
Performance Evaluation of Associative Classifiers in Perspective of Discretization Methods
Volume 2, Issue 3, Page No 845-854, 2017
Author’s Name: Zulfiqar Ali1,2, a), Waseem Shahzad1
View Affiliations
1Department of Computer Science, National University of Computer & Emerging Science, Islamabad, ZIP Code #44000, Pakistan
2Department of Computer Science and IT, The University of Lahore, Lahore, ZIP Code#54000, Pakistan
a)Author to whom correspondence should be addressed. E-mail: zulfiqar.ali@nu.edu.pk
Adv. Sci. Technol. Eng. Syst. J. 2(3), 845-854 (2017); ![]() DOI: 10.25046/aj0203105
DOI: 10.25046/aj0203105
Keywords: Associative Classification, Discretization Methods, KEEL, Data Mining

Export Citations
Discretization is the process of converting numerical values into categorical values. Contemporary literature study reveals that there are many techniques available for numerical data discretization. The performance of classification method is dependent on the exploitation of the data discretizing method. In this article, we investigate the effect of discretization methods on the performance of associative classifiers. Most of the classification approaches work on the discretized databases. There are various approaches exploited for the discretization of the database to compare the performance of the classifiers. The selection of the discretization method greatly influences the classification performance of the classification method. We compare the performance of associative classifiers namely CBA and CBA2 on the selective discretizing methods i.e. 1R Discretizer (1R-D), Ameva Discretizer (Ameva-D), Bayesian Discretizer (Bayesian-D), Discretization algorithm based on Class-Attribute Contingency Coefficient (CACC-D), Class-Attribute Dependent Discretizer (CADD-D), Distribution-Index-Based Discretizer (DIBD-D), Cluster Analysis (ClusterAnalysis-D), Chi-Merge Discretizer (ChiMerge-D) and Chi2 Discretizer (Chi2-D) in terms of accuracy. The main object of this study is to investigate the impact of discretizing method on the performance of the Associative Classifier by keeping constant other experimental parameters. Our experimental results show that the performance of the Associative Classifier significantly varies with the change of data discretization method. So the accuracy rate of the classifier is highly dependent on the selection of the discretization method. For this comparative performance study, we use the implementation of these methods in KEEL data mining tool on public datasets.
Received: 22 April 2017, Accepted: 16 May 2017, Published Online: 19 June 2017
1. Introduction
Discretization methods have played a great role in data mining and knowledge discovery. The discretization process makes learning more accurate and faster. There are various emerging classification problems in various domains of knowledge like image processing, medical science, business analytics and data mining etc. data, images, audio, video and textual data. The rapid growth in the data reservoirs in the fields of business, basket analysis, Engineering sciences, social networks, stock exchange and geological data is very high due to the cheaper storage resources. The high growth rate and huge data volume create a challenging problem i.e. knowledge discovery from the huge databases in the field of Data Mining. For the appropriate, effective and comprehensive knowledge discovery for the managers and decision makers; researchers are proposing continuously more efficient knowledge mining approaches.
The field of artificial neural networks, expert systems, medical science, bioinformatics, machine learning is example areas where extensively classification approaches have been studied. There are various approaches exploited for the building of associative classifiers. This comparative study provides the extension of the work presented in [1]. We provide the performance analysis of Associative Classifiers (CBA and CBA2) with the variation of the data discretizing method.
