers to selection step. Select a set of individuals from population with highest fitness value to be parents which will produce a new offspring with better fitness value.
Third step of genetic algorithm is crossover step; apply crossover between selected solutions and other solutions in the population in order to define a set of good solutions with highest match value (highest fitness value) as possible.
Last step of genetic algorithm refers to mutation step. This step is implemented to make changes in the new generation by multiplying it with a ratio value. This ration must be small between 0.01 and 0.025 of all population to change the solution.
After finishing all of these steps, a new solution will be generated with highest matching value and more accurate than original solution.
2.4.2 Face Recognition Using Chemical Reaction Optimization (CRO) Algorithm
In this section, the Chemical Reaction Optimization (CRO) meta heuristic algorithm is used for face recognition technique. CRO will be used to choose variables: pivot point, excluded feature points and different weights for face areas such as what we did when used GA. The main idea is to use CRO algorithm to select values for these important variables which influence on matching results. CRO generates better solution after each iteration till reaching best one. Table 2 presents some of CRO scheme meanings and their mapping to our proposed technique.
Table 2: Mapping between chemical meaning and its meaning on face recognition.
| Chemical Meaning | Its meaning on our proposed idea |
| Molecular Structure | Set of Solutions which found based on original solution |
| Potential Energy | Important variables value: Pivot value, Exclude array values, Weights value for different face areas |
| Kinetic Energy | Measure of tolerance to have a worse Solution |
| Number of Hits | Total Number of iteration used for specific experiment. |
| Minimum Structure | Current Optimal value for Matching based on Different variables values |
| Synthesis Interaction,
ω1 + ω2 → ω’ |
Two solutions with two Potential Energy combined with each other to select single solution with highest Potential energy which refers to highest match percent for all images. |
| Inter-molecule infective collision
ω1 + ω2 → ω1′ + ω2′. |
Two solutions with two Potential energy will produce a single solution with highest Potential energy value. By combining different steps of both solutions as select best exclude array values from one solution with face area weight from other solution to have a solution with highest match percent for all faces. |
| Decomposition
ω → ω1 + ω2
|
Single solution with specific potential energy will produce two new spate solutions with different potential energy for each by select some of main steps of match result from original solution and other steps will be selected randomly, so single solution will be divided to produce two single solution with j |
| On wall effective collision
ω → ω’ |
Single solution will be combined with other random solution where each solution has its own potential energy to produce a new with different potential energy from original solution. |
The proposed algorithm with CRO consists of a number of steps. Each of these steps has its fitness function value to find best matching for face recognition.
First step is initialization for face recognition using CRO. Through first step, a random selection is used to select pivot point, excluded features array and areas weight. Then the fitness function value is evaluated for each solution. As mentioned before, after each iteration of CRO execution, the population size will be different. We used ‘parent size’ variable to express population size. After each iteration it refers to generation size which produce new different solutions with different matching value.
The kinetic energy value must be defined in this stage, and molecule value also which must be between 0 and 1. Pseudo code for Initialization phase is given in Figure 6.
 Figure 6: Pseudo Code for Initialization phase
Figure 6: Pseudo Code for Initialization phase
Second step of face recognition using CRO refers to iteration stage. The main goal here is to generate different solutions based on initial solution. The initial values are produced through initialization phase, and new generated solution must be compared with all other solutions. Some of these new solutions will be better than original solution. The potential energy is objective function or fitness function for generated solution. Through this stage, different molecules are selected based on the value of variable β, where the value of β will be selected randomly between “0” and “1”. As shown in Figure 7 for pseudo-code at line number 1, if the value of the variable β is larger than the value of the variable “molecule,” then one molecule will be selected. Otherwise, two molecules will be selected; each of them is a separate solution. The pseudo-code for second phase of Face recognition using CRO algorithm is given in Figure 7.
 Figure 7: Pseudo code for second phase of Face recognition using CRO.
Figure 7: Pseudo code for second phase of Face recognition using CRO.
