
Dependence-Based Segmentation Approach for Detecting Morpheme Boundaries
Volume 2, Issue 3, Page No 100-110, 2017
Author’s Name: Ahmed Khorsi, Abeer Alsheddia)
View Affiliations
Computer Science Department, Al-Imam Mohammad Ibn Saud Islamic University, Kingdom of Saudi Arabia
a)Author to whom correspondence should be addressed. E-mail: abeer.alsheddi@gmail.com
Adv. Sci. Technol. Eng. Syst. J. 2(3), 100-110 (2017); ![]() DOI: 10.25046/aj020314
DOI: 10.25046/aj020314
Keywords: Classical Arabic language, Computer science, Corpora, Morpheme boundaries, Unsupervised learning, Word segmentation

Export Citations
The unsupervised morphology processing in the emerging mutant languages has the advantage over the human/supervised processing of being more agiler. The main drawback is, however, their accuracy. This article describes an unsupervised morphemes identification approach based on an intuitive and formal definition of event dependence. The input is no more than a plain text of the targeted language. Although the original objective of this work was classical Arabic, the test was conducted on an English set as well. Tests on these two languages show a very acceptable precision and recall. A deeper refinement of the output allowed 89% precision and 78% recall on Arabic.
Received: 04 March 2017, Accepted: 01 April 2017, Published Online: 10 April 2017
1. Introduction
This article is an extension of work originally presented in Proceedings of 4th Saudi International Conference on Information Technology (Big Data Analysis) [1]. The article discusses one of the main challenges in computational linguistics is the identification of morpheme boundaries [2, 3, 4]. Boundary detection process plays a central role in extracting stems from words [5]. Moreover, the noisy infixes affect the performance of some tasks such as similarity compu- tation [6, 7, 8]. The fascinating results of this process performed easily on specific examples made computer learning of language morphology a desirable approached for a long time; as are simple problems hiding dissuasive details. As a result of that, Zelig Harris [9] way of segmenting words into morphemes by only counting letters that may occur after a prefix and marking the picks seems to be the first approach published. Since that, investigations did not cease on building a model easily maintainable to grasp how words are coined in a human language. Benefits of unsupervised approaches step beyond avoiding costly human efforts on known languages. These approaches also have the advantage of being fast enough and to some extent language independent.
In Semitic languages [10, 11] such as Arabic, the
challenge is even harder because of the irregularities, like mutations and diphthongs situations. Mutation means that one letter can be replaced by another to fit the pronunciation. Take the Arabic word “s bRt”.
The proposed approach is developed to the design of a fully computerized (i.e., unsupervised) ex- traction of the morphemes. In light of this goal, the approach uses simple and intuitive statistical feature extracted by reading a corpus of plain text with no tag to become able to identify the morphemes bound- aries. The approach also was compared with an existed approach named Morfessor [13]. Although the original goal of this work was to address the much([AD TajaE]: lie-down)1 comes from applying the pattern “GGńGt” and then mutates the third letter “ã” ([t]: 3rd Arabic letter) to “a” ([T]: 16th Arabic letter). This mutation also can be shown with a long vowel2 deleted or replaced by another. For example, the past tense of the verb “3w9” ([qawl]: say) is “329” ([qaAl]: said) by mutating “p” ([w]: 27th Arabic letter) into “t” ([A]: 1st Arabic letter), whereas the imperative form of the same verb is “39” ([qul]: say) with the letter “p” ([w]: 27th Arabic letter) deleted. The second situation, diphthong; means that two consecutive identical let- ters are merged into one letter. For example, the word “’zu” ([$ad∼]: pull) is originally “2´ z˚ u” ([$ad◦da]).
The richer vocabulary of the classical Arabic, the test was conducted on an English set as well. The results are a proof of concept that unsupervised techniques can accurately handle a morphology as complex as the one of a legacy Semitic language.
The study brings the following values:
- A model: An intuitive but formal model was de- veloped for morphology learning based on a sim- ple interpretation of the probabilistic dependence [14] to segment a word into morphemes.