In this article, we investigate the effect of discretizing methods on the performance of Associative Classifiers CBA and CBA2. We use the selective data discretizing methods i.e. 1R Discretizer (1R-D) [9], Ameva Discretizer (Ameva-D) [10], Bayesian Discretize r(Bayesian-D) [11], Discretization algorithm based on Class-Attribute Contingency Coefficient (CACC-D) [12], Class-Attribute Dependent Discretizer (CADD-D) [13], Distribution-Index-Based Discretizer (DIBD-D) [14], Cluster Analysis (ClusterAnalysis-D) [15], Chi-Merge Discretizer (ChiMerge-D) [16] and Chi2 Discretizer (Chi2-D) [17] for continuous data discretization purpose by exploiting the implementation of these methods in KEEL [18], a data mining tool by using the public datasets.Our experimental results reveal that the performance of the Associative Classifier significantly varies with the change of data discretization method in terms of accuracy. So the accuracy rate of the classifier is highly dependent on the selection of the data discretizing method. Our comparative study reveals that the performance of CBA (Associative Classifier) is better on the Ameva Discretizer than the other discretizing methods in terms of accuracy. The main object of this study is to investigate the impact of discretizing method on the performance of the Associative Classifier at the same other experimental parameters.Thabtahand Fadi Abdeljaber provided the review of associative classification in [2]. Ranjana Vyas et al. describe the application of Associative Classifiers for Predictive analytics in [3]. The exploitation of associative classifiers for predictive analysis in the field of health care is surveyed in [4] by Sunita Soni and O.P.Vyas. Huan Liu et al. provide the extensive survey of the discretization techniques in[5]. The focus of this article was an exploration of discretization methods with prospective of their historic development, the trade-off between speed and accuracy. Authors provided the hierarchical framework to categorize the exiting discretizing methods. Sotiris Kotsiantis and Dimitris Kanellopoulos surveyed the discretization techniques applied for the data discretization in [6].The theoretical and empirical perspective of the discretizing methods is very in [7] by the Salvador Garcıa. In [8] Pancho et al. provided the analysis of fuzzy association rules with Fingrams in KEEL.
The Section 2 of the paper discusses the associative classification and describes the selective associative classification methods that are the focus of our study for the comparative analysis. Section 3 describes the data discretization process and selective methods for the data discretization i.e. 1R-D, Ameva-D, Bayesian-D, CACC-D, CADD-D, DIBD-D, ClusterAnalysis-D, ChiMerge-D, and Chi2-D. Section 4 explains the experimental Set-up exploited for this study, data sets and KEEL tool used for the experimentation. Section 5 describes the comparative performance results achieved by various discretizing methods used for datasets discretization by using Associative Classifiers CBA and CBA2. In section 6 more results discussion is provided and finally, the last Section concludes the study.
2. Associative Classification
The Associative Classification (AC) is a classification approach which integrates the classification rules mining and association rules mining that are two important data mining tasks. The Association Rule Mining (ARM) is unsupervised learning method in which no class attribute involved during the discovery of rules. The aim of the association rule mining is to discover associations between items in a transaction database. The attributes in the consequent of a rule could be more than one in association rule mining. The associative classification is a supervised leaning where a class must be given for the discovery of classification rules. For the construction of a classifier that can forecast the classes of test data objects is the main objective of associative classification. The consequent of a rule is an only class attribute. The over fitting is a considerable issue in the associative classification rule discovery. The over view of the selective Associative Classification approach CBA which is exploited to investigate the impact of discretizing method on the performance of the classification approach is given in the following sections.
2.1. CBA
Bing Liu, Wynne Hsu and Yiming Ma proposed a new hybrid classification approach by integrating the concept of association rule mining and classification rule mining in [19] that is named Classification Based on Associations (CBA). In this associative classification approach, the integration is done by focusing on the discovery of a special subset of association rules that are known as class association rules (CARs).
All class association rules are discovered those satisfy the minimum support and minimum confidence by using an existing association rule mining algorithms[20].The CBA associative classifier consists of two parts 1) a rule generator (CBA-RG) and 2) a classifier builder (CBA-CB).This approach possesses various advantages like the discretization of continuous attributes based on the classification pre-determined class target. The Data Mining task in CBA consists of the three steps;1) discretization of continuous attributes if any;2) class association rules;3) classifier building based on the generated class association rules.
2.2. CBA2
Bing Liu, Yiming Ma and Ching-Kian Wong proposed the enhancement and improvements in an associative classifier CBA. The new improved associative classification approach is named CBA2 developed in [21]. In this paper, theauthor tried to coup up with weaknesses of an exhaustive search based classification system CBA. The authors proposed two new techniques to deal with the observed weaknesses of the classification approaches. The first weakness observed is that as the traditional association rule mining exploits only a single minsup in rule generation which results inadequate for unbalanced class distribution. Secondly, classification data often contains a huge number of rules, which may cause a combinatorial explosion. For various databases, the rule generator is unable to generate rules with many conditions while such rules may be important for accurate classification. The first problem with this approach is tackled by using multiple class minsups in rule generation instead of single minsup as in CBA. The second problem which is caused by the exponential growth of the number of rules is dealt indirectly. The decision tree method [22] is exploited. The main working concept of the CBA2 is to use the rules of CBA2 to segment the training data and then select the classifier. These improvements in CBA improved the accuracy and lower error rate of the classification.
