Modeling Double Subjectivity for Gaining Programmable Insights: Framing the Case of Uber
Modeling Double Subjectivity for Gaining Programmable Insights: Framing the Case of Uber
Volume 2, Issue 3, Page No 1677-1692, 2017
Author’s Name: Loretta Henderson Cheeks1, a), Ashraf Gaffar2, Mable Johnson Moore3
View Affiliations
1School of Computing, Informatics, and Decision Systems Engineering (CIDSE), Arizona State University, Tempe, AZ, 85287, U.S.A.
2School of Computing, Informatics, and Decision Systems Engineering (CIDSE), Arizona State University, Mesa, AZ, 85212, U.S.A.
3Chief Information Officer, Savannah State University, Savannah, GA, 31404, U.S.A.
a)Author to whom correspondence should be addressed. E-mail: loretta.cheeks@asu.edu
Adv. Sci. Technol. Eng. Syst. J. 2(3), 1677-1692 (2017); ![]() DOI: 10.25046/aj0203209
DOI: 10.25046/aj0203209
Keywords: Subjectivity, Artificial intelligence, Frames, News source sentiment, Disruptive technology, Social influence, Online news, Amplification, Machine learning, Natural language processing, Uber

Export Citations
The Internet is the premier platform that enable the emergence of new technologies. Online news is unstructured narrative text that embeds facts, frames, and amplification that can influence society attitudes about technology adoption. Online news sources are carriers of voluminous amounts of news for reaching significantly large audience and have no geographical or time boundaries. The interplay of complex and dynamical forces among authors and readers allow for progressive emergent and latent properties to exhibit. Our concept of “Double subjectivity” provides a new paradigm for exploring complementary programmable insights of deeply buried meanings in a system. The ability to understand internal embeddedness in a large collection of related articles are beyond the reach of existing computational tools, and are hence left to human readers with unscalable results. This paper uncovers the potential to utilize advanced machine learning in a new way to automate the understanding of implicit structures and their associated latent meanings to give an early human-level insight into emergent technologies, with a concrete example of “Uber”. This paper establishes the new concept of double subjectivity as an instrument for large-scale machining of unstructured text and introduces a social influence model for the discovery of distinct pathways into emerging technology, and hence an insight. The programmable insight reveals early spatial and temporal opinion shift monitoring in complex networks in a structured way for computational treatment and visualization.
Received: 31 May 2017, Accepted: 10 August 2017, Published Online: 04 September 2017
-
Introduction
1.1. What is Insight?
This paper is an extension of work originally presented in 2017 IEEE 11th International Conference on Semantic Computing (ICSC) [1]. The Internet is the premier platform for the proliferation of voluminous online news and has been compared to a huge social and psychological laboratory [2]. It has enabled a globally and connected world which is greatly transforming computational approaches for exploring online social interactions for gaining early insight into emergent technology. News sources propagate online news that function within a complex and dynamic system via the Internet. This system comprises informational flows, interactions, dynamical forces, and emerging properties, which lead to asymmetries and have a tendency to influence society. Online news is a form of narrative text that embeds facts and strategic communication frames for shaping and transforming group standards, values, attitudes, and beliefs about technology adoption. The embedded facts represent absolute, relevant truths characterized by their rigid (or fixed) nature. These absolute truths are shared among news sources. However, purely factual articles would be hard to write and read. Adding tone, writing style, attitude, opinions, related context, and non-factual comments and arguments often make text more subjective but easier to read. The exercise of news framing—and the amplification of subjectivity that it communicates—is where multidimensional aspects of the content emerge and where expressivity happens for transformational and maximal influence. Framing is the use of strategic devices for presenting prominent aspects and perspectives about an issue using certain words as well as stereotyped images and sentences for the purpose of conveying hidden meanings about an issue [3].
News sources play a critical role in the activation of frames about technology society adopt, and the amplification of subjectivity in online news drives a wedge between evidence and beliefs [4]. In addition, the combination of facts, frames, and amplified subjectivity represents instruments that offer a space of possibilities for deeper exploration of the cognitive aspects of narrative text. Natural Language Processing (NLP) made significant progress using Artificial Intelligence (AI) to parse narrative text by applying analytical techniques. However, less success has been made with computational treatment when it comes to semantic levels. Semantic parsers work well only at a phrase level, but it becomes challenging to semantically parse several sentences together. Some approaches can look for keywords to determine the sentiment of a text, provide a summary, or a basic language-to-language translation, but they remain by far limited in understanding the deep latent meanings which contribute to the richness and depth of ideas within a complete text or of a related set of articles at the same level humans do. We define this as an “Insight” which is “the ability to understand the latent meanings within an article”. The definition of Insight can be generalized to a group of related articles, and refers to “the ability to synthesize the relationship between a group of articles as well as how the contents of latter articles were affected or influenced by those in earlier articles of the same group.” The need to understand this insight becomes particularly important with online news, as the number of related articles tend to be generally larger than printed media due to the far reach and hence the significantly larger and more diverse readership of the Internet. This “understanding” process is typically highly cognitive, and is best done by humans. However, with the large number of online news, the need for software tools becomes essential for gaining programmable insight at a very large scale. We define programmable insight as “the ability to apply computational models and methods and hence software tools to leverage human cognitive ability to gain insight into very large narrative text”.
1.2. Challenges of Processing Subjective Text
When attempting to identify potential pathways to address the complexities and dynamics that exist in online news text, frames are instruments for experimenting and learning about the production of language and forces at work for gaining programmable insight that may lead to new instruments for exploring cognitive computation. Here, pathways mean the potential routes that one may take to explore patterns about a subject. The authors recognize the need for an integration of multiple models and perspectives that advance what is known about hidden meanings and latent structures in text. Modeling narrative text allows software tools to provide help in automating human efforts using computational leverage. However, providing a deep model that represents hidden meaning in text is relatively hard. Several NLP methods in artificial intelligence use word matching and probability functions to determine the correctness and possible meaning of words with the help of language corpus containing trillions of words. This “brute force” and highly analytical top-down approach could be computationally heavy, and does not provide an insight beyond the phrase level. An acknowledgment of the multidimensional aspects—degrees of freedom—of the narrative text in news calls for computational research to fill knowledge gaps and to transform the current understanding of alternative pathways to learning that leverage cognitive science research.
Leveraging the scholarly work of mathematicians, the fathers of the digital computer developed the initial logical machine using a rather formal grammar structure. The first level of grammatical expressivity the computer machine could understand is propositional logic—that is, knowledge of facts or truths. Considering the “form” of the English language (i.e., subject, verb, object), the logical machine could make valid arguments using as few as two premises and simple symbols, thereby drawing a logical conclusion. Propositional logic became the basic component of symbolic logic. It became the enabler for the logical machine to reason using simple English grammatical structure. This breakthrough led to machines being able to reason as either true (1) or false (0), using simple binary symbols and boolean algebra to express “and,” “or,” “not,” “implies/then,” and “if and only if.”
By switching out fixed sentence structure for symbols, as was done in mathematics for centuries, the logical machine could express a primitive level of truth. The computer could express with “0” or “1” with this simple syntactical machine code. Although this advanced in the logical machine was very impressive in its day, this level of formalism with its strict grammatical structure falls short of reaching the goal of AI, as it gave no insight into the topic proposed in the sentence structure.
Propositional logic usage in the logical machine had no properties nor a sense of relationships, all of which were embedded in the internal structure of the text. Rather, its sole focus was on pure factual, blocks of sentence structures as isolated objects for expressing what logicians for centuries thought to be real. Real objects were point masses and forces; as such, properties leading to an understanding about the relationships and internal structures of text were dismissed as subjective. Discounting relational properties as the inferior status of “secondary” properties resulted in excessive adherence to the theoretical approach of attaining machine intelligence. However, researchers soon came to realize that if there is any future for theory, it must be applied. This meant that the internal structure in text must delve into deeper levels of expressivity where hidden meanings and relationships could be explored for advancing machine intelligence. Since this time, as shown in Fig. 1, numerous levels of machine logic have been established to allow for the variety of properties to reason about relationships, individuals, identities, and quantifiers—thereby, giving way to make more elaborate assertions, inferences, and semantic expressions of phrases. Fig. 1 shows the progressive climb up the stack from the formal space where computer machines focused on propositional logic, formal grammar, and, thereafter, phrases.
With the pendulum swinging from machine-to-human logical expression—where the programmer of the computer machine had to learn the psychology of the machine—to human-to-machine logic for expressing rational human thoughts, higher-level programming languages were developed, such as Fortran, Prolog, and Lisp. With the foundations for reasoning and with higher levels of expressivity at the researcher’s grasp, attention turned to another field of research, AI.
Here, at the phrases layer (NLP using AI) is where much of the computer science research today continues to focus. This has led to great breakthroughs for learning AI, NLP, and fuzzy logic; however, this approach shed very little insight into cognitive computation.