- Languages
- Classical Arabic: The performance of the model was reported on the morphology of the classical Arabic, which is the language of a huge legacy Arabic morphology is more compli- cated than simple languages [15]. Because of these complex features, some of the methods widely used in many languages cannot be ap- plied to Arabic [6, 11]. On the other hand, two known varieties of Arabic are classical Ara- bic and Modern Standard Arabic (MSA). MSA is based on the classical Arabic. However, MSA is used more in informal speech and can combine words borrowed from other languages that may not use Arabic rules. In contrast, the classical Arabic has been used to write literary legacy and traditional vocabulary. It contains purer Arabic words than MSA. Moreover, Arabic morphologi- cal and semantic rules are derived from the clas- sical Arabic. At the same time, the researchers on Arabic are paying most of their attention to MSA. To the best of our knowledge, the only studies taking into account the classical Arabic are lim- ited to religious texts.
- Other Languages: The performance of the model was tested on a concatenative language namely It has a totally different degree of mor- phological complexity from Arabic [16].
- Comparison: The performance of another word segmentation approach named Morfessor was re- ported on the same
- Corpus: It is a language resource defined as a col- lection of texts stored in a machine-readable for- To assess the proposed approach, we had to build a corpus of classical Arabic texts authored in the period from 431 to 1104 (in Hijri between 130 b.h and 498 h) counting around 122M words in total and 1M distinct words.
The remaining parts of this article are organized as follows: Section 2 reviews existing methodologies on detecting morpheme boundaries. Section 3 introduces the proposed approach and explains its algorithm. Section 4 discusses the tests and the results it carried out. Finally, section 5 concludes with a summary of contributions and makes suggestions for future research work.
2. Applied Methodologies
One of the oldest published work on unsupervised word segmentation is due to Harris who suggested a process to break a phonetic text into morphemes [9] using only successors numbering. Bordag [17] partially relies on Letter Successor Variety (LSV) due to Zelig Harris [9, 2, 3] and combines it with a trie based classifier [18]. The approach is claimed to reach 67.48% F-measure. Bernhard [19] too combined the same principle of successors variation with a set of heuristics to filter out the less plausible segments. The F-measure is claimed to reach 60.81%.
One of the well-known systems in this area is Mor- fessor, developed by Creutz and Lagus [13]. Morfessor tries to capture the morpheme boundaries in a probabilistic model with simplistic features such as the frequency and the length of the morpheme. For comparison, we investigate this approach deeper in Section 4.1.4. Eroglu, Kardes, and Torun [20] tried to make Morfessor 1.0 accommodate the phonetic features of the Turkish language. By adding phone-based features the tried to measure the phonemic confusability between the morphemes. Their results are claimed to be better than Morfessor’s for Turkish, Finnish and English. Pitler and Keshava [5] use the forward and backward conditional probability to build a list of substantial affixes. They report a 52% F-measure on their test set and 75% on the gold-standard.
A number of works depend on Markov Models (MM). Melucci and Orio [21] investigated the use of the Hidden Markov Models (HMMs). The evaluation though is done on a whole information retrieval system (extrinsic) [22]. Naradowsky and Toutanova [23] designed a model, which tries to exploit the alignment of morphemes in a source language to the morphemes in a target (machine translated to) language. With different settings of the model, the approach is claimed to reach 84.6 F-measure for Arabic.
Peng and Schuurmans [24] proposed a two-level hierarchical Expectation Maximization (EM) model. Their test set holds 10K words and their results are claimed to reach 69% F-measure. Poon, Cherry and Toutanova [25] use a log-linear model [26, 27] to capture the features inherent to the morpheme itself and its surrounding letters. The authors tested the approach on supervised and semi-supervised settings as well. The unsupervised settings reached a 78.1% F- measure for Arabic and 70% for Hebrew.
It is worth mentioning that, the actual list of similar works is longer. Thus, we limited the overview to the previous works only. Some of the extra works are in the surveys [28] and [29] that provided for the interested reader. In light of the proposed goal in this ar- ticle, this section intentionally avoids supervised approaches [30].
On the other hand, other works in real environments use the segmentation technique in their approaches, such as document image retrieval systems [31, 32].
3. The Proposed Approach
The word “unbreakable” is coined by concatenating the prefix “un”, the stem “break” and the suffix “able”. The vocabulary, which suggests such segmentation, should contain other words with different combina- tions of prefixes, stems and suffixes (e.g. “rebreak- able”, “unbreaking”…etc), which makes the occurrence of “un” have a weak dependence to the occurrence of “break” whose occurrence is also relatively independent
and P(a ← β) is the conditional probability:
Count(aβ) P(a ← β) = Count(β) (4)
FD(u) = Count(αa) Count(α)P(a) (5)
Count(aβ) BD(u) = Count(β)P(a) (6)
dent of the occurrence of the suffix “able”. On the other hand, each morpheme is supposed to be inseparable from neither its first nor its last letter. The proposed approach (Dependence-Based Segmentation) is where the probability of a letter a: P(a) is estimated by its normalized frequency in the corpus.