3. Data Discretization
Discretization is a data preprocessing technique used in many knowledge discoveries, machine learning and data mining tasks. Discretization process converts the continuous data into discrete form as most of the knowledge discovery and data mining algorithms work on discrete data. The discretization technique transforms a set of continuous attributes into discrete ones. By associating categorical values to intervals discretizing approach transforms quantitative data into qualitative data. The data discretiztion techniques are exploited to enhance the performance of the many knowledge discoveries and data mining approaches. We have used selective discretization method for our study to investigate the performance of Associative Classifier CBA by using public data sets. The discretization methods used in this study are described in the following.
3.1. Discretization Methods
Gonzalez-Abrilet al. proposed a new discretization method named Ameva Discretizer (Ameva-D) in [10] that is proposed for supervised learning algorithms. The Ameva discretization approach maximizes a contingency coefficient based on Chi-square statistics. It helps in generating a potentially minimal number of discrete intervals. The most distinguishing feature of Ameva with respect to other discretizing approaches is that it does not need the user to indicate the number of intervals.
Xidong Wu proposed a new discretizing algorithm namely Bayesian Discretizer (Bayesian-D) in [11]. The Bayesian-D discretization approach exploits the Bayes formula. Cheng-Jung Tsai et al. propose a discretization algorithm based on Class-Attribute Contingency Coefficient named (CACC-D) in [12]. The CACC-D discretizing approach is motivated by the contingency coefficient. The CACC algorithm is a static, global and incremental discretizing approach. The CACC-D is supervised and top-down discretization algorithm which is based on Class-Attribute Contingency Coefficient. J.Y. Ching et.al proposed anew method for continuous data discretization named Class-Attribute Dependent Discretizer (CADD-D) in [13]. The class-dependant discretizing is performed in this approach for inductive learning from continuous and mix-mode data. The CADD-D is a discretizing method optimized for supervised learning based on information theoretic discretization method. The interdependence redundancy between the discrete intervals and the class labels is measured in the CADD-D method tom maximize the mutual dependence.
L.A. Kurgan et.al proposed a discretization method namely known as Class-Attribute Interdependence Maximization (CAIM-D) in [23]. The CAIM-D method is proposed for the supervised data classification. The main objective of this proposed approach is to increase the class-attribute interdependence to maximum level and to produce a minimal number of discrete intervals. The classification results in terms of accuracy are more promising with CAIM discretization method with respect to other discretization approaches. Huan Liu and Rudy Setiono proposed a method for converting numeric data discrete named Chi2 Discretizer (Chi2-D) in [17]. This approach (Chi2-D) takes data sets with numeric attributes as an input. This approach can intelligently and automatically discretize the numeric attributes as well as remove irrelevant ones as output. The Chi2 algorithm applies the X 2 statistic which conducts a significance test on the relationship between the values of an attribute and the categories.
In [16] Randy Kerber proposed a method for the discretization known as Chi-Merge Discretizer (ChiMerge-D) which is a general, robust algorithm that uses the X 2 statistic to discretize numeric attributes. The ChiMerge approach provides a useful and reliable summarization of numeric attributes. The number of intervals needed is determined according to the characteristics of the data. Michal R. Chmielewski and Jerzy W. Grzymala-Busse proposed discretizing method based on Cluster Analysis named ClusterAnalysis-D in [15]. The hierarchical cluster analysis is used for discretizing attributes in ClusterAnalyusis-D.
The ClusterAnaysis-D can be classified as either locally discretizing method or globally discretizing method. The methods that are characterized by operating only one attribute are called local method while the methods considering all attributes are called global methods. QingXiang Wu et.al proposed a new discretizing approach named Distribution-Index-Based
Discretizer(DIBD-D ) in [14]. The DIBD-D approach is based on the definition of dichotomic entropy and a compound distribution index. This criterion is applied to discretize continuous attributes adaptively. The DIBD-D can discretize any continuous attribute adaptively according to the simple adaptive rules. The adaptive rule is based on maximal compound decrement and minimal dichotomic entropy.