This research advances beyond the phrases layer and bridges the computational and cognitive worlds using the instrument of
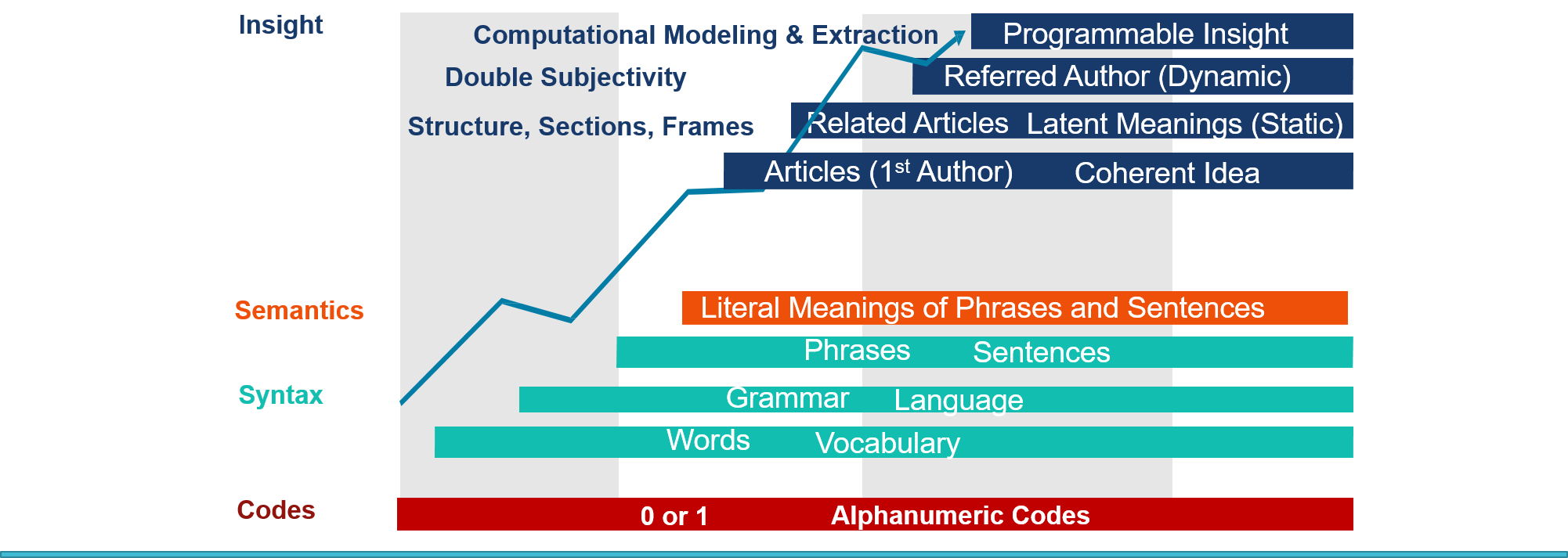
frames that exist in narrative text for exploring programmable insight that may lead to deeper learning for machine intelligence.
In exposing the discovery of new knowledge about text, transformations (or shifts) in which dynamic forces reach a critical point make clear the new structures, pathways, and influence patterns to be accepted or new questions or alternatives in the scope of an issue to be revised. The ability to seek out novel, uncharted relationships that are implicit from a body of unstructured narrative text—yet not explicitly stated within that text—has obvious scientific value. This process is called “novel knowledge discovery.” It enables the use of the current state of knowledge for an emergence of possible new relationships and pathways that have yet to be studied.
1.3. Structured Expert Support (SES) Models
Fully structured data render itself easily to computation. A sales receipts generated by point-of-sale (POS) software in most retail stores includes a fully-structured list of items code, text, sale price as well as subtotal, total, date and time of each receipt. Terabytes of such data follow a well-known model and would be easy to process with software tools and provides solid foundation of business intelligence (BI) and other advanced insight, data science, and consumer-behavior pattern discovery. Narrative text, on the other hand, is highly unstructured and hence represent a nightmare to computational algorithms trying to extract deep knowledge buried within. One of the main reasons is the lack of a representative model that this data follow. While humans can understand and even enjoy the contents of such text, the lack of concrete models prohibits the computational treatment of such text. In the proposed approach, the authors use the framing theory—as will be shown later—to build representative models of narrative text. While these models need to be built by hand using human experts (thus the name expert support), they are done in a structured way to normalize human cognitive ability into nominal structure (hence the qualifier Structured Expert Support) as shown in Fig 2. Fig. 2 also is a graphical depiction of the process for discovering news frames. The formal problem definition of framing is presented as follows:
Let be a universe of online news documents at time . Let denote a finite subset of documents from the universe of documents , where is the total number of documents being considered. Let be the set of document properties, where is the source that produced the article and that propagates a central organizing idea (i.e., framing) and is the set of terms (i.e., features or content descriptors) from the news article where common words have been removed—all of which supply a context and suggest what the issue is through the use of selection, emphasis, exclusion, cues, and elaboration [5, 6]. For issues of interest, the process leads to the discovery of standard frames dominantly used in U.S. news coverage [7]: human interest, conflict, economic, managerial, and science. Let correspond to each of these frames, where each is associated with a pair { ; is the feature vector, and is the vector with the corresponding weights. Discover five dominate news frame signatures.
Humans would manually extract certain keywords present in a text, and build representative data structures (vectors) representing hidden meanings within the text. On the one hand, these vectors will be a strong representation of the hidden frames in a text, and -on the other hand- they will be highly structured and hence readily computational. As will be discussed later, the proposed SES relies heavily on the theory of framing as the modeling concept and the bridging mechanism between cognitive contents and computational capability of narrative text.
This manuscript includes a model for expressing the multidimensional aspects of news framing—and the amplification that it conveys—for transformational and maximal influence. The model is a pathway to explore programmable insight to expose a deep level of expressivity into the hidden structures in text—what is referred to in this paper as “double subjectivity,” a term introduced here [8]. Double subjectivity is the term to describe the secondary subjectivity that results after receiving indirect informal cognitive data in online news. The double subjectivity method expands Axelrod’s [9] and Klienberg’s [10-12] research on cultural dynamics and social influence for constructing an issues
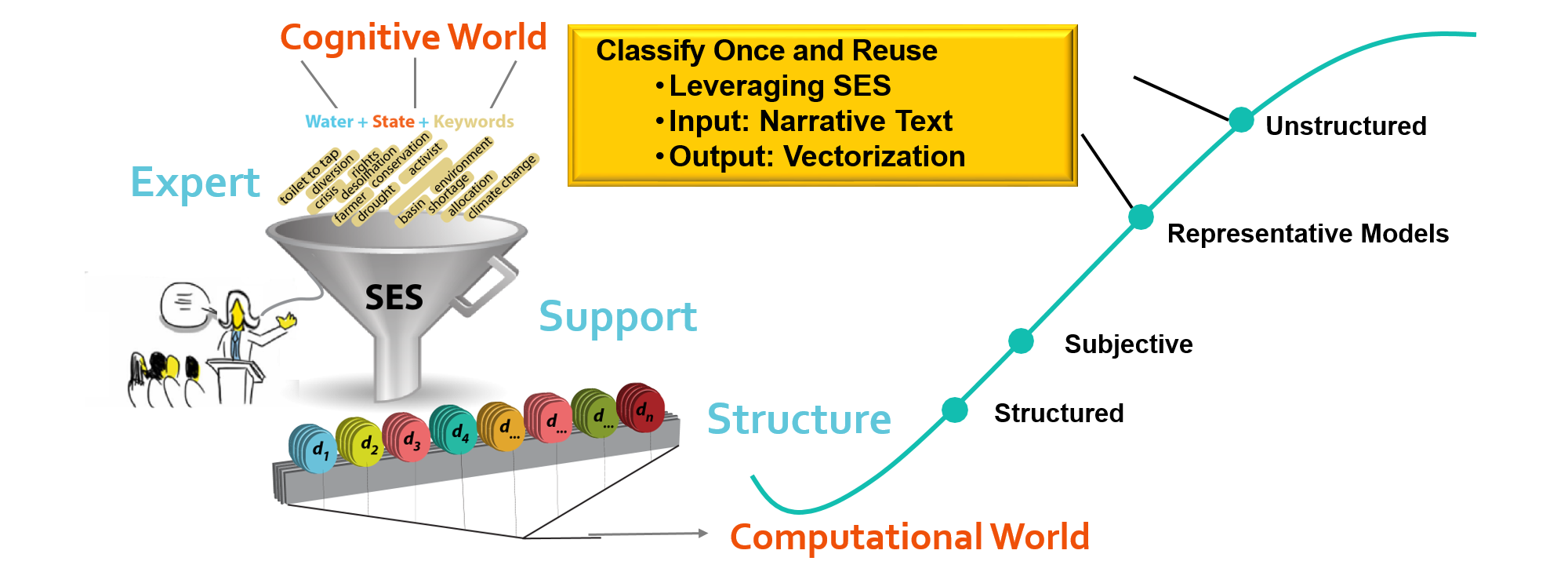 Fig. 2. Depiction of SES significance in the development of a representative model in support of the discovery of frames that exist in unstructured narrative text. Fig. 2. Depiction of SES significance in the development of a representative model in support of the discovery of frames that exist in unstructured narrative text. |
network representation and designing a visual language for exploring spatio-temporal dynamics. The issues network is exemplar of a complex dynamical system whereby migration paths may be visualized. The migration path is defined as the movement of frame choices in articles across a network to establish a new bridge for information exchange. The way the issues network grow (gain node connections) and shrink (loss node connections) is discussed in a subsequent section in this manuscript. The aim of the authors is to demonstrate news framing as a step toward deep learning about the production of language that may inform scholars about pathways that offer new approaches that advance cognitive computation for improved intelligent behavior in machines.
To the best of the authors knowledge, in computer science scholarly research, examining double subjectivity using online news and framing effects for gaining programmable insight has not been addressed previously for the class of problems discussed in this paper. This research inquiry will give insight into the following questions: What is the migration path of online news frames as it evolves over time? What is the effect of double subjectivity? What are the conditions observed that allow for the evaluation of shifts in influence or amplification intensity?