Count(a)
all about exploiting these two facts. A good formal modeling of these facts is the definition of the proba-
P(a) = , b∈A (7)
Count(b)
bilistic dependence [14].
3.1 Segmentation Algorithm
Algorithm 1 iterates over the word W letter by letter and computes for every letter wi two dependences: 1. the dependence of the prefix on wi as its last letter, the dependence of the suffix on wi as its first letter where the prefix ends (inclusive) at wi and the suffix starts (inclusive) at it. The difference then points to which of the two (i.e. the prefix or the suffix) is more attached to the current letter wi . The algorithm keeps going until it encounters a change of the direction of the attachment. The change is done when the prefix depends on the preceding letter wi 1 more than the suffix does, and at the same time the suffix depends on the current letter wi more than the prefix does. Then between the previous and the current letters a cutting point (CP) is marked.
3.2 Computation of the Dependence
The concept of dependence we use is symmetric [14]. In this context: “the string depends on the letter” means “the letter depends on the string” and vice versa.
We will call the dependence of a letter a on the pre- fix α: the forward dependence, and we denote FD(u) where u=αa is the prefix tailed by the letter under pro- cessing a. We call the dependence of the letter a on the suffix β: the backward dependence, and we de- note BD(v) where v=aβ is the suffix headed by the let- ter under processing a. We also mark the beginning and the end of a word by respectively # and $. The forward dependence is then:
P(α → a)
Where P is the alphabet. Count(α) expresses how often an n-gram α occurs in the corpus. After segmenting a word using the cutting points, we supposed that a morpheme with the least frequency among the other morphemes is a stem and the other morphemes are affixes. By the definition of the dependence measure [14], when both forward and backward dependencies at the same letter are lower than one, this means that the letter does not depend on the prefix or the suffix. Thus, we assigned zero to the difference’s value and dis- carded this position from the segmentation process. This dependence is called a negative dependence [14]. Arabic example: The Arabic word “ 2 2tzrt” ([Al kitaAbaAk]: the two books) contains two cutting points as shown in Table 1. The first one occurs when the second letter “3” is more dependence on the pre- fix ”3t#” than the suffix ”$ 2 2tzr, while the third let- ter “T” is more dependent on the suffix ”$ 2 2t2” than the prefix ”2rt#”. The second position is the sixth letter “t#” when the dependence tendency is changed. Thus, these two cutting points “ t #2t2 3t” produce the following morphemes: “3t”, “#2t2” and “ t”. Consequently, the morpheme “#2t2” is the stem depending on the frequency list in Table 3.English example: Table 4 is a simulation of the al- gorithm on the word “unbreakable”. The difference at each letter (FD(u)-BD(v)) points a dependence direc-Negative dependence example: The Arabic word “ņyt2” ([kutayb]: small book) does not contain any cutting point as the table 2 shows it. Consequently, the morpheme “ņyt2” is the stem of the word. At the same time, we can note the second letter “ã” ([t]: 3ed Arabic letter) has zero as its difference value. That means both forward and backward dependencies are less than one.

Where a is the alphabet. Count(α) expresses how of- ten an n-gram α occurs in the corpus.
After segmenting a word using the cutting points, we supposed that a morpheme with the least frequency among the other morphemes is a stem and the other morphemes are affixes.By the definition of the dependence measure [14], when both forward and backward dependencies at the same letter are lower than one, this means that the let- ter does not depend on the prefix or the suffix. Thus, we assigned zero to the difference’s value and dis- carded this position from the segmentation process. This dependence is called a negative dependence [14]. Negative dependence example: The Arabic word “ņyt2” ([kutayb]: small book) does not contain any cutting point as the table 2 shows it. Consequently, the morpheme “ņyt2” is the stem of the word. At the same time, we can note the second letter “ã” ([t]: 3ed Arabic letter) has zero as its difference value. That means both forward and backward dependencies are less than one.Arabic example: The Arabic word “ 2 2tzrt” ([Al kitaAbaAk]: the two books) contains two cutting points as shown in Table 1. The first one occurs when the second letter “3” is more dependence on the pre- fix ”3t#” than the suffix ”$ 2 2tzr, while the third letter “T” is more dependent on the suffix ”$ 2 2t2” than the prefix ”2rt#”. The second position is the sixth letter “#” when the dependence tendency is changed. Thus, these two cutting points “ t #2t2 3t” produce the following morphemes: “3t”, “#2t2” and “ t”. Consequently, the morpheme “#2t2” is the stem depending on the frequency list in Table 3.