4. Experimental Set-Up
In this section, we conduct experiments to evaluate the performances of the associative classification systems. For the comparative performance analysis of the selective associative classifiers, we exploited the implementations of these algorithms included in Knowledge Extraction based on Evolutionary Learning (KEEL) [18]. The overview of the Data Mining and machine learning tool KEEL is given in the following section. In this section, we describe the datasets used for the comparative analysis of the associative classifier (CBA) and CBA2 in terms of accuracy and error rate by using the different discretizing methods. The parameters set for the experiments and the experiment graph designed for these experiments in the KEEL tool are described in this section.
4.1. Data Sets
The description of datasets used for the comparative performance analysis of the selective Associative Classifiers under this study is given in Table2. The number of attributes (#Attributes), number of instances in the database (#Examples) and thenumber of classes (#Classes) are shown in the table. The missing values (Missing_V) in the dataset are representing by “Yes” (missing values present)/ “No” (missing values not present). The missing values of the datasets are imputed with the KMean-MV module implemented in KEEL. The datasets are discretized with the Ameva-D module included in KEEL as the associative classifiers accept the discretized form of datasets. We use the 10-fold cross-validation model for the datasets provided in KEEL. Table I summarizes the main characteristics of the 12 datasets which are given at Knowledge Extraction based on Evolutionary Learning (KEEL)-dataset repository[18].
Table 1 Data Sets Considered For The Experimental Stu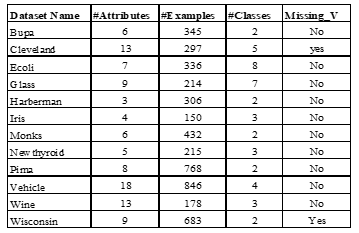
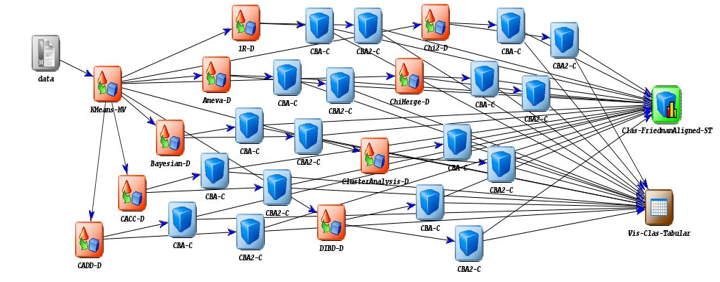
4.2. Experiment Graph
The experiment graph shows the components of the experiment and describes the relationships between them. The experimental graph of the comparative study is given in Figure1. The first component of the experimental graph is data which enables to select the datasets given in the KEEL Tool as well as to load user datasets. In our study, we selected standard KEEL datasets. The second component of the graph is KMeans-MV which is a module to impute the missing values in the database. The third component of the experiment graph is amodule for data discretization. In our case, we use the selective nine modules i.e.1R-D, Ameva-D, Bayesian-D, CACC-D, CADD-D, DIBD-D, ClusterAnalysis-D, ChiMerge-D and Chi2-D for the discretization of continuous data values. The fourth stage of the experiment graph is Associative Classification methods (CBA and CBA2) which are the focus of our study. The last stage of the experiment graph is the modules for the representation of the results of theclassifier and astatistical module for the analysis of the results produced by the algorithms used in the experiment. The module Vis-Class-Tabular provides the facility of representation of results of multiple classification methods in the form tabular representation.
4.3. Parameters of the Methods
The parameters of the associative classifiers (CBA and CBA2) under the focus of this comparative study are shown in the Tabel.2. The parameters of the method are selected according to the recommendation of the corresponding authors which are the default parameters settings included in the KEEL software tool [18]. In the Table 2,Minsup stands for minimum support, Minconf for minimum confidence, and RuleLimit for maximum candidate rules limit in the corresponding method.