The following sections will describe the conceptual framework, related works, background on the issues of application, methods, possibility space transitions, observations of the models in action, and the conclusion.
2. Conceptual Framework
In the last decade, advances in fields such as AI, text summarization, and NLP have enabled gains in understanding text syntactic structure and limited gains in text semantics by offering algorithmic and theory-based methodologies. However, these fields have struggled in efforts to unlock hidden meanings and abstractions found in unstructured text such as jokes, poems, or art that are readily expressed through cognitive structures. This is due in large part to barriers that exist when using machine learning algorithms that are still limited in their understanding of complex unstructured text where factors such as semantic context, culture, and complex relationships must be considered for making sense of the narrative text.
Humans have the unique and superior ability to get beyond the syntax of data in order to make meaning. However, a great deal of cognitive science research has focused on cognitive structures called “frames” (sometimes “schemas”) that exist in the recesses of the brain [13]. The framing of online news articles by news sources consequently has the effect of evoking a word and phrase in the unconscious cognitive structure in the mind of the reader. These structures are built over time through repetition. The repetitive framing of critical issues will strengthen the circuits about the issue in a reader’s brain. When online news sources repeat frames often, they become “normalized” unconscious activation points in the brains of readers. This behavior by online news sources is equivalent to placing ideas in a container, referred here as an article. These ideas are sent through communication channels that have tremendous influence on the perception and real value of knowledge. When neighboring news sources take the ideas out of the container by way of adoption or copying, the cumulative effect is double subjectivity. A property of double subjectivity is spatio-temporal dynamics, which has the capacity to display a larger context of influence. As a number of related articles grows, the cumulative effect of subjectivity could grow and take on certain direction or shape, influenced by the article-to-article changes or the amplification or suppression of frames. This dynamic behavior may be best shown through a network visualization. A network visualization is a mechanism that has been used to leverage people’s ability to acquire knowledge for revealing hidden meanings, social influence, and migration paths of information and interactions.
The automation of unstructured text can be generally categorized under two main areas: computational data and cognitive data.
2.1. Computational Data
Computational data—represented by mathematical formulas, propositional logic, and formal (computer) languages—have little room for subjective interpretation and are typically concise, context-free, and fully predictable. For instance, a correctly developed source code can compile and run on a computing machine and will always produce the same output for a specific input. The combination of a formal set of instructions resulting from the successful compilation and run of source code can transition a computer through a set of well-defined states, depending exclusively on the compiled code and input data. This leaves no room for interpretation or subjectivity. In other words, the meaning and interpretations must be fully represented in the source code. A good programming language must, therefore, have sufficient expressiveness to fully represent a feasible solution in a specific problem space. If a source code arrives at an undefined state, it will simply freeze or crash; it is unable to make an independent decision. Some areas of computer science such as fuzzy logic and AI attempt to address these inherent limitations by providing a default or recovery system. Some languages also provide exception handling constructs and error recovery mechanisms. However, these approaches remain rigid mechanical methods, and are not the focus of the work conveyed here. This expresses the “formal space” as depicted in Fig. 4.
Although the computational language of source code is a good medium for communicating with computers, natural languages that embed cognitive structures are the mediums of communication among humans, and natural languages are informal and ambiguous in comparison to the computational language of computer code. In Fig. 4, the “informal space” is shown to describe the embeddedness of informal cognitive data structures that humans are superior over machines in conveying which are contained in narrative text. Cognitive data can be further divided into two subcategories, depending on the source of origination: direct and indirect.
2.2. Direct Cognitive Data
Direct cognitive data are the result of a person’s encounter with an event and the perception, in part, of its details firsthand. Human perceptions of events lead to personal interpretations of events. Interpretation depends greatly on the viewer’s perception, as different people can arrive at different interpretations of the same event. Perception is often associated with the viewer’s state of mind, prejudice, background, and beliefs. Two persons witnessing the same event or being involved in the same situation could assign different interpretations and end with separate conclusions. Although the external situation is the same (the perception of which is uniquely defined in this paper as the absolute baseline), it could be internalized differently by different people. Such a case is a first-level subjectivity. Even when different people are asked to report an incident or a situation (the same absolute baseline), different accounts are often the result, indicating first-level subjectivity. Many factors further affect this subjectivity:
- Subjectivity: Humans have different expressive abilities and styles in reporting events using natural languages, leading to increased subjectivity.
- Ambiguity: The ambiguity of natural languages allows for different interpretations of spoken or written sentences.
- Complexity: Complex, extended situations, such as movie showings, are harder to perceive and interpret compared to simple or atomic events like the occurrence of a rocket launch.
- Expressiveness: Unlike a computational language, a natural language does not fully express the contents in its syntax. Natural languages report about something, rather than fully describe an action, artifact, or event in a specific way.
- Context: Natural languages are highly context dependent. The same sentence could have different meanings in different contexts.
- Modality: Natural languages are often combined with other modalities like para-verbal communication, body language, and face impressions, which can influence the meanings or interpretation of spoken words.
The aforementioned factors explain why—even for different people directly witnessing the same situation—substantial subjectivity can be present in reporting or discussing an event that was mutually witnessed.
People often try to reduce first-level subjectivity. Television reporters try to abide by certain rules to maximize neutrality and leave it up to the viewers to build their own opinions freely. The scientific community tries to show the stated facts through rigorous research and scientific experiments in attempts to eliminate or reduce subjectivity. However, subjectivity is not so simple to discard. Consider newspaper and television reporters who are known for their opinions.
2.3. Indirect Cognitive Data
The Internet and World Wide Web have led to an explosion of indirect cognitive data although events can still be directly perceived and subjectively interpreted. Because of technology advancements, it is possible to receive a much larger number of events indirectly. Because these events are not directly witnessed, an absolute baseline is not available. Because knowledge of an event is often based on the written or spoken reports of others, the baseline will be relative to the reporter’s subjectivity or simply “float.”
With the acceptance of indirect reports and their interpretation, the receiver adds his or her own subjectivity. Again, no longer is the absolute baseline available. It is replaced with a reporter-relative baseline or a floating baseline. If the reporter’s subjectivity is strongly framed and influenced towards certain beliefs, the receiver of the account already starts with a baseline that is completely different from the absolute baseline. This new baseline could strongly affect the receiver’s beliefs. Double subjectivity is the term introduced in this paper to describe the secondary subjectivity that results after receiving indirect informal data. Fig. 3 illustrates the cumulative influence effects of double subjectivity.
The illustrated formula depicts a generic function for double subjectivity in online news. Here, the assumption is that there is an observer-dependent function , such that the level of subjectivity is the relative baseline of the situation or event dependent on firsthand account or cumulative effect. First-level subjectivity it is expressed as,
is an amplification intensity function with cumulative influence effects that depends on the person observing, then reporting a situation or event.
|
|
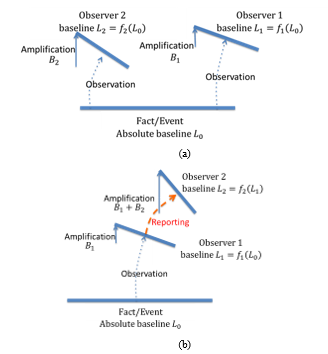
An analogy drawn from photocopying illustrates double subjectivity in that, ideally, a photograph copy should be a close replica of the copied photograph. Yet, in actuality, the resulting photograph is the copied photo with its amplification plus the distortion amplification gained from the copying process or machine.
Online news is exemplary of double subjectivity in that its assemblage consists of subjective properties such as context, interpretation, multimodal interaction, background, compensation, and assumptions. These properties are critical building blocks that characterize narrative text for its a) signification (i.e., the semantic content signifying an association or concept given a word, sentence, or phrase) and b) significance (i.e., the relevance, rank, importance, or capacity to make a difference). Unfortunately, there remain substantial gaps in advancing what is known about the production of language in narrative text where double subjectivity exists. Therefore, exploring deeper levels of expressivity with an emphasis on double subjectivity may inform a new direction in research.
3. Broader Impact of This Work
Discovering double subjectivity in narrative text poses a difficult problem, as it seeks to give insight and meaning to open-ended statements and indirect data. More complex structures within the narrative text provide an expansive landscape for advancing effective tools and crafting applications to automate many language-related tasks—for example, document summarization, automated text generation, and many others. To show the gains in logic and reasoning, Fig. 4 depicts advances made using current tools and new frontiers that double subjectivity may act as a bridge, such as poems, metaphors, idioms, jokes, art, and storytelling. This is to be achieved by exploring levels of narrative text.
Media attention and framing can influence society concern about a specific topic. To observe the potential pathway of cognitive, informal, natural language, the authors focus on Uber as a case study. Uber intersects the economic and technology domain with characteristics of emergence, complex and dynamical forces, and the amplification of frames. Uber uses data as foundation for transforming the transportation ecosystem. It has played a key role in shaping the shared economy that heavily rely on social influence and online news frames. The framing of an issue has an impact on the ultimate course of the issue. The ways that Uber use framing has a direct impact on dynamical forces, such as, accessibility, mobility, shared value, or policy outcomes. Uber is a good case because it is context specific, complex, and characterized by multiple interacting forces. Newspapers in the U.S. regularly produce in-depth articles about automation of machines, emergence of platforms, and the influence of the crowd that are published online. However, the general public often has little experience with understanding the underpinning dynamical forces at work. As an example, amplified framing is more likely to influence uninformed respondents [14] or respondents with reduced exposure to or interest in an issue [15].