Third phase of face recognition using CRO refers to reaction phase, which is the final stage. When reaching to a specific value and to number of predefined iterations, then this algorithm is stopped. Next, different solutions must be found and each of them has its potential energy which is number of matching faces. The output from this stage is the best solution, with highest objective function or matching value. This solution contains specific value for all variables: a pivot value, excluding feature points and weight values for all face areas. Number of selected solutions will lead to different interactions between molecules or solutions. When number of selected molecules is one, then the possibility of some interactions that depends on single molecule interaction will be as follows:
On-wall-infective collision: This interaction depends mainly on single molecule interaction with the wall of container which contains all different solutions. The output from this interaction is a new molecule with different structure produced ω → ω’ as in [17]. Pseudo-code for on-wall effective collision through our proposed idea is shown in Figure 8.
 Figure 8: Pseudo-code for on-wall effective collision
Figure 8: Pseudo-code for on-wall effective collision
Second type of interaction refers to decomposition interaction. It deals with second interaction, which depends on single molecule with molecule containers. The difference here is that the output from this interaction is to divide the original molecule into two different molecules with same structure as follow: ω → ω1 + ω2. The pseudo-code for this interaction is shown in Figure 9.
If there are more than one molecule selected, the possibility for other interactions to occur between different selected molecules happens. These interactions between molecules are Synthesis interactions which happens when two molecules of solutions in our scheme interact with each other to generate new single solution from interacted solutions as follow: ω1 + ω2 → ω’.
3. Experimental Results
Both proposed ideas to enhance matching results for face recognition technique were implemented using java-programming language on Net Beans 8.1, through our implementation. We compared matching values of original face recognition algorithm with our proposed scheme. There are different results based on different parameter. First result deals with face recognition using Genetic algorithm for different iterations with same generation size. Obtained results collected from implementing this approach were compared with results from original scheme of face recognition using same data sets as shown in Table 3.
 Figure 9: The pseudo-code for this interaction
Figure 9: The pseudo-code for this interaction
Pseudo-code for synthesis interaction is shown in Figure 10.
 Figure 10: Pseudo-code for synthesis interaction
Figure 10: Pseudo-code for synthesis interaction
Table 3: Results for implementing Face recognition using Genetic algorithm for different number of iterations
| Iteration Number | Matching Percent values Using Genetic | Original Face Recognition |
| 3 | 77.50% | 71.30% |
| 6 | 82.50% | 67.30% |
| 9 | 85.60% | 67.30% |
| 12 | 87.10% | 67.30% |
| 15 | 88% | 67.30% |
| 18 | 91.20% | 67.30% |
| 21 | 93.20% | 67.40% |
| 24 | 95.10% | 67.30% |
| 27 | 95.80% | 67.30% |
| 30 | 95.30% | 67.30% |
Table 3 contains results for implementing Face recognition using genetic algorithm for different number of iterations from 3 to 30 iterations. Each experiment has a specific iteration number with fix generation size. Best match results achieved when number of iteration is equal to 30 iterations. As the number of iterations increased the accuracy matching result increase. Figure 11 presents the relation matching accuracy versus number of iterations for face recognition.
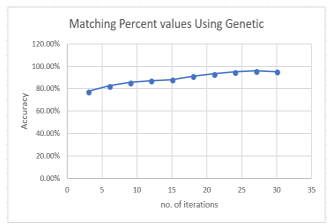 Figure 11: Relation between matching accuracy versus number of iterations for face recognition using Genetic algorithm
Figure 11: Relation between matching accuracy versus number of iterations for face recognition using Genetic algorithm
Table 4. Result for implementing face recognition using genetic algorithm for different generation size.
| Generation Size | Matching Percent values Using Genetic | Original Face Recognition |
| 5 | 82.83% | 67.30% |
| 10 | 83.74% | 67.30% |
| 15 | 86.80% | 67.30% |
| 20 | 89.85% | 67.30% |
| 25 | 89.6% | 67.30% |
| 30 | 89.9% | 67.30% |
| 35 | 91.3% | 67.40% |
| 40 | 92.1% | 67.30% |
| 45 | 92.6% | 67.30% |
| 50 | 93.7% | 67.30% |
Second experimental implementation for our proposed scheme refers to use different generation sizes with fixed number of iterations; generation size here starts from 5 to 50 where iteration size is the input for meta heuristic algorithm to generate new solutions. The results are shown below. Table 5 results refers to implementing other proposed schemes for enhancing face recognition results using chemical reaction optimization (CRO) for different number of iterations with fixed generation size.