Table 1: Arabic example of the segmentation
| i | u | FD(u) | v | BD(v) | Difference | Direction | ||
| 1
2 |
t#
3t# |
0.991
9.349 |
$ 2 2tzrt
$ 2 2tzr |
7.174
9.153 |
-6.182
0.195 |
↓
↑ |
3 2rt# 1.017 $ 2 2t2 17.174
4 ńzrt# 0.716 $ 2 2z 1.210
5 2tzrt# 2.532 $ 2 t 0.544
6 2tzrt# 12.067 $ 2 1.552
7 2 2tzrt# 1.366 $ t 1.865
8 2 2tzrt# 4.560 $ 1.792
-16.157 ↓
-0.494 ↓
1.987 ↑
10.514 ↑
-0.498 ↓
2.767 ↑
Table 3: A frequency list of chosen words
| Morpheme | Frequency | Morpheme | Frequency |
| un | 1,986 | 3t | 72,845 |
| break | 46 | #2t2 | 47 |
| able | 1,426 | t | 10,047 |
Table 4: English example of the segmentation
| i | u | FD(u) | v | BD(v) | Difference | Direction |
| 1
2 |
#u
#un |
0. 46
6. 36 |
unbreakable$
nbreakable$ |
30.97
5. 84 |
-30. 51
0. 52 |
↓
↑ |
| 3 | #unb | 1. 35 | breakable$ | 46. 70 | -45. 35 | ↓ |
| 4
5 6 7 |
#unbr
#unbre #unbrea #unbreak |
1. 94
3. 11 6. 79 34. 71 |
reakable$
eakable$ akable$ kable$ |
10. 45
5. 01 1. 68 1. 50 |
-8. 51
-1. 90 5. 11 33. 21 |
↓
↓ ↑ ↑ |
- #unbreaka 09 able$ 7. 38
- #unbreakab 70 ble$ 9. 89
- #unbreakabl 72 le$ 2. 76
- #unbreakable 02 e$ 1. 15
- 81 ↑
- 96 ↑
- 87 ↑
“k” and the eighth letter “a”. Therefore, the result- ing morphemes will be: “un”, “break” and “able”. The least frequent morpheme is “break” by using Table 3.
Consequently, the morpheme “break” is the stem.
4. Tests and Results
Before describing the test settings, we will list main steps, that we followed in the study:
- Build the (see Section 4.1.1).
- Make the normalization (see Section 1.2).
- Generate the language model (see Section 1.3).
- Test the proposed approach (see Section 1.4) us- ing materials (see Section4.1.5).
- Evaluate the performance by using the metrics (see Section 1.6).
4.1 Test Settings
- Test Dataset
Arabic The purpose of the research, which drew our efforts to design this approach, was to address chal- lenges in processing the morphology of the classical Arabic. Works we are aware of try to handle MSA. Actually, MSA is known to include a mixture of words borrowed from other languages and words just coined for the convenience, which usually breaks the classi- cal Arabic rules. Correctly handling the classical Ara- bic brings three interrelated values: 1. The classical Arabic vocabulary is much richer in terms of pure Arabic words. 2. The Arabic rules in the morpho- logical, grammatical and semantic levels amply docu- mented since the eighth century have been designed on the basis of the classical Arabic. 3. A huge legacy literature is written in the classical Arabic, and most of the time standing beyond the scope of the super- vised approaches designed for the MSA. The present corpus3 gathers Arabic texts dating back from 431 to 1104 (130 b.h and 498 h). It contains around 122M words in total and 1M distinct words with an aver- age size of 6.22 letters per word. Table A.1 in the ap- pendix shows a sample of the index in Arabic that was published with our corpus. Such dataset is by itself a valuable resource for researches in NLP field.
English We obtained the English text by merging the two corpora ”wiki” and ”news”4. This resulted in more than 1M unique words and more than 8M words in total, having an average size of 8.00 letters per word.