Therefore, consumers attitudes and beliefs about emergence and behavior shifts are likely influenced by the way reporters frame this issue.
This research can generally apply to any large, unstructured dataset that is affected (or amplified) by framing. Therefore, it can be extended to other applications such as health, economics or political discourse. It may lend multiple benefits to analyses of other domains, such as politics or presidential elections: 1) a tool for measuring amplification intensity over time and in real time, 2) a framework for exploring the social influence attributed to the double subjectivity with its primary property being the unique cumulative effect afforded in an online news network, 3) a model for exploring the dynamic forces at work when shifts occur in attitudes and beliefs, and 4) a real-time visualization of these dynamic forces.
4. Related Works
In the literature reviewed, no computational treatments were identified to address a) the concept of double subjectivity for automatic emergence of knowledge of narrative text or b) a model for exploring the interactions and implications of news frame choices. However, several works were identified that have some relevance for the research topic.
4.1. Text Summarization, Text Data Mining, and Information Retrieval
In computer science, scholarly research on latent meanings in the association between terms and documents to reveal relationships is found in literature related to text summarization, text data mining, and information retrieval. The earliest paper on text summarization identified for the current report is a description of work at IBM in the 1950s [16]. In his work, the authors proposed that the frequency of a particular word provides a useful measure of its significance, and he identified the concept “term frequency” (TF), which states that it is possible to identify the significant terms based solely on the term’s calculated frequency within that document [16]. Term frequency relates to average information, or entropy, of a term or group of terms in the ranking of their relationship to each other.
Outstanding contributions to text data mining in the 1990s and beyond, with the advent of machine learning, include text representation and models construction [17-20]; data dimensions reduction re-search in feature extraction [21, 22]; and deep semantic mining [23].
The research on online news frames reported in this paper is motivated by framing theory, which focuses on understanding the latent meanings of observable messages in their contexts [15] and can provide important insight into how the presentation or framing of an issue affects the choices people make. Other disciplines have focused on framing. In linguistics research, similar approaches are also described as “latent semantic analysis” (LSA) [24]. Furthermore, social network analysis (SNA) focuses on the importance of relationships among interacting units [25].
4.2. Opinions and Social Influence
Whereas text data mining techniques and methods have given insight into first-level subjectivity, dynamic systems modeling provides insight into the double subjectivity that exists in narrative text. Models of social influence, cultural dynamics, and information diffusion (i.e., topic modeling, sentiment analysis, and opinion mining) are active areas of research [9, 1, 12, 13].
It has been posited that social impact theory explains the impact of a social group on an agent as being dependent on the prominence of the social sources, their proximity, and source group mass (i.e., the number in the group) [26]. Political opinions and Axelrod’s cultural dynamics model behave similarly to these models that capture the interplay between selection and influence [27-30].
4.3. Networks
The ability to visualize vast amounts of data clearly creates a capacity for gaining insights about critical issues affecting society. At the most basic level, a network is a collection of points joined together in pairs [31]. Using Graph Theory, the data points are called nodes (or vertices) and the pairs connections are called edges (on links). Graph theory provides a strong mathematical foundation that helps us in visualizing the information geometric (special) aspects like the relationships be-tween different news sources, as well as it’s progress and evolution over time (temporal aspects). Here, in this manuscript the terms nodes and edges are used. Networks is a powerful way to represent patterns of connections or interactions between the parts of a system [31]. The issues network is best expressed using a net-work to understand the underlying global and local structure of the network, the connections and interactions between nodes, the clusters of highly connected nodes, influence patterns, and migration paths.
5. Contextual Case
Founded in San Francisco, California in 2009, Uber Technologies describes itself as a transportation network company which develops, markets and operates the Uber car transportation and food delivery mobile apps [32]. In Ubers’ short history, the company that connects riders with drivers using the Uber mobile app has become one of the fastest growing companies in the United States and worldwide. With approximately $200K in seed capital from founders Travis Kalanick and Garrett Camp, UBER entered the market with an improved automated car service that offers better pricing over traditional taxi providers. This improved car service could be easily accessed on demand by consumers using a smartphone. It is on the basis of consumers shifts in values, attitudes, and behaviors from ownership to the shared economy—ride sharing—and the advances in technology that make access to product and services a realization that afforded Uber to become the prominent company it is today. In contrast to traditional taxi providers who own assets (e.g., cars, shuttles, or limousine), Uber use drivers cars for delivering convenience and efficiency. This change have inspired the shared economy to reframe the way in which businesses operate for reaching large numbers of people across cities in the United States and worldwide. As a result, the company has met many legal complications, court injunctions, complaints from taxi providers of unfair competition, and complaints from public utilities commissions about Uber’s lack of compliance to safety rules that are adhered to by traditional taxi providers. These challenges did not impede Uber’s influence and growth with its $68 billion paper valuation. In just 6 years, it surpass the valuation of 100 year-old companies like General Motors and Ford, as well as “traditional” short-term transportation companies like Hertz and Avis [33].
With Uber’s recognition of consumer behavior shifts and advances in technology as emergent properties within complex and dynamical systems, the company set out to chart an alternative way for delivering cars and convenience to consumers, particularly through the use of social influence and opinions formation in online media and narrative text. Harnessing, the power of social influence, Uber evinces their reliance on consumers, lobbyist, and elites as influencers in online media as they a) created a team for community management, social-media outreach, and the creation of articles about Uber in online media and b) enlist celebrities, VIPs, and elite investors (i.e., Morgan Stanley, Saudi Arabia’s Public Investment Fund, Goldman Sachs, and Fidelity Investments are among Uber’s billion dollar investors). The emergence of consumers shifts, technology advances, and the interplay of complex and dynamical forces provides a useful context in which to explore Uber’s approach to transform the transportation ecosystem through the use of social influence for gaining deeper understanding of the cumulative effects of double subjectivity and the expressive function that programmable insight offers.
Uber’s mission to “bring safe reliable transportation to everyone everywhere” [34] is accomplished using its unique software platform and infrastructure that enable the company to meet consumers transportation needs with data rather than traditional methods, such as steel, glass, rubber, and salespeople. Uber’s reliance on data to drive social influence and opinions formation, places a demand for the company to hire an enormous number of data scientist and data engineers to gain command of the vast amounts of data that derives from interactions between consumers, drivers, network traffic, pricing algorithms, and online media. These interactions leave traces of patterns about behaviors that indicate the interworking of forces that may go unnoticed due to the limitations of existing tools available in machine learning and NLP.
While text data mining techniques and methods have proven to give insight to first-order subjectivity (i.e., words, grammar, phrases, and sentences—syntax and semantics), complex and dynamical systems modeling offers insight into the cumulative effects of double subjectivity that exist in narrative text [8]. Uber’s data scientist use tools that allows for treatment of disassembled factors and/or forces, however Uber data analytics could benefit from an account for the composite of data over space and time as a whole, not just its parts. An assemblage treatment of data will give Uber the needed insight for understanding its effective use of social influence and data-driven techniques and technology that enables them to reframe transportation and logistics globally.
Uber’s data management and analytics can be improved on using the double subjectivity model for gaining programmable insights where spatio-temporal dynamics is the expected outcome as described in this manuscript. The double subjectivity model could benefit Uber by a) offering a visualization tool for managing data more efficiently, b) delivering accurate results of the various interacting factors and forces in a shorter time period that considers the spatio-temporal dynamics of incoming data, and c) a human level visualization tool. This could benefit Uber’s data scientists from doing data analytics individually on dissembled data factors and forces. According to [8], the cumulative effects of the double subjectivity model has the ability to apply computational models and methods and hence software tools to leverage human cognitive ability to gain insight into very large narrative text. As a result, the double subjectivity model graphs will improve the accuracy of solving abstract engineering and data problems and will give Uber a tool for getting a handle on their effective use of social influence for shifting values, attitudes, and behaviors.
5.1 Forces of Emergence, Change, and Conversion
Elucidating the underpinning forces at work in complex interactions and social influence—the capacity to affect or be affected—is essential for an adequate explanation of emergence, change, and conversion. There were a number of forces that converge to make Uber an attractor and help situate Uber as market leaders. The timing of Uber’s innovative mobile app coincides with shifts in consumers values and attitudes about ownership versus the shared economy. These shifts stem from forces of emergence, such as ubiquitous computing and mobility, economic pressures and recessions, the desire for improved conveniences, access to transportation in cities and communities where consumers were underserved or poorly served, a new awakening of limited resources, and Uber’s use of online media for propagating a message about their elite consumers. “Coverage of elites in articles is a property of particular interest in this study, as this factor has an effect on the bias intensity that news sources adopt over time [8].” According to Druckman [35, 36], the way elites frame an issue is a driving force for shaping public opinion. An example should help to clarify the implications the interplay of forces within the complex interactions and social influence that gave rise to Uber’s emergence. Elites are individuals in power relationships or positions of authority.