Table 5: Results for implementing face recognition using CRO algorithm for different number of iterations
| Iteration Number | Matching Percent value Using CRO | Original Face Recognition |
| 3 | 71.65% | 67.30% |
| 6 | 76.71% | 67.30% |
| 9 | 83.30% | 67.30% |
| 12 | 85.86% | 67.30% |
| 15 | 82.1% | 67.30% |
| 18 | 87.86% | 67.30% |
| 21 | 87.1% | 67.40% |
| 24 | 89.8% | 67.30% |
| 27 | 91.92% | 67.30% |
| 30 | 92.83% | 67.30% |
Figure 12 presents the relation between number of iterations used for face recognition and matching value for Face recognition using CRO algorithm as follow.
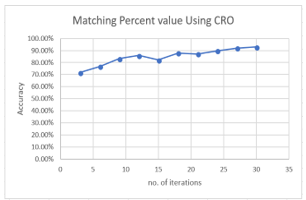 Figure 12: Relation between matching accuracy and number of iterations for our proposed scheme of face recognition using CRO algorithm.
Figure 12: Relation between matching accuracy and number of iterations for our proposed scheme of face recognition using CRO algorithm.
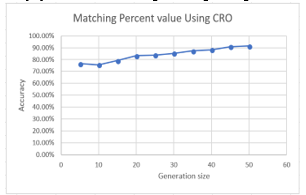 Figure 13: Relation between generation size and matching value for face recognition using CRO algorithm
Figure 13: Relation between generation size and matching value for face recognition using CRO algorithm
Figure 13 presents the relation between matching percentage and generation size for face recognition using CRO algorithm. Other experimental implementation was for different generation sizes started from 5 to 50 with fixed value for iteration. Results for implementing face recognition using CRO algorithm are shown in Table 6.
Table 6: Results for implementing face recognition using CRO algorithm for different generation sizes.
| Generation size | Matching Percent value Using CRO | Original Face Recognition |
| 5 | 76.5% | 67.30% |
| 10 | 75.7% | 67.30% |
| 15 | 79.2% | 67.30% |
| 20 | 83.25% | 67.30% |
| 25 | 83.75% | 67.30% |
| 30 | 85.3% | 67.30% |
| 35 | 87.40% | 67.40% |
| 40 | 88.31% | 67.30% |
| 45 | 90.90% | 67.30% |
| 50 | 91.4% | 67.30% |
3.1. Comparison between CRO and Genetic algorithms for Face recognition
In order to compare between the accuracy of face recognition technique when using Genetic and CRO, the generated results are compared based on two criteria; number of iteration and generation size. The results for the number of iterations comparison are listed in table 7 and shown in Figure 14. It shows that in both algorithms, as the number of iterations increases, the recognition accuracy increases where CRO algorithm shows higher accuracy rate for the maximum number of iterations than Genetic algorithm.