Table 2 Parameters of the Methods for Experiment
| Methods | Parameters |
| CBA-C |
Minsup = 0.01, Minconf = 0.5, Pruned = yes, RuleLimit = 80,000 |
| CBA2-C |
Minsup = 0.01, Minconf = 0.5, Pruned = yes, RuleLimit = 80,000 |
5. Experimental Results
Table3 shows the comparative performance of the selected Associative Classifiers. We use the implementation of the corresponding algorithms in KEEL 3.0 for our comparative performance analysis of various discretizing methods by using CBA and CBA2 Associative Classifiers on the public datasets. We used the selective 9 discretization methods i.e 1R-D, Ameva-D, Bayesian-D, CACC-D, CADD-D, DIBD-D, ClusterAnalysis-D, ChiMerge-D and Chi2-D for this comparative study. The performance of both Associative Classifiers CBA and CBA2 is investigated on 12 public datasets for 9 discretizing methods. In table 3, the fold face red values show the best performance of CBA classifier for a specific dataset at a particular discretizing method with respect to other discretizing methods under the focus of this study. The fold face blue values in table 3 represents the best performance of the CBA2 classifier on a specific dataset with the exploitation of a specific discretizing method with respect to other discretizing methods. The last row of table 3 shows the average performance of the corresponding classifier for all datasets for a specific discretizing method. Overall the best average performance of classifier for a specific increasing method is presented with bold face red and blue for CBA and CBA2 respectively in table 3.The performance of the CBA classifier is better on Ameva-D discretizing method as compare to other discretizing methods but the average performance is better on the ChiMerge-D. The performance of CBA2 is promising with ChiMerge-D discretizing method. The performance of each discretizing method varies with respect to change in the database. The values bold face shows the wining of the corresponding discretizing methods for the CBA and CBA2 on the corresponding datasets.
Table 3 The Comparative Performance Results Of Associative Classification Methods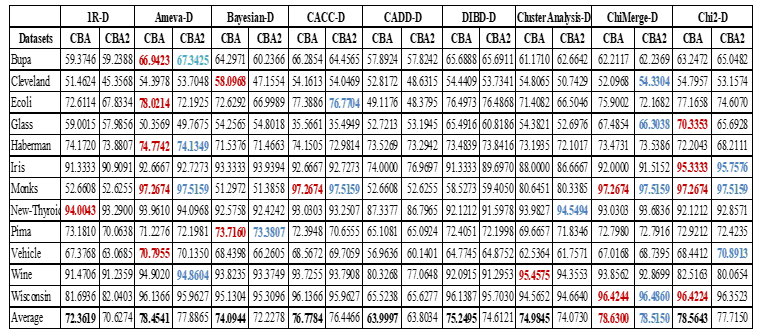
Table 4 Win/Draw/Lose Record of Discretization Methods for CBA and CBA2 Classifiers
Table 4 shows the comparative performance record of CBA and CBA2 in terms of Win/Draw/Lose of the Discretizing Methods. The 1R-D, Ameva-D, Bayesian-D, CACC-D, CADD-D, DIBD-D, ClusterAnalysis-D, ChiMerge-D, and Chi2-D. The performance of CBA classifier is better on Ameva-D and Chi2-D discretized. The performance of CBA2 remains same for Ameva-D and ChiMerge-D discretizing methods as shown in table 4.
6. Results Discussion
6.1. Comparative Performance Analysis in terms of Accuracy
Figure2 shows the comparative performance of the CBA and CBA2 on different discretizing methods for the selective datasets. With the critical observation of the graphs in figure 2, the performance behavior of CBA and CBA2 is symmetric in terms of accuracy for various discretizing methods. The performance of Associative Classifiers (CBA and CBA2) significantly changes with the change of discretizing method as shown in figure 2. The performance variation of CBA and CBA2 at datasets Glass, Monks, Ecoli and Wisconsin at the usage of different discrete methods is given in figure2. At the dataset Glass in figure 2, there is significant variation in performance of Associative Classifiers (CBA and CBA2). The performances of CBA and CBA2 are highest for Chi-D and lowest for CACC-D discretizing methods. The experiments for the dataset Ecoli shows that the performances of CBA and CBA2 lower significantly at the usage of CADD-D discretized while remaining almost same for the other discretizing methods. For dataset Monks in figure 2, the performances of Classifiers are drastically decreasing for 1R-D, Bayesian-D and CADD-D discretizing methods. The performance of CBA2 significantly decreased on dataset Haberman for Chi2-D discretizing method. Finally, the experimental results at Wine and Wisconsin datasets, reveals that the performances of CBA and CBA2 significantly down for the CADD-D discretized in terms of accuracy.