Imagine Uber decides to enter a city, it follows a number of aggressive steps to quickly penetrate the market. Uber enters a city secretly and uses the local media to influence consumers by letting others know that it has entered the market (i.e., free advertising). Likewise, a promotion offering first-time consumers free rides while marketing to recruit new drivers aggressively in the new city starts immediately. Uber ignores regulators or fights them with an army of lawyers. The causal effects of Uber’s entrance into a city is felt immediately as evidence by price reduction in transportation fares, an initial increase to drivers commissions, and large sign-up bonuses for on boarding drivers. Uber braces itself for the challenges that it must overcome when entering a city, particularly regulatory constraints and competitors complaints, therefore the company invest a great amount of their cash base (in billions) in lobbyist who act as carriers of influence in the online media and within policy makers circles. Leveraging consumers sentiment about the shared economy—ride sharing and a less expensive alternative to car ownership, Uber enlist consumers as influencers and carriers of their messaging in online narrative text as they report their support of more efficient and less expensive transportation services. According to [37], “Uber employees whose sole job in the ‘playbook’ is to gain political influence start pushing for regulations that legalize Uber’s operations. In almost all cases, this has worked and Uber is given the chance to gain a firm foothold in the city.” Economic forces caused by the recession of 2007 put into motion the need for individuals to seek alternative income sources as many Americans were experiencing unemployment and had much less disposable income. Uber drivers may work part-time and full-time with the freedom to set their own schedule. This income on demand is a perk for individuals needing to supplement their income or those who desire non-traditional work flexibility. What all this means is that Uber’s consumers, drivers, lobbyist, competitors, and other stakeholders adopt and copy Uber’s narrative of sharing, efficiency, and convenience which reporters use in online news. The double subjectivity model captures cumulative effects of copying and gives insight to complex and dynamical forces whereby gradual shifts in amplification-intensity in online news is made visible.
5.2 Uber’s Future — Double Subjectivity as a Key to Programmable Insight
Uber’s decision to rely on data for social influence affords the company to expand to new lines of business. For example, Uber recently expands to on-demand trucking, b) car-pooling, c) mass transit, and d) meal delivery services. A consequence of Uber’s expansion is the need to manage a vast amount of generated data on a daily basis—primarily narrative text—,this the human cannot scale through the hiring of more data scientist. Unfortunately, the existing tools machine learning and NLP has available to analyze these large quantities of data are designed for structured text which are inadequate for handling the Uber’s data. Furthermore, existing tools must go beyond identifiable variables involved in the spatio-temporal production of human-generated data to an understanding of the entire assemblage. This involves factoring in the interworking of complex and dynamical forces coupled with cultural dynamics and social influence such that effective adjustments may be made that will transform Uber’s generated data into information advantages.
Modeling double subjectivity provides a human readable tool in real-time whereby gradual cumulative effects are visible that considers identifiable variables and interactions between diverse forces. This tool may give Uber programmable insight into social influence effects and shifts in values, attitudes, and behaviors. A tool for gaining programming insight into how the myriad human and non-human variables and forces affect one another in associations for shifting values, attitudes, and behaviors should reveal more about Uber’s long-term capacity to grow using data as its driving force for market penetration.
6. Methods
6.1. Dataset Description
The news data for the study were collected from Google News,[1] a newsfeed aggregator. Each article was selected based on four characteristics: a) its publication by an online news source, b) the prominence of the news source that generated the articles, c) the frequency of news publications by sources over time, and d) the salient terms contained in the article. All articles were published on the Internet between January 2015 and March 2017.
Articles were gathered by limiting the search for keywords associated with Uber and transportation consequences. After the collection of the articles, the articles were stored in a database for undergoing data preprocessing that included removing errors and inconsistencies to improve data quality.
6.2. Issues Networks for Online News
The first step in the construction of an issues network for news frames is to define the nodes. The issues network is a collection of news sources and article nodes of interest joined together in pairs by edge connections. In this research, the news articles being published by online news sources and the news sources that generate the articles served as the nodes. Though the proposed model and network extends to most bodies of unstructured narrative text, where frame amplification may exist, this manuscript focus on the case of Uber for illustrating the way complex and dynamical forces effect shifts in attitudes, values, and behaviors. It is the reasoning of the authors that news sources play a critical role in the propagation of amplification about issues, and amplification in online news drives a wedge between evidence and beliefs [4].
Uber is transforming the way data is used for shaping on-demand transportation service. As such, one can expect that the number of articles being produced on the issue is an indicator of its prominence and the framing choices of the news sources. The framing of Uber case is key to shaping attitudes and values. Such framing also indicates areas of amplification. Connections are made between news sources through the capture of framing adoption over time as it happens during migration. Migration pathways can be understood as assemblages and adopters of online articles frames. This adoption is a result of the framing effects that happens when online news sources repeat a narrative and its neighboring nodes copy what is reported, thereby this news narrative increases prominence in the network and causes growth and clustering of the mass. Undoubtedly, reciprocal relationships (i.e., news sources using the same frame choice) can be valuable, but such relationships are a challenge to capture using the article content. This is largely due to news sources not crediting other news sources in reports. The resulting network aim is to capture structures that were created and maintained through repeated patterns of framing and to capture the migration path of those structures over time.
6.3. Graphs and Problem Formalization
Framing of critical socio-environmental issues in online news is a complex and dynamic social network, which can be studied as a graph, as it is here. Graph analysis has become important in understanding the dynamic process in the production of news frames. Graphs allow for the visualization of the social network, showing interdependency of actors (or nodes) in terms of the social relationships such as friendship, kinship, or financial exchange [38, 39]. Graphs represent objects where order and disorder coexist. Graphs serve well for showing social interactions, influence, migration paths, and framing effects. For instance, a graph may expose which news sources hold central positions that function as points of prominence, control, and stability and may show edges that act as highways for lead relationships and exchanges of news frames. These intertwined dynamics, coupled with the vast amounts of online news being produced daily, make graphs an important tool for visualization and analysis of information flows pertaining to critical issues.
The overarching research problem is expressed through the construction of an issues network, and the model of a news frame issues network is presented in this paper as a graph consisting of a) that denotes a set of source nodes containing elements and b) as a set of article nodes containing elements that operate within the time window . In general, indicates one discrete time step of a reporting period. Let be the set of source properties, where a) is the set of terms (i.e., sub-issue keywords or content descriptors) and b) is the dominant frame choice (identity) that the news source uses. Each relation has a corresponding set of edge connections, , directed/undirected as edge elements. The issues network subscript , corresponds to the total number of relations. The edge set represents the communication channels between node pairs. are children of ; therefore, they may inherit the properties of the parent news source, as shown in Fig. 5.
The relations (or rules denoted as ) for edge connections are as follows:
. A & A (articles to articles). A non-directional edge connection is constructed for when is the set of neighbors of such that represents articles with a similar sub-issue.
. A & S (articles produced by the same source). A directional edge connection is constructed for when is the source (or producer) of the set of neighbors of articles, where represents articles with similar sub-issues.
. S & F (sources with sub-issue to sub-issue with the same frame choice). A non-directional edge connection is constructed for when is the set of neighbors of such that shares the same dominant frame choice.
Problem: Given about issue, construct a graph for determining how frames are produced in online news media over time.
6.4. Model Setup
To model the news frame issues network, the authors of this paper propose formulating a new model for information feedback based on a social system. The new framework is within the tradition of previous frameworks. These are the previous models [27, 9, 11, 40, 41] for studying the evolution of personal position, social influence multi-dimensions, and forces that cause cultural shifts. Axelrod’s model [9] is built on two simple assumptions: a) selection, a phenomenon in which people are more likely to interact with those who are more similar to them, and/or to be more receptive to influence from those who are similar and b) influence, a term that describes the case in which interactions tend to cause similarity among interacting actors. The model proposed in the present study promotes the additional emphasis of amplification that emerges as double subjectivity in narrative text. Although the behavior of the proposed model is similar to that in Axelrod’s [9], when deciding how to interact in the network, the proposed model differs in that insight is given into the endogenous and exogenous forces that may be at play in dynamic systems. Therefore, the double subjectivity in the proposed social influence model integrates cultural dynamics extensions [9, 10-12, 42, 43] with the cusp catastrophe model [41]. The cusp catastrophe model is useful for describing nonlinear relationships such as those found in narrative text. In the proposed model, the particular focus is on the different forces at work in the amplified slant employed in news frames as it allows for the degrees of freedom whereby alternative pathways may be realized. The cusp catastrophe model allows for understanding the different forces at work when quantifying framing amplification and the migration path.
Conceptually, the switch from linear to nonlinear relationships involves taking into account not only a news source’s capacity to select (or affect), but also another news source’s capacity to be influenced (or affected). Thus, an important aspect of selection and influence is the characterization of dynamical systems not just by their properties, but also by their capacities.
Consider this contextual example. When a news event occurs that impacts society, it thereby becomes an issue. It is partly defined by its properties, such as the absolute baseline facts, as well as being in a certain state, like the event having taken place on a certain day. This same news framing, however, has the capacity to intensify its amplification that may have the causal effect of a revolt or erupti
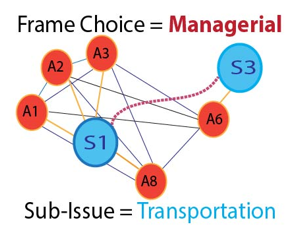 Fig. 5. A subset of the news frame issues network with two news source nodes with connecting articles using the same sub-issue and the same frame choice. The blue circles around notation show online news sources node that produced the article and propagates a central organizing idea (i.e., framing), orange circles around show an online news articles node, black lines show edge connections among neighboring articles on the similar issue, golden lines show edge connections of news sources who produce articles covering similar issue, and the red line shows a managerial news frame. Fig. 5. A subset of the news frame issues network with two news source nodes with connecting articles using the same sub-issue and the same frame choice. The blue circles around notation show online news sources node that produced the article and propagates a central organizing idea (i.e., framing), orange circles around show an online news articles node, black lines show edge connections among neighboring articles on the similar issue, golden lines show edge connections of news sources who produce articles covering similar issue, and the red line shows a managerial news frame. |
on by the people, an exacerbation of sentiment about a group of people, or the viral sensation of the news frame. This can happen through interactions with news sources that have the capacity to exercise strong amplification and to simultaneously weaken the agency of the people, group, or opposing view.