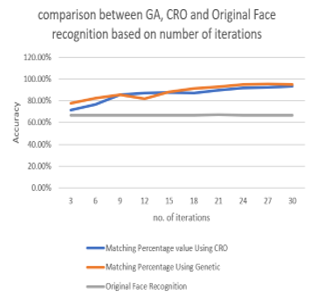 Figure 14: Comparative results of matching accuracy vs. number of iterations of both new approaches with original standard approach
Figure 14: Comparative results of matching accuracy vs. number of iterations of both new approaches with original standard approach
Table 7: Comparison result for both approaches with original approach based on number of iterations
| Iteration Number | Matching Percentage value Using CRO | Matching Percentage Using Genetic | Original Face Recognition |
| 3 | 71.65% | 77.5 % | 67.30% |
| 6 | 76.71% | 82.5% | 67.30% |
| 9 | 85.86% | 85.6% | 67.30% |
| 12 | 87.1% | 82.1% | 67.30% |
| 15 | 87.86% | 88% | 67.30% |
| 18 | 87.1% | 91.2% | 67.30% |
| 21 | 89.8% | 93.2% | 67.40% |
| 24 | 91.92% | 95.1% | 67.30% |
| 27 | 92.3% | 95.8% | 67.30% |
| 30 | 93.7% | 95.3% | 67.30% |
Table 8: Accuracy of matching in percentage between both approaches based on Generation Size.
| Generation size | Results for Proposed Approach using CRO | Results for Proposed Approach using Genetic | Original Face Recognition |
| 5 | 76.5% | 82.83% | 67.30% |
| 10 | 75.7% | 83.7% | 67.30% |
| 15 | 79.2% | 86.8% | 67.30% |
| 20 | 83.7% | 89.6% | 67.30% |
| 25 | 83.7% | 89.85% | 67.30% |
| 30 | 85.3% | 89.9% | 67.30% |
| 35 | 87.4% | 91.3% | 67.40% |
| 40 | 88.31% | 92.1% | 67.30% |
| 45 | 90.90% | 92.6% | 67.30% |
| 50 | 91.4% | 93.7% | 67.30% |
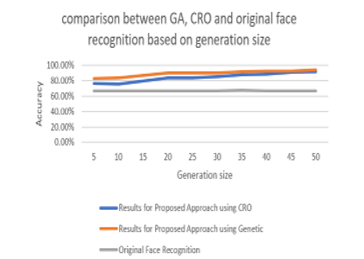 Figure 15: Results for Comparing the three approaches based on generation size.
Figure 15: Results for Comparing the three approaches based on generation size.
Comparing the two algorithms for different generation size are listed in table 8 and shown in Figure 15. The comparison results show that for bigger generation size the accuracy rate increases and CRO algorithm gives higher accuracy rate for the maximum generation size.
4. Results Discussion
The proposed work gives a new contribution in the face recognition technique which depend on three main criteria:
- Selecting a pivot point.
- Excluding some features into an exclude array base on the nature of the image.
- Dividing the face into areas and assign a weight for each one.
Two heuristic algorithms were used in order to select best values for these variables, the Genetic and CRO. The aim of using such algorithm is to enhance searching results and get optimal solution. In our contribution, applying the heuristic algorithm on the face recognition technique gives more accurate results, as the algorithm searches for the best node in the image to be a pivot while the original technique select randomly a node as a pivot. The pivot node selected by the genetic and CRO is the node that is at the center of the image where we can evaluate distance between it and all other point in the image which will give an accurate estimation for the feature and thus will affect on the matching result and reduce error rate.
From the extracted features we can decide which features are important and which are not. For example, in the case where the image gas a special character like glasses the area around the eye will gives less matching results when it compared with the same image but without such glasses, so excluding this feature from the comparison will gives better result as shown previously.
By dividing the face image into a number of areas and assign a weight value for each one depending on the features for each area give a better accuracy for matching, some areas may be affected by different factors like brightness, shadow, etc. by assigning a low weight for those areas and higher value weight for the clear one affect much on the matching and increases accuracy.
The heuristic algorithms help on achieving that, as each algorithm depends on the number of iteration and generation size, the results show that as the number of iterations increase the matching accuracy increase as each algorithm training become near to its optimal solution. On the other hand, as the generation size increase the accuracy also increases, which means using more features and points from the image will increase matching results.