- Normalization
The normalization process is frequently used to trans- form text into an approved form, which aids in reduc- ing the noise and sparsity in the text. In present work, the following normalization was applied to the Arabic words:
- The removal of
- The substitution of all variants of Hamza “ ” ([´]) with the form “ ” ([´]).
- The substitution of the letter “ĩ” ([ ]) with “t ” ([´A]).
- Language Model
The proposed language model extracts all possible q– grams from a word of n length, where q rises from one to n. Then it assigns each gram to its occurrence in the corpus. Algorithm 2 explains the extraction. Ta- ble A.2 in the appendix shows the n-grams of the two example words “ 2 2tzrt” and “unbreakable”.
Test Process
Morfessor 2.05 and the proposed approach (Dependence-Based Segmentation) are run over the same corpus, then three samples of 100 words each are randomly picked out of the whole segmented cor- pus. The results of these approaches are evaluated manually. Precision, recall and F-measure of the cut- ting points are then recorded. This is repeated on each of the four settings combinations where each setting combines one of two occurrence settings with one of two affix settings.
Occurrence Settings
- Distinct: To build the language model, the ap- proach used distinct words, i.e. each word in the corpus occurs one
- Plain: The number of occurrences is taken into ac- count during building the model, e. a word may occur more than once.
Affix Settings
- Raw: Results sample is picked randomly with no
- Non-empty affix: Samples are picked randomly only among words for which the proposed ap- proach has carried out at least one cutting For a number of words, the segmentation simply did not identify any cutting point. Most of them were because of the scarcity of the stem or stem.affix remaining combination. We then tried to assess the impact of such cases on the performance and how accurate the identified cutting was.
It is worth noting that our objective was to address the challenge of segmenting the classical Arabic words. To the best of our knowledge, there is no suitable gold standard for TA. We had to build ourselves the set of words. Then we proceeded to the manual segmenta- tion of three different randomly picked samples for each setting.
- Test Platform
We used the following materials to test the proposed algorithm:
- Operating system: Ubuntu 04, 64-bit.
- Programming language: C++.
- Compiler: GCC 9.0.
- Database management system: MySQL Server 5.43.
- C++ external Library: libmysqlcppconn-dev 1.1.0- 3build1 to connect C++ with MySQL
- CPU: Intel(R) Xeon(R) CPU E5530 @ 2.40GHz * 16.
- RAM: 6 GB for RAM and 12 GB for
- Performance Metrics
For evaluating, we used three metrics: recall, preci- sion and F-measure [33], where we took into account a number of cutting points during the evaluation.
- Recall: This metric measures how many correct po- sitions are found among all the existing correct po- The higher the recall, the more correct po- sitions are found and returned.
correct cutting points in the result
Recall = all correct cutting points in the sample
- Precision: Precision measures how many positions are actually correct among all the positions that the algorithm The high precision indicates that the algorithm found significantly the correct posi- tions more than incorrect positions.
correct cutting points in the result
Precision = all found cutting points in the result
- F-measure: A weighted average of the recall and the precision is
Recall + PrecisionF measure = 2 Recall ∗ Precision
4.2 Result
- Arabic Results
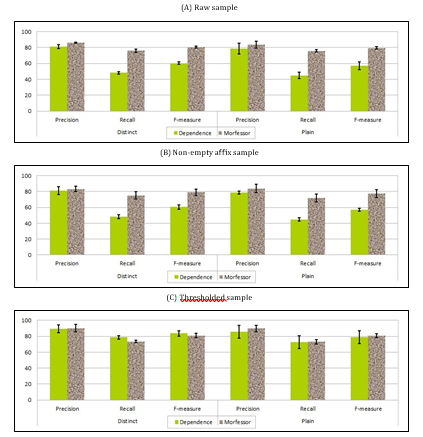
Compared to the English, the results of the proposed approach (Dependence-Based Segmenta- tion)are clearly lower on Table 5. The two obvious causes might be the irregularities in Arabic morphol- ogy and the typos in the test set. The latter is con- firmed by results obtained when the sample is re- stricted to the words with a relatively high frequency (thresholded) as shown in Figure 1. Thresholded de- notes an additional filter applied to non-empty affix sample, where a segmentation is picked only if the af- fix reappears in more than 1K other segmentations. It
is worth noting that we omitted this filter in the En- glish tests because we observed a rise in values of the standard deviation between the three samples. It has fluctuated around 0 to 29 words. Reasons for this de- viation need to be investigated more closely in a sep- arate work, and we paid our attention in this work to Arabic results.