Properties are always reality based, since at any given point in time the facts—absolute baseline—are either true or false. Hence, facts are logical, formal, and rigid, but the causal capacity of news when exercising double subjectivity has a cumulative effect, which acts as a fabrication of what is real without being actual (or absolute). Unlike the limitations that facts in online news offer, amplification intensity within the construct of double subjectivity allows for the freedom to change dimensions through the parameterization of different forces—frame identity, justice, and amplification intensity—and distributions of sudden changes. The end effect is the perception of reality about an issue in online news that may offer new structure formations (or pathways) that lead to alternative views for shaping attitudes and beliefs. Stated differently, that which was only potential becomes a reality when changes in the different forces reach a certain critical threshold and a sudden jump happens. At this point, changes in beliefs can be tracked with the proposed model, even if the news framing amplification mechanism morphs the facts into something far from the truth.
The cusp catastrophe model calls this possibility space “the response surface space and control space,” which represents all possible states in the system. In this research, the relationship among frame identity, justice (or a sense of fairness), and amplification intensity are acknowledged through the cusp catastrophe differential calculus formula, which allows the measurement of the rapidity or slowness with which forces can change. In the geometric approach to the calculus, each degree of freedom becomes one dimension of a possibility space. The space of possible states in the system allows for the differential relations between them to determine a certain distribution of stable states around points or loops of attractions. They have a fractal dimension (intermediate between one and two) and are referred to as “chaotic attractors” [40]. Thom’s cusp catastrophe model [41] shows specific transitions of the forces, which have the tendency to cycle through the same set of states over and over [44].
The integration of cultural dynamics and the cusp catastrophe model for defining the new double subjectivity social influence model may shed insight into deep levels of expressivity in narrative text where amplification offers alternative pathways and possibilities. This remains an emerging research topic for understanding the production of language that may help in synthesizing vast amounts of unstructured text and learning online social behaviors.
The authors of this study explore the process that news sources use when producing online news articles. The main factors considered in this production are the facts, amplification intensity, and signals that derive from neighboring news sources. The signals that derive from news sources are likened to the reporter-relative or a floating baseline as mentioned previously. In the process of time, the news sources’ absolute baselines will undergo adjustments as the amplification intensity changes.
6.5. Double Subjectivity Social Influence Model
The proposed double subjectivity social influence model integrates cultural dynamics extensions [9, 10-12] with the cusp catastrophe models [41, 44] for modeling double subjectivity in narrative text. The cusp catastrophe model is useful for describing nonlinear relationships such as those found in narrative text. The cusp catastrophe model allows for understanding the forces at work when quantifying amplification and the migration path.
Online news sources tend to produce articles about an issue of interest to society, such as Uber emergence, changes, and sentiment that fosters shared value and cost savings. Additionally, news sources may receive signals from other news sources on the importance of the issue, based on observed increase to the number of articles other neighboring news sources produce. They receive facts about an issue. Each news source, then, selects a amplification strategy using as the basis of its calculation the amplification intensity. More specifically, each news source with interest in issue at time generates news articles
Problem: Given interactions within graph over time, determine the migration path and the nonlinear, causal linkages about .where and are the coefficients of the news source while are the facts received. Furthermore, it is supposed that corresponds to the endogenous propensity of the news source nodes to express its own amplification (or double subjectivity), while represents the exogenous force in the network. In the first interaction, set , denotes amplification intensity; this value will be calculated upon interacting with neighboring nodes and should change to give shape to the news source’s absolute baseline. Time evolves in discrete steps t = 0, 1, 2, . . ., and denotes the mass count on at time . The gives the sub-issue most important, a count of the largest cluster (the mass) of nodes reporting on an issue (case). This initialization of and provides access to new nodes to enter the overall conversation about Uber by linking to the most prominent mass, thereby, leveraging facts and the neighboring nodes of the relative baseline. This is similar to the operation observed in the hidden Markov model (HMM), whereby the news sources’ absolute baseline is hidden with adjustments made over time. In contrast, the relative baseline is likened to the observations one can make in the HMM for getting a sense of the state [45].
At the start of the process, each news source has a nonnegative node mass associated with it, corresponding to the fraction of the news sources that initially reports (i.e., through signaling) on similar sub-issues about Uber or transportation sub-issue. The dynamical system allows for each news source to switch frame choice, and sub-issue interest, thereby enabling random selection of news source interaction. Also, news sources are susceptible to being influenced when they interact with neighboring news sources that share similar amplification intensity. The full state space may be calculated by counting the news sources as expressed as the mass vector .
6.6. Defining Amplification Intensity
The quantification of amplification intensity is situated in terms of the mathematical catastrophe theory [41]. Catastrophe theory is a branch of nonlinear dynamic systems theory that originated with the work of the mathematician Rene´ Thom [41] to help explain biological morphogenesis as one of the great mysteries confronting mathematical biology. A key property in catastrophe theory is that the system under study is driven toward an equilibrium through its use of gradient descent or potential function for seemingly automatic guidance (i.e., through the law of attraction) occurring in the system, which is important in research on social influence, particularly when considering the property of convergence and stable states. The cusp model is the most well-known and the simplest model of catastrophe theory, positing that nonlinear transition within a system from one state to another is guided by two controlling variables: asymmetry and the bifurcation factor.
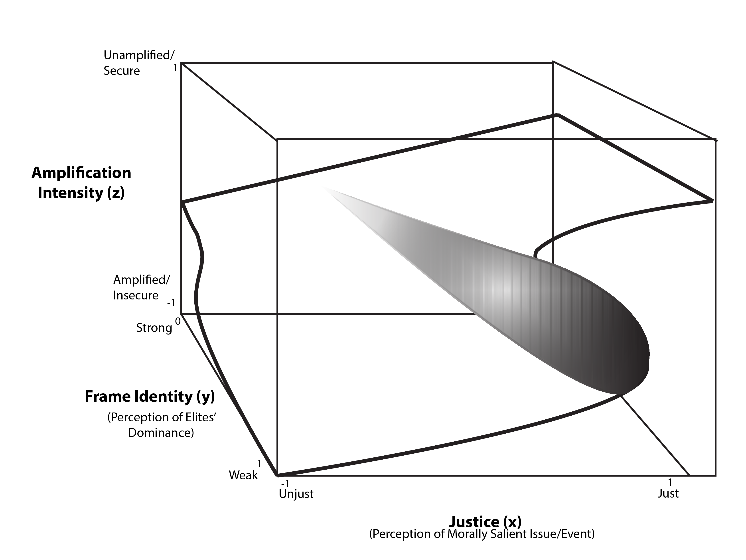 Fig. 6. The image depicts the cusp catastrophe model for measuring the shift in news sources amplification intensity.
Fig. 6. The image depicts the cusp catastrophe model for measuring the shift in news sources amplification intensity.
Consider, for example, the social and economic inequality movement Occupy Wall Street. What began as small grassroots pressure points to address pay inequality among fast food workers and Walmart employees has transitioned to giving voice to 99% of the U.S. population and moving the political conversation in the U.S. election. This transition, from a grassroots protest in Manhattan’s Zuccotti Park to making inequality and the wealth gap the core of the political race, is a catastrophe in accordance with catastrophe theory.
6.7. Model Variables Defined
Frames are a characteristic of human cognition structures, that operate simultaneously in human minds and texts. These latent structures of subjective interpretation are often produced and transmitted through the lens of power relations, hence elites [35].
The strategic use of managerial, economic, or conflict frames as expressivity in language embedded within online news, particularly when reporting on critical issues that impact society, have grave cost and consequences, which are far reaching. In the end, perceptions, beliefs, and attitudes by society become polarized or conflicted about critical issues even in the same domain, rather than society coming to a common consensus.
According to Lakoff [13], deep frame structures—where moral foundations exist—must be in operation in the mind during the production of language for justice about critical issues to prevail.
These emerging insights is justification for using justice in relation to frame identify as forces for understanding shifts in amplification intensity that lead to programmable insights about online news sources reporting on critical issues.
Fig. 6 graphically displays the possibility space of cusp model, an extension of the cusp catastrophe base model.
Let and be the aggregate count of the sets of frame choices obtained from the edge connection. is assigned the frame identity corresponding to its property at time .
Definition: Amplification is represented by , a projection on the behavior surface for predicting the migration path that shows the gradual shift in amplification intensity of the online news source when shaping the frame narrative about the issue under study. This factor is a measure of the strength of amplification—that is, “weak amplification” is considered safe and is represented by S(ecure), and “strong amplification” is considered insecure or harmful and is represented by I(nsecure).
Definition: Asymmetry control (or normal) factor is represented by . This factor receives the label Justice, denoted on a scale that ranges from . Justice is a measure of the news source’s perception of forces about fairness where a multi-dimensional formulation is a desirable consideration. A utility-like function, we call the “aggregate” variables comprising of accessibility, mobility, disposable funds, low cost for ride share, and ubiquitous wireless technology are used to summarize forces that give one a sense of Justice.
Definition: Splitting factor or bifurcation factor is represented by . This factor receives the label Frame Identity, denoted as . This is the perceived dominance by elites when reporting the news.