6.2. Comparative Performance Analysis in terms of Variance
This subsection describes the impact of discretizing methods on the performance of Associative Classifiers i.e. CBA and CBA2 in terms of variance on public datasets. The variance depicts the consistency of the classification approach. The lower value of the variance indicates that the classifier is more consistent for the corresponding dataset. The discretizing methods producing a smaller value of variance for a specific dataset for the specific classification approach are more promising and provide more robustness for the classifier. The variation of performance of Associative Classifiers in terms of variance is elaborated in Figure 3. The performance of both classifiers is almost same for the datasets Bupa and Cleveland for on all the discretizing methods.Variance is significantly high for Chi2-D and Ameva-D discretizing methods for CBA2 and CBA classifiers on datasets Bupa and Cleveland respectively. The performance associative classifiers (CBA and CBA2) for Iris, New-thyroid, Wine and Wisconsin datasets is very promising and consisting in terms of variance for all the discretizing methods except CADD-D, Chi2 and 1R-D. The variance is very high of CBA and CBA2 on Iris and New-thyroid for CADD-D discretizing method.
With the critical observation of Figure 3, it concluded there is a significant difference in the performance of associative classifiers in terms of variance as well as for the various discretizing methods on the pubic datasets under the focus of this study. Mostly of the discretizing methods produce promising results for some datasets while on the other datasets their performance is lower. The performance of classification approach significantly is dependent on the discetzing method used for the discretizing the continuous datasets in discrete form.
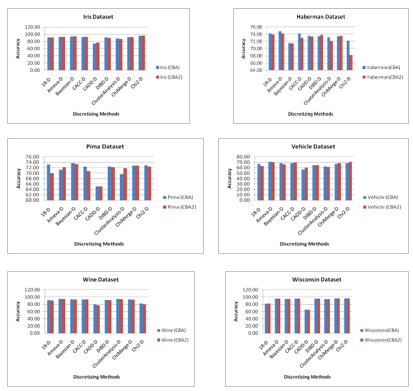
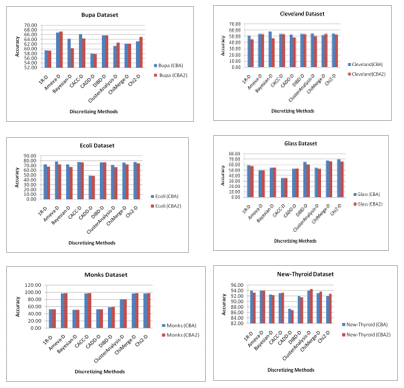
Figure 2 Impact of Discretization Methods on the Performance Associative Classifiers (CBA and CBA2) on Various Datasets 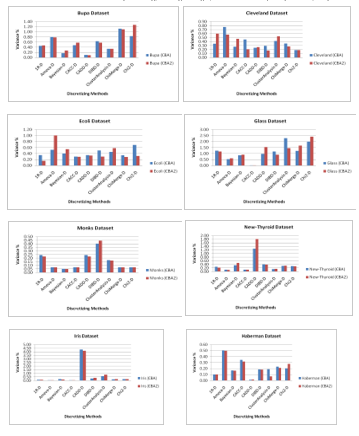
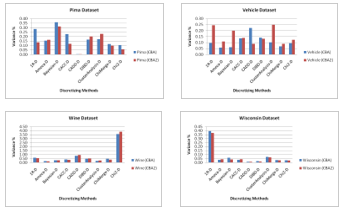
Figure 3 Comparative Impact of Discretizaing Methods on the Performance of Associative Classifiers (CBA and CBA2) in terms of Variance
7. Conclusion
Discretization algorithms have played a great role in the performance of classification techniques. We investigate the effect of discretization Methods on the Performance of Associative Classifiers. Most of the classification approaches work on the discretized databases. There are various approaches exploited for the discretization of the database to compare the performance of the classifiers. The selection of the discretization method influences the classification performance of the classification method. We compare the performance of associative classifiers namely CBA and CBA2 on the selective discretizing methods i.e. 1R-D, Ameva-D, Bayesian-D, CACC-D, CADD-D, DIBD-D, ClusterAnalysis-D, ChiMerge-D and Chi2-D in terms of accuracy and error rate. Our experimental results show that the performance of the Associative Classifiers significantly varies for different discretization methods for the same classifier. So the accuracy rate and variance in results of the classifier is highly dependent on the choice of the discretization method. For this comparative performance study, we use the implementation of these methods in KEEL data mining tool on public datasets.