Another reason affects the performance which is the lack of a dataset. The proposed approach works totally with the unsupervised method and depends only on the count of words in the corpus. How- ever, it is difficult to include all possible derivatives in the corpus. For example, the derivative “ã2922 t” ([Al <ij HaAfaAt]: the prejudices) appears one time in the dataset; that is, there is no other derivative that appears in the dataset without the prefix ”3t”, for in- stance. Indeed, the word ”ã2922 !” would be more dependent on the prefix ”3t” and the proposed ap- proach does not learn that the prefix ”3t” can be cut off from the word ”ã2922 t” as shown at the top of Table 6. This problem will be removed if we add the word ”ã2922 !” into the dataset. The approach then finds the segmentation position ”ã2922 ! 3t” as it ap- pears at the bottom of Table 6.
The segmentation seems to be the best when the word counts are omitted (distinct). This seems to be due to the diversity of affixed in the classical Arabic. Indeed some stems/affixes may not appear more than once in the whole corpus (e.g. “ ź 2” ([kajux f])as a deep sleep).
Running the proposed approach over the whole corpus resulted in around 1,805,231 morphemes and 596,358 distinct morphemes with an average size ofSurprisingly, Morfessor was unable to detect any boundary. The expected reason is that Morfessor may not be able to deal effectively with non-Latin letters, such as Arabic letters. We then evaluated Morfessor using Buckwalter Arabic transliteration [12]. Despite the simplicity of the proposed approach, the results of Morfessor is close to the results of the proposed ap- proach especially after applying the filter.
5.94 letters per morpheme.
- English Results
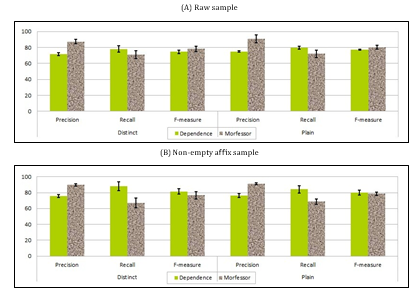
With no restriction on the results sample, Morfessor outperforms the proposed approach (Dependence- Based Segmentation) in terms of precision where the latter has a better recall as shown in Table 7 . This matches well the results given in [34]. The low re- call of Morfessor explains the worsening of its per- formance with affixed words while the proposed ap- proach improves. The F-measure shows that the over- all performance of the proposed approach is better as shown in Figure 2.
When the counts of the words are involved in the computation of the dependence, Morfessor improves. The dependence-base’s precision increases too, where its recall worsens.
Table 5: Arabic results
Raw
Distinct Plain
Dependence Morfessor Dependence Morfessor
Precision 81.21±2.76 86.0215±0.61 78.66±6.73 83.6547±4.32
Recall 48.11±1.32 76.0147±1.94 44.88±3.98 75.9473±1.74
F-measure 60.62±1.47 80.7091±1.08 57.14±4.96 79.6149±1.67
Table 6: Example of the lack of a dataset
|
3t#
$ã2922 ↓
3 t# 2.637 $ã2922 ! 26.555 -23.917 ↓
4 t# 2.096 $ã2922 5.499 -3.402 ↓
5 , t# 1.019 $ã292c 3.443 -2.423 ↓
6 22 t# 4.484 $ã29t 1.404 3.079 ↑
7 e22 t# 11.911 $ã29 1.296 10.614 ↑
8 2922 t# 3.587 $ãt 2.422 1.164 ↑
9 ã2922 t# 17.184 $ã 0.885 16.298 ↑
i u FD(u) v BD(v) Difference Direction 1 t# 0.991 $ã2922 t 7.174 -6.182 ↓
2 3t# 9.349 $ã2922 6.102 3.246 ↑
3 t# 2.637 $ã2922 ! 26.555 -23.917 ↓
4 t# 2.096 $ã2922 10.081 -7.984 ↓
5 , t# 1.019 $ã292c 3.374 -2.714 ↓
6 22 t# 4.484 $ã29t 1.411 3.072 ↑
7 e22 t# 11.911 $ã29 1.298 10.612 ↑
8 2922 t# 3.587 $ãt 2.422 1.164 ↑
9 ã2922 t# 17.184 $ã 0.885 16.298 ↑
Table 7: English results
Dependence Morfessor Dependence MorfessorDistinct Plain
|
Raw |
Precision
Recall F-measure |
71.60±1.68
78.11±3.98 74.71±2.17 |
87.36±2.64
70.90±4.84 78.27±3.57 |
74.99±1.14
79.66±1.88 77.25±0.73 |
90.72±4.83
71.98±4.73 80.27±2.52 |
| Non-empty affix | Precision
Recall F-measure |
75.82±1.98
88.10±5.73 81.50±3.43 |
89.73±1.74
67.11±6.12 76.79±4.64 |
76.26±2.34
84.19±4.61 80.03±2.81 |
91.37±1.24
68.77±3.40 78.47±1.88 |
5 Conclusion and fluture Work