The authors, here, argue that Frame Identity and the perception of Justice are key forces for predicting the amplification intensity of news sources when producing articles about emergent technology.
Frame Identity is one form of amplification; it is shaped by strategic devices for presenting prominent aspects and perspectives about an issue using a strong slant for the purpose of conveying latent meanings about an issue [3, 35, 46]. The position of the authors is that Justice is of equal importance, as it captures the perceived sense of fairness about an issue. A discretized approach to opinion research has been conducted in scholarly research [44] and applications of cusp catastrophe [47, 48].
7. Visual Language
Traces of visualization for communicating ideas predates to thousands of years. Recently, attention has turned to the usage of visualizations for audience influence and persuasion. Most importantly, with the influx of big data on the Internet, visualizations have become the premier tool for exploratory data analysis that enables the formation of hypothesis about a network.
Visualization is a powerful human-oriented perception and comprehension tool. It provides special usability benefits, particularly when the goal is to monitor and analyze vast amounts of multi-dimensional data over time. Visualizations can provide insights into the spatial and temporal informational flows and dynamics, they allow for inference and discovery.
The properties of visual, spatial, and time are essential to building human intelligence. As this research introduces the double subjectivity social influence model for exploring the interplay of the dynamical system about critical issues. In this case, Uber.
In this research, a visual language that comprises alphabets for expressing nodes and grammar for expressing relational edge connections is presented. It is used for communicating double subjectivity cumulative effects for understanding the spatial-temporal dynamics underlying the network of collective influence of framing in online news and as a factor in the production of language in text narratives.
| Table 1. Visual language notations, symbols, and definitions | ||||||||||||||||||||||
|
||||||||||||||||||||||
The overarching research inquiry may be explored and is expressed through the construction of an online news frame issues network. Table 1 is the visual language for expressing and exploring the double subjectivity social influence model using the issues network for understanding the network structure and underpinning dynamical forces.
Given behavior of news sources when reporting on issues that impact society, like Uber, are complex, the interactions are not static, even when measured for very short intervals. The double subjectivity social influence model, make visible dynamics that may be easily missed in big data platforms, such as the Internet. The instruments identified in Table 2 may be used as probes for gaining programmable insights into the network and the forces at work.
This research offers a method for time stepwise transitions when navigating the dynamic online news issues network. The double subjectivity social influence model provides a mechanism for control over belief learning using the values of , while offers news sources inside signaling mechanism by leveraging historical knowledge about neighboring nodes.
8. Possibility Space for Transitions and Steady States
Nonlinear relationships represent a variety of possibilities and pathways of which the linear case is a limiting one. The authors propose to express the possibility space for the study using three variables as shown in Table 3. The possibility space represent simultaneous actuality and potential structures formed by differential interacting forces and distributions of singularities. The term singularities means an non-ordinary event that triggers a shift, such as, the repetitive framing of the need for car ownership in a way that bring into question its utility given its economic cost and utilization. The possibility space described here, at a minimum, is three-dimensions as we consider frame identity and an aggregate of justice as forces affecting the amplification intensity, which may cause shifts in attitudes. The state of online news framing on the issue at a particular time is actual, while all the other available states are potential, waiting to be triggered into actuality by a force.
| Table 3. Possibility space index | |
|
Index-1, Index-2, and Index-3 are combined to denote state transitions for updating shrinkages and growth. For instance, SJS denotes strong frame identity (S), a sense of justness (J), and a sense of security or being safe (S). SJS represents an actual state.
News sources’ selection and influence occur through signaling news message amplification intensity. Table 4 indicates where news sources change amplification intensity based on interactions and it is an illustration of the gains and losses that may occur over time. Each column shows location of growth in the number of recipients switching from one news source to another, as a result of observed amplification intensity. The shrinkage and growth at a single site are proportional to the number of recipients and the number of senders signaling.
9. Discussion on Influence Dynamics and Migration Path
In this manuscript, models of cultural dynamics are integrated with the cusp catastrophe model to explore double subjectivity through quantifying the amplification intensity. The analysis shows that this measure (i.e., amplification intensity) has potential to change the network structure, as prominent mass count is not the only law of attraction at work. Figure 6 is a representation of the outcome of the model socio-temporal dynamics.
Although the proposed model is capable of scaling to full dataset capacity, a small subset of the network is used for this preliminary evaluation. Given online news sources receive signals that provide a relative baseline—leveraging other news sources’ opinions, interpretations, and perceptions—it is most likely that a news source will choose interactions with similar sources. A chance exists for a news source to interact with another news source based on an increase in its amplification intensity although no connection exists. However, the chance is higher that news sources will interact only with connected sources; thus, breaking out of the cluster is caused by catastrophic shifts in amplification.
| Table 4. Migration possibility space. |
With the amplification intensity function, a variant of the cusp catastrophe model shows possibility space in behavior when making decisions about trust and distrust. Any space on the surface response represents the state of the observed news source. As the news source perceives that the issue will not lead to fair consequences, the cusp triggers them to start attributing blame toward the population causing harm. For instance, the most recent report of Uber previous CEO distracting behavior. The contextualization of this case with Uber shows that a news source with ties to nodes that employ the frame choice of perceived unfairness (unjust) will notice that the sources more aligned with elites are becoming increasingly bullish on the value of the emergent technology issue that promises to deliver improved efficiencies and conveniences. These news sources who initially framed the issue as unjust attract other news sources (i.e., homophily) because their narrative is spreading. When feelings of unfairness intersect with the dominance of the elites, the news sources start scanning for those to whom to attribute blame, thereby entering a space of distrust and strong amplification. This kind of model is associated with hysteresis, making it hard to shift between surface response planes, as the migration path will be different.
10. Result of Research
Uber is a major international company with millions of customers. While the company uses advanced technology to offer its services, its main reliance is on influencing public opinions to improve its acceptance, reputation, and hence maintain a sustainable growth. Uber identified the need to keep a close eye on what is being said about the company in online news and different media. The current technology largely depends on humans—and traditional analytical tools—to follow-up and analyze Uber-related media, which can be expensive and limited in scale.
This manuscript presents the programmable insight approach that allows the new software to manage and analyze very large number of digital data. Thereby, providing immediate insight into different Uber social influence as characterized through opinions formation, network growth or shrinkage, amplification shifts, and news influence on consumer behaviors. This approach has the potential to give Uber a large scale, real-time overview of digital data social influence and causal effects of complex dynamics, such as their sources, growth rate, or effects of frame choice.
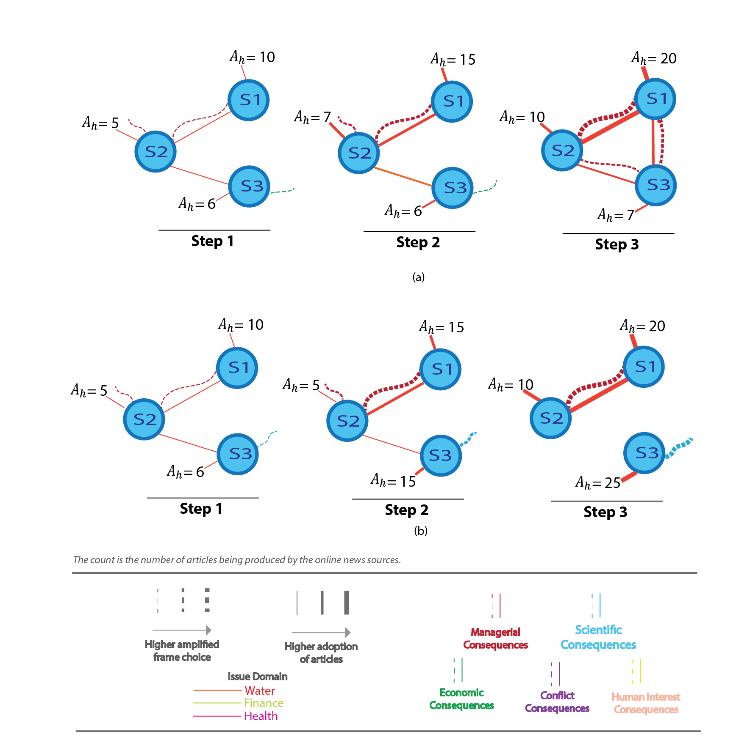
Fig. 7. A visual representation of the model. This is an illustrative scenario of news source interactions where Double Subjectivity has spatial-temporal dynamics and social influence with causal effect. Diagram (a) shows interactions that results in consensus. Whereas, (b) shows the formation of an alternative path that may be expressed as conflict in beliefs or attitudes about Uber. This depiction shows the five standard communications frames used in this research and three domains where vast amounts of narrative unstructured text exist online.
Over time, the programmable insight software will track the progress and trend of online data, providing Uber executives with a true map of ongoing opinions. Uber will be able to enhance positive trends as well as observe negative opinions early on, track their influence, and manage any related problems early on.
Results will be displayed visually using a graph with nodes representing news sources and articles produced, and edge relationships representing the frame type and strength of the associated influence. A human executive will be able to read the graph and observe any new node appearing on it, as well as influence level measures; represented by the number of links going out of the node and their thickness. This node or edge metric will immediately inform executives the emergence of new social influence and opinion sources (the node), as well as their significance (the number and thickness of edges).
While these metrics can be displayed in an excel sheet, it renders itself much easier to the graph theory, and a very large amount of information can be comprehended by a human person much faster.
The performance gain is threefold:
- Spatial: The ability to observe, analyze, and provide “Insight” on a very large number of digital data emanating from many sources in real-time. Traditionally, this would require an army of human analysts using simple tools to work on each document, which could be very time consuming.