In future, we will analyse the impact of discretizing methods for other classifiers by considering other parameters and to derive the significance of results by using statistical methods.
Conflict of Interest
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
The authors wish to thanks Higher Education Commission of Pakistan. This work is supported in part by a grant from Higher Education Commission of Pakistan.
- Ali, Z. and W. Shahzad. Comparative Study of Discretization Methods on the Performance of Associative Classifiers. in Frontiers of Information Technology (FIT), 2016 International Conference on. 2016. IEEE.
- Thabtah, F., A review of associative classification mining. The Knowledge Engineering Review, 2007. 22(01): p. 37-65.
- Vyas, R., et al. Associative classifiers for predictive analytics: Comparative performance study. in Computer Modeling and Simulation, 2008. EMS’08. Second UKSIM European Symposium on. 2008. IEEE.
- Soni, S. and O. Vyas, Using associative classifiers for predictive analysis in health care data mining. International Journal of Computer Applications, 2010. 4(5): p. 33-37.
- Liu, H., et al., Discretization: An enabling technique. Data mining and knowledge discovery, 2002. 6(4): p. 393-423.
- Kotsiantis, S. and D. Kanellopoulos, Discretization techniques: A recent survey. GESTS International Transactions on Computer Science and Engineering, 2006. 32(1): p. 47-58.
- Garcia, S., et al., A survey of discretization techniques: Taxonomy and empirical analysis in supervised learning. IEEE Transactions on Knowledge and Data Engineering, 2013. 25(4): p. 734-750.
- Pancho, D.P., et al. Analyzing fuzzy association rules with Fingrams in KEEL. in 2014 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE). 2014. IEEE.
- Holte, R.C., Very simple classification rules perform well on most commonly used datasets. Machine learning, 1993. 11(1): p. 63-90.
- Gonzalez-Abril, L., et al., Ameva: An autonomous discretization algorithm. Expert Systems with Applications, 2009. 36(3): p. 5327-5332.
- Wu, X., A Bayesian discretizer for real-valued attributes. The Computer Journal, 1996. 39(8): p. 688-691.
- Tsai, C.-J., C.-I. Lee, and W.-P. Yang, A discretization algorithm based on class-attribute contingency coefficient. Information Sciences, 2008. 178(3): p. 714-731.
- Ching, J.Y., A.K.C. Wong, and K.C.C. Chan, Class-dependent discretization for inductive learning from continuous and mixed-mode data. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1995. 17(7): p. 641-651.
- Wu, Q., et al., A distribution-index-based discretizer for decision-making with symbolic ai approaches. IEEE transactions on knowledge and data engineering, 2007. 19(1): p. 17-28.
- Chmielewski, M.R. and J.W. Grzymala-Busse, Global discretization of continuous attributes as preprocessing for machine learning. International journal of approximate reasoning, 1996. 15(4): p. 319-331.
- Kerber, R. Chimerge: Discretization of numeric attributes. in Proceedings of the tenth national conference on Artificial intelligence. 1992. Aaai Press.
- Liu, H. and R. Setiono, Feature selection via discretization. IEEE Transactions on knowledge and Data Engineering, 1997. 9(4): p. 642-645.
- Alcalá, J., et al., Keel data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. Journal of Multiple-Valued Logic and Soft Computing, 2010. 17(2-3): p. 255-287.
- Ma, B.L.W.H.Y. and B. Liu. Integrating classification and association rule mining. in Proceedings of the 4th. 1998.
- Agrawal, R. and R. Srikant. Fast algorithms for mining association rules. in Proc. 20th int. conf. very large data bases, VLDB. 1994.
- Liu, B., Y. Ma, and C.-K. Wong, Classification using association rules: weaknesses and enhancements. Data mining for scientific applications, 2001. 591.
- Salzberg, S.L., C4. 5: Programs for machine learning by j. ross quinlan. morgan kaufmann publishers, inc., 1993. Machine Learning, 1994. 16(3): p. 235-240.
- Kurgan, L.A. and K.J. Cios, CAIM discretization algorithm. IEEE transactions on Knowledge and Data Engineering, 2004. 16(2): p. 145-153.