We investigated the use of an intuitive yet formal def- inition of event dependence in the detection of mor- pheme boundaries. The initial target of our work was the classical Arabic, which is a Semitic language rec- ognized to have a complex morphology and a vocab- ulary richer in pure Arabic words than the Modern Standard Arabic (MSA). The test also was conducted on an English set as well. Results on the classical Arabic and on English have been compared to the re- sults of another unsupervised complicated segmen- tation approach so-called Morfessor that initially designed for European languages. As simple and ele- gant as is the proposed approach (Dependence-Based Segmentation) , it seems to be more committed to the recall where the latter’s precision is better on English words. This has been confirmed when the evaluation focused on affixed words. On Arabic, Morfessor could not identify boundary. The results are a proof of con- cept that unsupervised techniques can decently han- dle a morphology as complex as the one of a legacy Semitic language like Arabic.
In addition, required for the evaluation, we care- fully built a pure classical Arabic dataset. Where such linguistic resource is abundant in languages like, we are not aware of any other classical Arabic dataset.
One of the things made possible by morpheme boundaries identification is the automated word generation. The segmentation of a small set of well- chosen words will result in a set of diverse mor- phemes. The generation of new words is then a proper concatenation of the resulting morphemes. The chal- lenge is then two folds: to build a suitable word-set of a decent size, which allows an accurate segmenta- tion and a wide coverage of the different morphemes, then to find the appropriate concatenation strategy to minimize the number of irrelevant words.
- A. Khorsi and A. Alsheddi, “Unsupervised detection of morpheme boundaries,” in 2016 4th Saudi International Conference on Information Technology (Big Data Analysis) (KACSTIT), Nov 2016, 1–7.
- Z. Harris, Morpheme Boundaries Within Words: Report on a Computer Test, ser. Pennsylvania. University. Dept. of Linguistics. Transformations and discourse analysis papers. University of Pennsylvania, 1967.
- M. A. Hafer and S. F. Weiss, “Word segmentationby letter successor varieties,” Information Storage and Retrieval, vol. 10, no. 11–12, pp. 371 – 385, 1974.
- J. R. Saffran, E. L. Newport, and R. N. Aslin,“Word segmentation: The role of distributionalcues,” Journal of Memory and Language, vol. 35,no. 4, pp. 606 – 621, 1996.
- S. Keshava and E. Pitler, “A segmentation approach to morpheme analysis,” in Working Notes for the CLEF Workshop 2007, Hungary, 2007, pp. 1–4.
- S. H. Mustafa, “Character contiguity in n-grambased word matching: The case for Arabic textsearching,” Information Processing & Management, vol. 41, no. 4, pp. 819–827, Jul. 2005.
- S. H. Mustafa, “Word-oriented approximatestring matching using occurrence heuristic tables: A heuristic for searching Arabic text,” Journal of the American Society for Information Science and Technology, vol. 56, no. 14, pp. 1504–1511, Dec. 2005.
- A. Khorsi, “On morphological relatedness,” Natural Language Engineering, vol. 19, no. 4, pp. 537–555, Oct. 2013.
- Z. S. Harris, “From phoneme to morpheme,”Language, vol. 31, no. 2, pp. 190–222, Jun. 1955.
- G. A. Kiraz, Computational Nonlinear Morphology with Emphasis on Semitic Languages. Cambridge, England: Cambridge University Press, 2001.
- S. Wintner, “Morphological processing of semiticlanguages,” in Natural Language Processing of Semitic Languages, ser. Theory and Applications of Natural Language Processing, I. Zitouni, Ed. Springer Berlin Heidelberg, 2014, pp. 43–66.
- N. Habash, A. Soudi, and T. Buckwalter, “OnArabic transliteration,” in Arabic Computational Morphology, ser. Text, Speech and Language Technology, A. Soudi, A. v. d. Bosch, and G. Neumann, Eds. Springer Netherlands, 2007, no. 38, pp. 15–22.