5. Conclusions
This paper presents a new methodology for face recognition by using two meta-heuristic algorithms: Genetic Algorithm (GA) and Chemical Reaction Optimization Algorithm (CRO). The aim of the proposed work is to enhance matching results for face recognition by increasing accuracy and decreasing error rate. Three criteria were taken into consideration throughout our work: the selection of the pivot point, excluding unnecessary features, dividing the face image into areas and assigning a weight value to each area. The GA and CRO were used to implement these criteria and generate a best solution. A dataset of 371 images was used for the training and testing phases. The results for each run were compared with the original standard face recognition technique and showed that GA and CRO enhance matching face recognition by achieving more than 20% accuracy over original technique.
- Aoun, N.B.; Mejdoub, M.; Amar, C.B. Graph-based approach for human action recognition using spatio-temporal features. J. Vis. Commun. Image Represent. 2014, 25, 329–338.
- El’Arbi, M.; Amar, C.B.; Nicolas, H. Video watermarking based on neural networks. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 1577–1580.
- El’Arbi, M.; Koubaa, M.; Charfeddine, M.; Amar, C.B. A dynamic video watermarking algorithm in fast motion areas in the wavelet domain. Multimed. Tools Appl. 2011, 55, 579–600.
- Wali, A.; Aoun, N.B.; Karray, H.; Amar, C.B.; Alimi, A.M. A new system for event detection from video surveillance sequences. In Advanced Concepts for Intelligent Vision Systems, Proceedings of the 12th International Conference, ACIVS 2010, Sydney, Australia, 13–16 December 2010; Blanc-Talon, J., Bone, D., Philips, W., Popescu, D., Scheunders, P., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6475, pp. 110–120.
- Koubaa,M.;Elarbi,M.;Amar,C.B.;Nicolas,H.Collusion,MPEG4compressionandframedroppingresistant video watermarking. Multimed. Tools Appl. 2012, 56, 281–301.
- M.S. Obaidat and N. Boudriga,” Security of e-Systems and Computer Networks, Cambridge University Press, 2007.
- Mejda Chihaoui *, Akram Elkefi, Wajdi Bellil and Chokri Ben Amar, “A Survey of 2D Face Recognition Techniques”, REGIM: Research Groups on Intelligent Machines, University of Sfax, National School of Engineers (ENIS), Sfax 3038, Tunisia; Elkfi@gmail.com (A.E.); wajdi.bellil@ieee.org (W.B.); chokri.benamar@ieee.org (C.B.A.) * Correspondence: mejda.chihaoui@ieee.org; Tel.: +216-5460-1073
- D. Yi, Z. Lei, and S. Z. Li, “Towards pose robust face recognition,” in Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on. IEEE, 2013, pp. 3539–3545.
- N. Jindal and V. Kumar, “Enhanced face recognition algorithm using pca with artificial neural networks,” International Journal of Advanced Research in Computer Science and Software Engineering, vol. 3, no. 6, 2013.
- Pratibha Sukhija, Sunny Behal, Pritpal Singh, “Face Recognition System Using Genetic Algorithm”, International Conference on Computational Modeling and Security (CMS 2016).
- Ravi Subban, Dattatreya Mankame, Muthukumar Subramanyam,” Genetic Algorithm based Human Face Recognition”, Proc. of Int. Conf. on Advances in Communication, Network, and Computing, CNC
- https://personalpages.manchester.ac.uk/staff/timothy.f.cootes/data/xm2vts/xm2vts_markup.html.
- D.E. Goldberg, Genetic Algorithms in Search, Optimization & Machine Learning, Addison-Wesley, Reading, MA, 1989.
- John H. Holland ‘Genetic Algorithms’, Scientific American Journal, July 1992.
- KalyanmoyDeb, ‘An Introduction To Genetic Algorithms’, Sadhana, Vol. 24 Parts 4 And 5.
- A.Y.S. Lam, V.O.K. Li, “Chemical reaction optimization: a tutorial”, Memetic Computing 4, 2012, pp. 3–17.
- Albert Y. S. Lam and Victor O. K. Li, Chemical reaction optimization: a tutorial, Memetic Computing, Vol. 4, No. 1, 2013.