- Temporal: The software will be able to continuously observe a large number of online news and other digital data over an extended period of time, and displaying the temporal progress of opinions, showing not only all existing ones, but the history of each news source, and how much it has been influencing others. This will emphasize the dynamics of opinion, and will help focus on significant ones while ignoring others with less or diminishing influence.
- Cost: Running the programmable insight software will cost less than the efforts of human analysts.
11. Conclusion
In this manuscript, a new concept was presented that allows for an adjustment of the absolute baseline of a news source (or agent) that takes into account one’s amplification for expressing double subjectivity through news frames. Further, offered in this research is a) the first known formal news frame issues network in computer science, b) a model for learning the migration paths and patterns about issues, and c) the first known formulation of a amplification intensity function using the cusp catastrophe model for showing the possibility space and gradual shifts in views that are sensitive to news framing amplification. Preliminary experiments suggest that the integration of cultural dynamic models with a cusp catastrophe model is promising for exploring double subjectivity for revealing latent relationships found in online news articles. Future work will involve testing other hypotheses and unfolding the potential function to explore conditions of convergence. Also, future work will give treatment to other hypotheses associated with amplification that leads to trust or distrust, as a result of perceived positive consequences.
Conflict of Interest
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
- L. H. Cheeks, A. Gaffar, Exploring Double Subjectivity Through News Frames in Online News Sources: A Network Approach in IEEE 11th International Conference on Semantic Computing (ICSC), 2017.
- L. Skitka & E. Sargis, The internet as psychological laboratory. Annu Rev Psychol 57: 529–555, 2006.
- R. M. Entman, “Framing: Towards clarification of a fractured paradigm”, Journal of Communication, 43(4), 51-58, 1993.
- R. K.Garrett, B. E. Weeks, R. L. Neo, Driving a Wedge Between Evidence and Beliefs: How Online Ideological News Exposure Promotes Political Misperceptions, Journal of Computer-Mediated Communication, 4 August 2016.
- J. Tankard, The empirical approach to the study of media framing. In S. Reese, O. Gandy, & A. Grant (Eds.), Framing public life (pp. 95–106), 2001, Mahwah, NJ: Erlbaum.
- W. J. Severin, J. W. Tankard, Communication theories: origins, methods, and uses in the mass media, 4th Edition, Longman Publishing Group, New York, 1997.
- S. K. An, K. K. Gower, “How do the news media frame crises? A content analysis of crisis news coverage”, Public Relations Review 35, 107–112, 2009.
- L. H. Cheeks, T. L. Stepien, D. M. Wald, and A. Gaffar, Discovering news frames: An approach for exploring text, content, and concepts in online news sources, International Journal of Multimedia Data Engineering and Management (IJMDEM), 7, pp. 45–62, 2016.
- R Axelrod. The dissemination of culture – A model with local convergence and global polarization. Journal of Confict Resolution, 41(2):203{226, APR 1997. ISSN 0022-0027. doi: f10.1177/0022002797041002001g.
- D. Kempe, J. Kleinberg, S. Oren. and A. Slivkins, Selection and influence in cultural dynamics. Network Science, 4(01), pp.1-27, 2016.
- D. Bindela, J. Kleinberg, & S. Orenb, How bad is forming your own opinion?, Games and Economic Behavior, 92, 248–265, 2015.
- D. Kempe, J. Kleinberg, and ´ E. Tardos, “Maximizing the spread of influence through a social network,” in Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, pp. 137–146, 2003.
- G. Lakoff, Why it Matters How We Frame the Environment, Environmental Communication Vol. 4, No. 1, pp. 7081, March 2010.
- G.F. Bishop, R.W. Oldendick, A.J.Tuchfarber,. Effects of presenting one versus two sides of an issue in survey questions. The Public Opinion Quarterly 46, 69–85, 1982.
- D. A. Scheufele, “Framing as a theory of media effects”, The Journal of Communication, 49(1), 103-122, 1999.
- H. P. Luhn. “The Automatic Creation of Literature Abstracts,” IBM Journal of Research and Development, 2, No. 2, 159, April 1958.
- R. Steinheiser, and C. Clifton, “Data Mining on Text.” 2012 IEEE 36th Annual Computer Software and Applications Conference IEEE Computer Society, p. 630, 1998.
- A. Tan, N. Zhong and L. Zhou, “Text Mining: The state of the art and the challenges.” Proceedings of the PAKDD Workshop on Knowledge Discovery and Data Mining, 65—70, Beijing, China 2000.
- S. Tan, X. Cheng, B. Wang, H. Xu, M. M. Ghanem, Y. Guo, “Using dragpushing to refine centroid text classifiers”, In Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval (SIGIR ’05). ACM, New York, NY, USA, 653-654. 2005.
- M. Tsytsarau & T. Palpanas, Survey on mining subjective data on the web, Data Mining and Knowledge Discovery, 24(3), 478-514, 2012.
- H. Karanikas, C. Tjortjis, and B. Theodoulidis. “An Approach to Text Mining using Information Extraction”, Proc. Workshop Knowledge Management Theory Applications (KMTA 00), 2000.
- Q. Hu, D. Yu, Y. Duan, & W. Bao, A novel weighting formula and feature selection for text classification based on rough set theory, Natural Language Processing and Knowledge Engineering, 2003, Proceedings. 2003 International Conference on. IEEE, 2003.
- B. Liu, Sentiment analysis and opinion mining, Synthesis lectures on human language technologies, 5(1), 1-167, 2012.
- S. Dumais, G.W. Furnas, T.K. Landauer, S. Deerwester, Using latent semantic analysis to improve information retrieval. In Proceedings of CHI’88: Conference on Human Factors in Computing, New York: ACM, 281-285, 1988.
- C. Fellbaum, “A Semantic Network of English: The Mother of all WordNets,” in: Computers and the Humanities 32: 209-220. 1998.
- B. Latane “The psychology of social impact. American psychologist, 36(4):343, 1981.
- Eli Ben-Naim, Paul Krapivsky, and Sidney Redner. Bifurcations and patterns in compromise processes. Physica D, 183, 2003.
- C. Castellano, S. Fortunato, and V. Loreto, Statistical physics of social dynamics. Reviews of Modern Physics, 81:591–646, 2009.
- G. Deffuant, D. Neau, F. Amblard, and G. Weisbuch, Mixing beliefs among interacting agents, Advances in Complex Systems, 3:87–98, 2000.
- R. Hegselmann and U. Krause, Opinion dynamics and bounded confidence: Models, analysis and simulation, Journal of Artificial Societies and Social Simulation, 5(3), 2002.
- Newman, M. E. J., Networks an Introduction. Oxford University Press, 2011.
- UBER, Retrieved from https://uber.com, May 2017.
- G. Petropoulos, Uber and the economic impact of sharing economy platforms, retrieved from http://bruegel.org/2016/02/uber-and-the-economic-impact-of-sharing-economy-platforms/, 2016.
- L. Bradford, What You Need to Know About Getting a Tech Job at Uber. Retrieved from https://www.thebalance.com/what-you-need-to-know-about-getting-a-tech-job-at-uber-4036276, 2016.
- D. Chong & J. Druckman, Framing public opinion in competitive democracies. American Political Science Review, 101(4), 637-655, 2007a.
- D. Chong & J. Druckman, A theory of framing and opinion formation in competitive and elite environments. Journal of Communication, 57, 99-118, 2007b.
- A. Henshall). The Aggressive Processes Uber is using for Global Expansion. Retrieved from http://www.business2community.com/strategy/aggressive-processes-uber-using-global-expansion-01827929#G3L6C8oArOWPii3q.97, 2017.
- K. C. Chen, M. Chiang, H. V. Poor, “From technological networks to social networks,” published in IEEE J. Sel. Areas Commun.., 2013.
- Y. F. Chou, R. G. Cheng, and H. H. Huang, “Performance evaluation of referral selection algorithms in human centric communication networks,”in Proc. 2012 International Symposium on Wireless Personal Multimedia Communications, pp. 638–642, 2012.
- I. Stewart, Does God Play Dice?: The Mathematics of Chaos, Basil Blackwell (Oxford), pp 84–94, 1989.
- R. Thom. Structural Stability and Morphogenesis, 1972. D. H. Fowler (trans.). Reading, MA: W.A. Benjamin.
- T. A. DiPrete and G. M. Eirich, Cumulative Advantage as a Mechanism for Inequality: A Review of Theoretical and Empirical Developments, Annual Review of Sociology, Vol. 32: 271-297, Volume publication date August 2006.
- M. McPherson, L. Smith-Lovin, and J. M. Cook, Birds of a feather: Homophily in social networks, Annual Review of Sociology, 27:415–444, 2001.
- P. Sobkowicz, Discrete model of opinion changes using knowledge and emotions as control variables. PloS one, 7(9), e44489, 2012.
- L. R. Rabinerand B. H. Juang,”An introduction to hidden Markovmodels,” IEEE ASSP Mag., vol. 3, no. l, pp. 4-16, 1986.
- B. K. Jaworski, Media Framing Of U.S. Health Care Reform: A New Era Or Reinforcing Dominant Ideologies Of Health And The Health Care System?, 2012.
- T. F. Homer-Dixon, Environment, Scarcity, and Violence. Princeton University Press, 1999.
- Homer-Dixon, T. F., The upside of down: Catastrophe, creativity, and the renewal of civilization. Washington: Island Press, 2006.