- M. Creutz and K. Lagus, “Unsupervised models for morpheme segmentation and morphology learning,” ACM Transactions on Speech and Language Processing, vol. 4, no. 1, pp. 1–34, Jan. 2007.
- R. Falk and M. Bar-Hillel, “Probabilistic dependence between events,” The Two-Year College Mathematics Journal, vol. 14, no. 3, pp. 240–247, Jun. 1983.
- D. Jurafsky and J. H. Martin, Speech and language processing: an introduction to natural language processing, computational linguistics, and speech recognition. Prentice Hall, 2009.
- I. Al-Sughaiyer and I. Al-Kharashi, “Arabic morphological analysis techniques: A comprehensive survey,” Journal of the American Society for Information Science and Technology, vol. 55, no. 3, pp. 189–213, Feb. 2004.
- S. Bordag, “Unsupervised and knowledge-freemorpheme segmentation and analysis,” in Advances in Multilingual and Multimodal Information Retrieval. Springer, 2008, pp. 881–891.
- D. Morrison, “Patricia—practical algorithm to retrieve information coded in alphanumeric,” JACM: Journal of the ACM, vol. 15, no. 4,pp. 514–534, Oct. 1968.
- D. Bernhard, “Simple morpheme labelling inunsupervised morpheme analysis,” in Advances in Multilingual and Multimodal Information Retrieval. Springer, 2008, pp. 873–880.
- O. Eroglu, H. Kardes, and M. Torun, “Unsupervised segmentation of words into morphemes,”2009.
- M. Melucci and N. Orio, “A novel method forstemmer generation based on hidden markovmodels,” in Proceedings of the twelfth international conference on Information and knowledge management. ACM, 2003, pp. 131–138.
- A. Clark, C. Fox, and S. Lappin, The Handbook of Computational Linguistics and Natural Language Processing. John Wiley & Sons, 2013.
- J. Naradowsky and K. Toutanova, “Unsupervisedbilingual morpheme segmentation and alignment with context-rich hidden semi-Markovmodels,” in Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics, 2011,pp. 895–904.
- F. Peng and D. Schuurmans, “A hierarchical EMapproach to word segmentation,” in In 6th Natural Language Processing Pacific Rim Symposium (NLPRS2001) Shai Fine, Yoram Singer, and Naftali Tishby.1998, 2001, pp. 475–480.
- H. Poon, C. Cherry, and K. Toutanova, “Unsupervised morphological segmentation with loglinear models,” in Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2009, pp. 209–217.
- R. Christensen, Log-Linear Models and Logistic Regression, ser. Statistics. Springer Verlag, 1997.
- S. Haberman, The Analysis of Frequency Data.Chicago: The University of Chicago Press, 1974.
- B. Can and S. Manandhar, “Methods and algorithms for unsupervised learning of morphology,” in Computational Linguistics and Intelligent Text Processing. Springer, 2014, pp. 177–205.
- H. Hammarstrom and L. Borin, “Unsupervised ¨learning of morphology,” Comput. Linguist.,vol. 37, no. 2, pp. 309–350, Jun. 2011.
- J. Goldsmith, “Unsupervised learning of themorphology of a natural language,” Comput. Linguist., vol. 27, no. 2, pp. 153–198, Jun. 2001.
- R. Tavoli, E. Kozegar, M. Shojafar, H. Soleimani,and Z. Pooranian, “Weighted pca for improvingdocument image retrieval system based on keyword spotting accuracy,” in 2013 36th International Conference on Telecommunications and Signal Processing (TSP), July 2013, pp. 773–777.
- M. Keyvanpour, R. Tavoli, and S. Mozaffari,“Document image retrieval based on keywordspotting using relevance feedback,” International Journal of Engineering-Transactions A: Basics, vol. 27, no. 1, p. 7, 2014.
- C. D. Manning, P. Raghavan, and H. Schutze, ¨ Introduction to information retrieval. CambridgeUniversity Press, 2008.
- M. Creutz and K. Lagus, “Unsupervised models for morpheme segmentation and morphology learning,” ACM Transactions on Speech and Language Processing (TSLP), vol. 4, no. 1, 2007.
Citations by Dimensions
Citations by PlumX
Google Scholar
Scopus
Crossref Citations
No. of Downloads Per Month
No. of Downloads Per Country